
세션을 시작하며
안녕하세요, 오늘 이 세션에 오신 걸 환영합니다. 오픈소스 모델을 실제 프로덕션까지 어떻게 가져가는지 함께 이야기해 보겠습니다.

오늘 주제는 Build with Hugging Face on Microsoft Foundry입니다. 오픈소스 모델을 프로덕션에서 돌린다는 게 어떤 의미인지, DEM320 세션에서 제대로 풀어보겠습니다.

먼저 Foundry Managed Compute가 무엇인지 보고, 왜 오픈 모델로 빌드하는지, Hugging Face 소개, 그리고 Foundry 위에서 Hugging Face를 쓰는 이유와 방법까지 살펴본 다음 마지막에 데모로 마무리하겠습니다.

자, 그럼 첫 번째로 Foundry Managed Compute가 정확히 무엇인지부터 짚어보겠습니다.

관리형 GPU 컴퓨트 플랫폼
Managed Compute는 Microsoft Foundry 안에 들어온 관리형 GPU 컴퓨트 플랫폼입니다. VM이나 클러스터, 인프라를 직접 관리하지 않고도 오픈소스 모델을 전용 GPU 위에 배포하고 커스터마이즈하고 확장할 수 있죠. 기존의 Pay-per-token, PTU에 이어 OSS 모델을 위한 새로운 배포 방식이라고 보시면 됩니다.
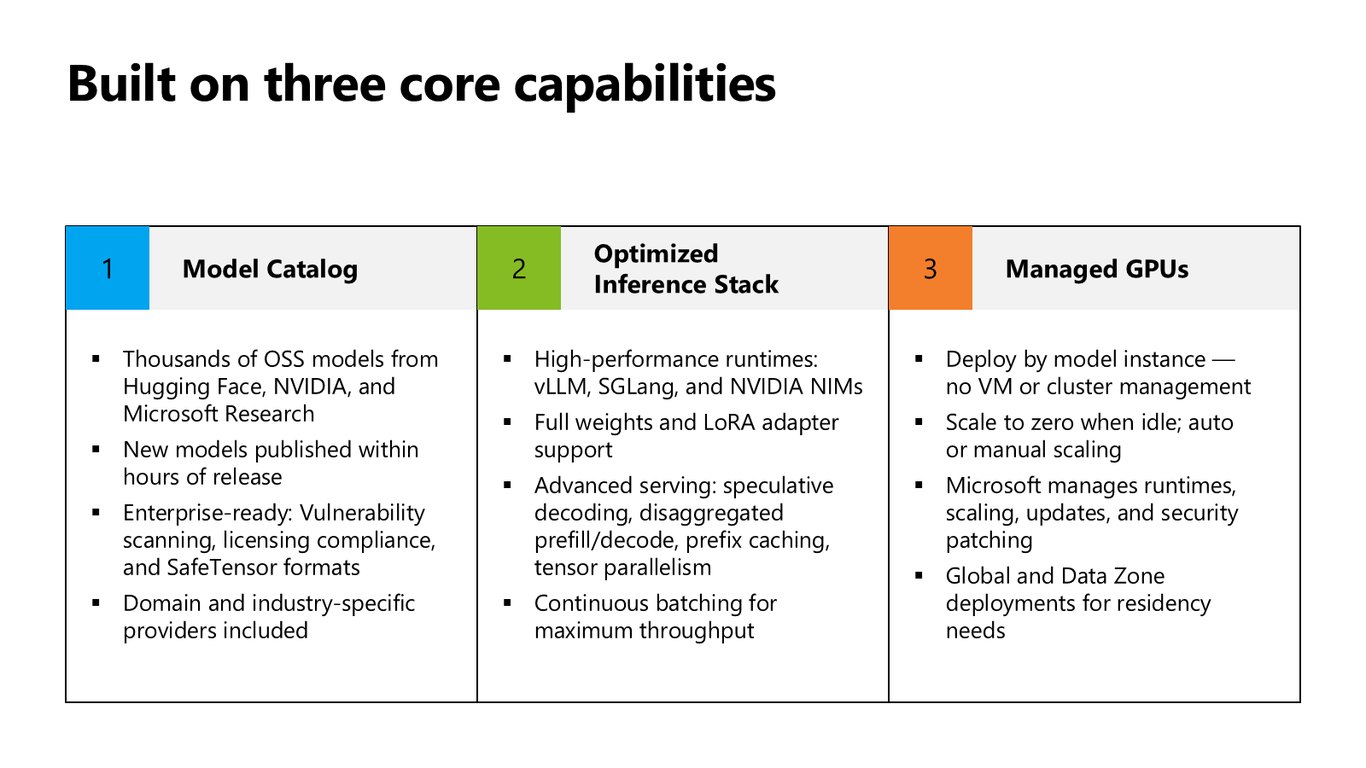
세 가지 핵심 역량
크게 세 축으로 구성됩니다. Hugging Face·NVIDIA·Microsoft Research의 수천 개 모델을 담은 Model Catalog, vLLM·SGLang·NVIDIA NIM 같은 최적화된 Inference Stack, 그리고 VM 관리 없이 모델 단위로 배포하고 유휴 시 scale to zero까지 되는 Managed GPU입니다. 런타임과 확장, 보안 패치는 Microsoft가 대신 맡습니다.
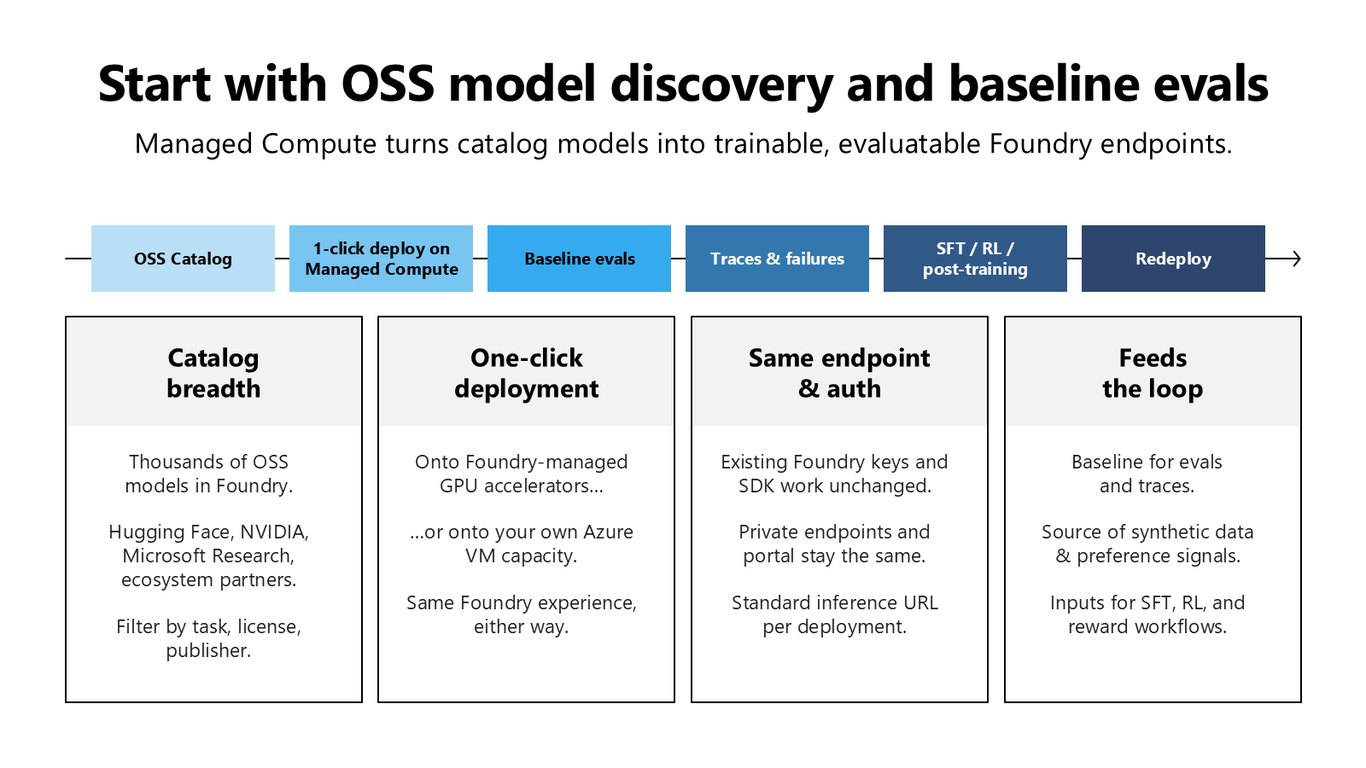
모델 발견과 베이스라인 평가부터
중요한 변화는 포스트 트레이닝이 첫 학습 잡보다 먼저 시작된다는 겁니다. 팀은 우선 올바른 OSS 베이스라인 모델을 찾아 자기 워크플로에 맞춰 평가하고 빠르게 운영해봐야 하는데요. 카탈로그에서 모델을 골라 원클릭으로 배포하면 바로 eval과 trace를 모으기 시작할 수 있고, 그게 다시 SFT와 RL로 이어지는 루프가 됩니다.
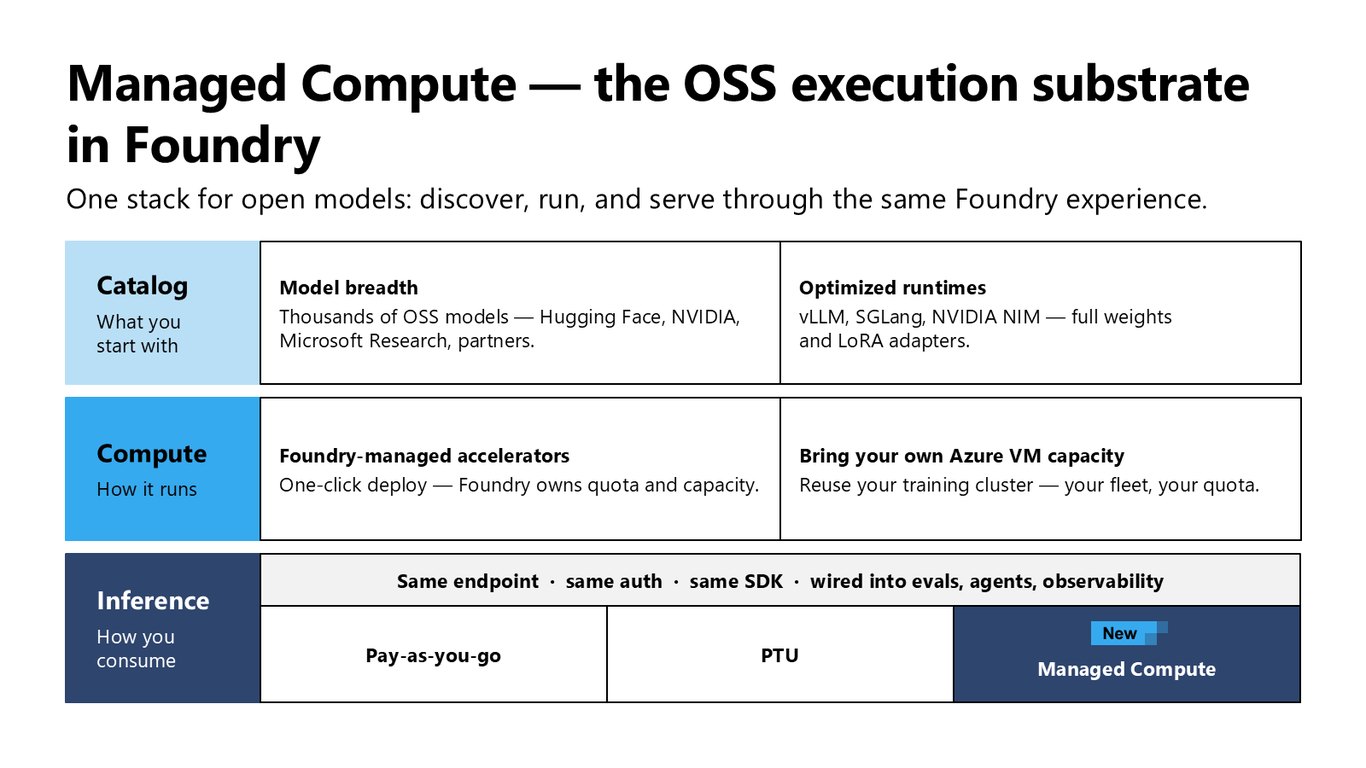
하나의 스택, 세 개의 계층
세 계층이지만 결국 하나의 스택입니다. Catalog에는 최적화 런타임이 붙은 수천 개 OSS 모델이 있고, Compute는 Foundry 관리형 GPU에 원클릭으로 올리거나 이미 쓰던 Azure VM 용량을 그대로 가져올 수 있습니다. 그리고 핵심은, 그 위의 Inference 경험이 개발자들이 이미 쓰는 것과 완전히 동일하다는 점입니다. 같은 엔드포인트, 같은 인증, 같은 SDK죠.
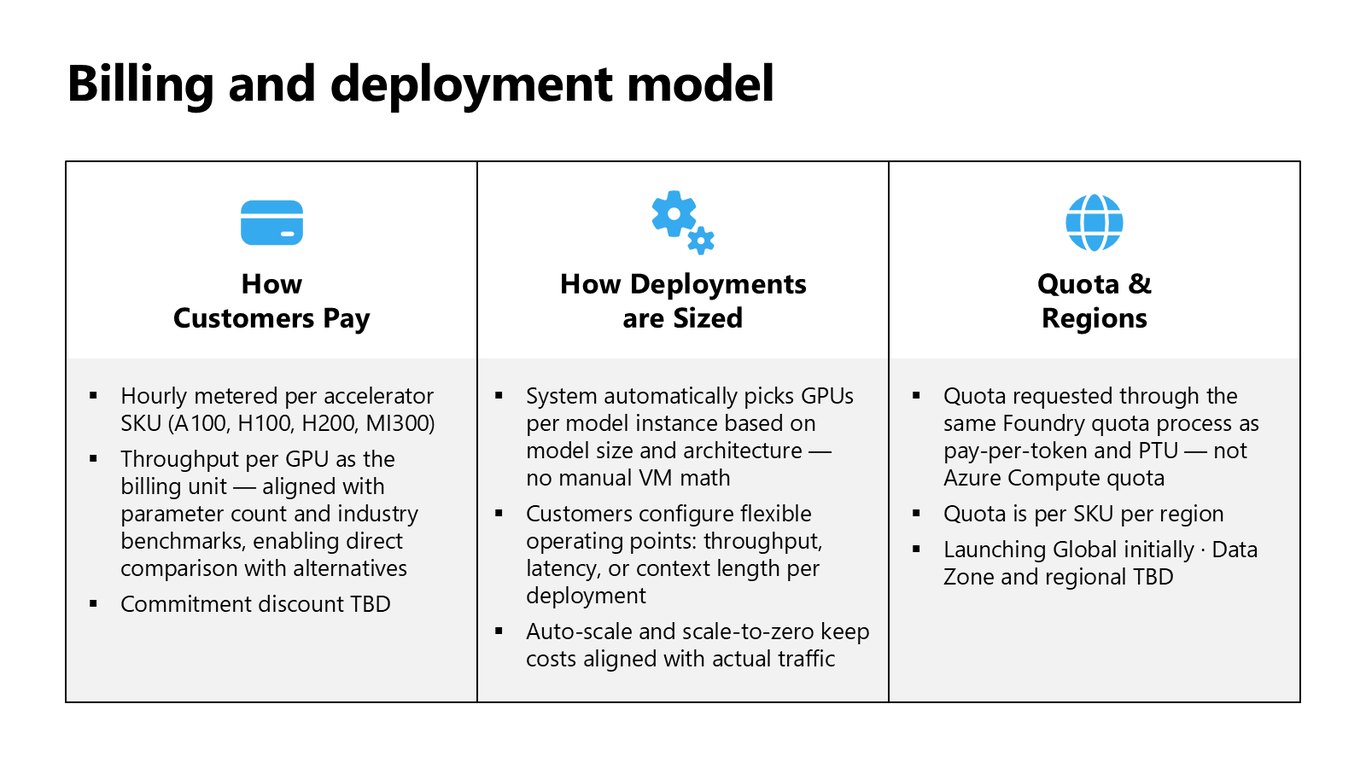
과금과 배포 모델
과금은 A100, H100, H200, MI300 같은 가속기 SKU별로 시간당 측정되고, GPU당 처리량을 단위로 삼아 대안들과 바로 비교할 수 있게 했습니다. 배포 크기는 시스템이 모델 규모에 맞춰 GPU를 자동으로 골라주고, 쿼터는 Azure Compute가 아니라 Foundry 쿼터 프로세스로 SKU·리전 단위로 요청합니다. 처음에는 Global로 시작합니다.

커스텀 모델을 올리는 방법
이제 커스텀 모델을 Foundry가 어떻게 받아들이는지 멘탈 모델을 잡아보죠. 네 계층입니다. 소스는 노트북·스토리지·학습 잡·Hugging Face에서 가져오고, 포맷은 full weights 또는 hot-swap 가능한 LoRA 어댑터, 자산은 BYOW냐 BYOC냐, 마지막으로 컴퓨트는 Managed Compute나 여러분의 학습 클러스터, 또는 Fireworks PTU입니다.

BYOW vs BYOC
한 장에 두 경로입니다. Weights를 올리는 01단계와 Foundry 엔드포인트로 소비하는 04단계는 두 경로가 완전히 동일합니다. 차이는 가운데뿐이죠. BYOW는 카탈로그 베이스 모델을 고르면 Foundry가 서빙 런타임을 매핑해 주고, BYOC는 직접 만든 이미지를 등록합니다. BYOC는 멀티테넌트 격리 때문에 반드시 여러분의 클러스터 위에서 돌아갑니다.

이제 관점을 바꿔서, 그럼 왜 굳이 오픈 모델로 빌드하는가를 이야기해 보겠습니다.
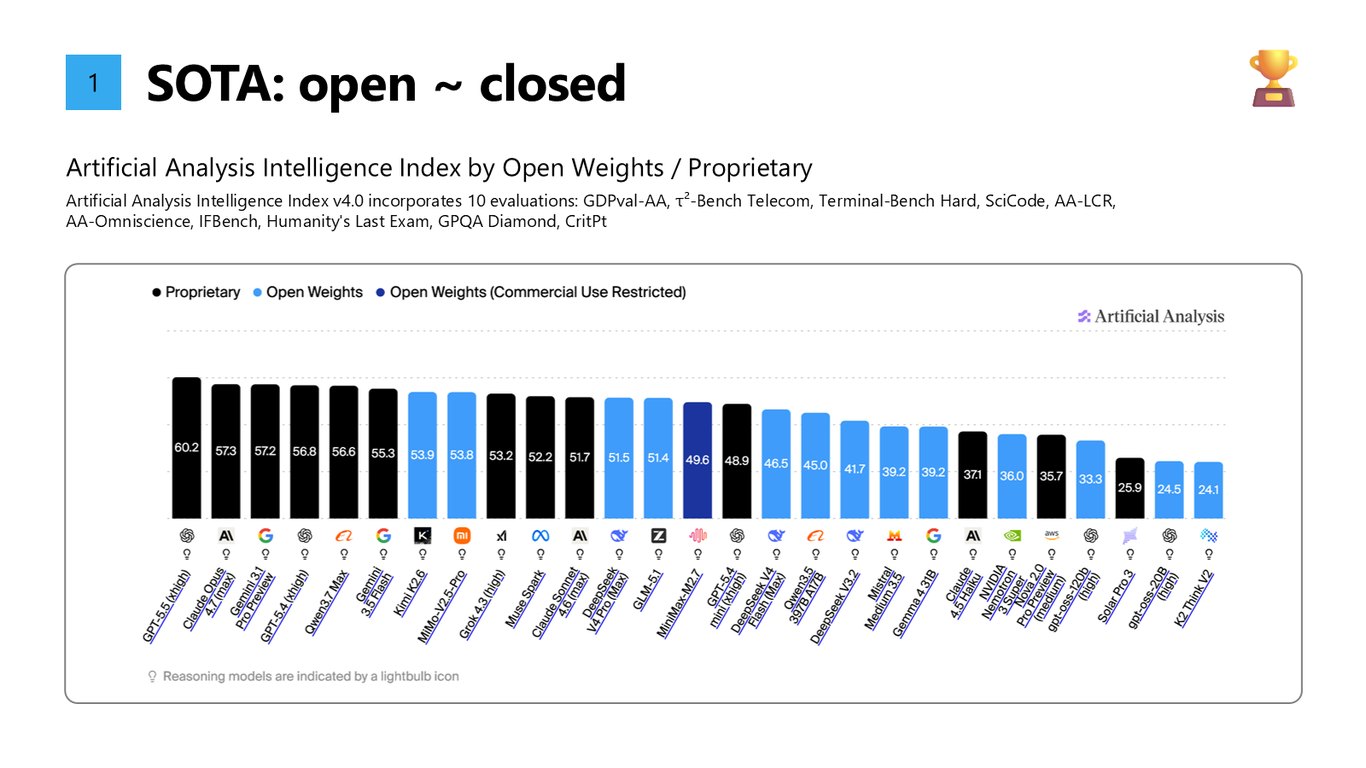
오픈이 클로즈드를 따라잡았다
첫째, 성능입니다. Artificial Analysis Intelligence Index를 보면 오픈 웨이트 모델이 이제 독점 모델과 거의 같은 수준까지 올라왔습니다. SOTA에서 오픈과 클로즈드의 격차가 사실상 사라진 거죠.
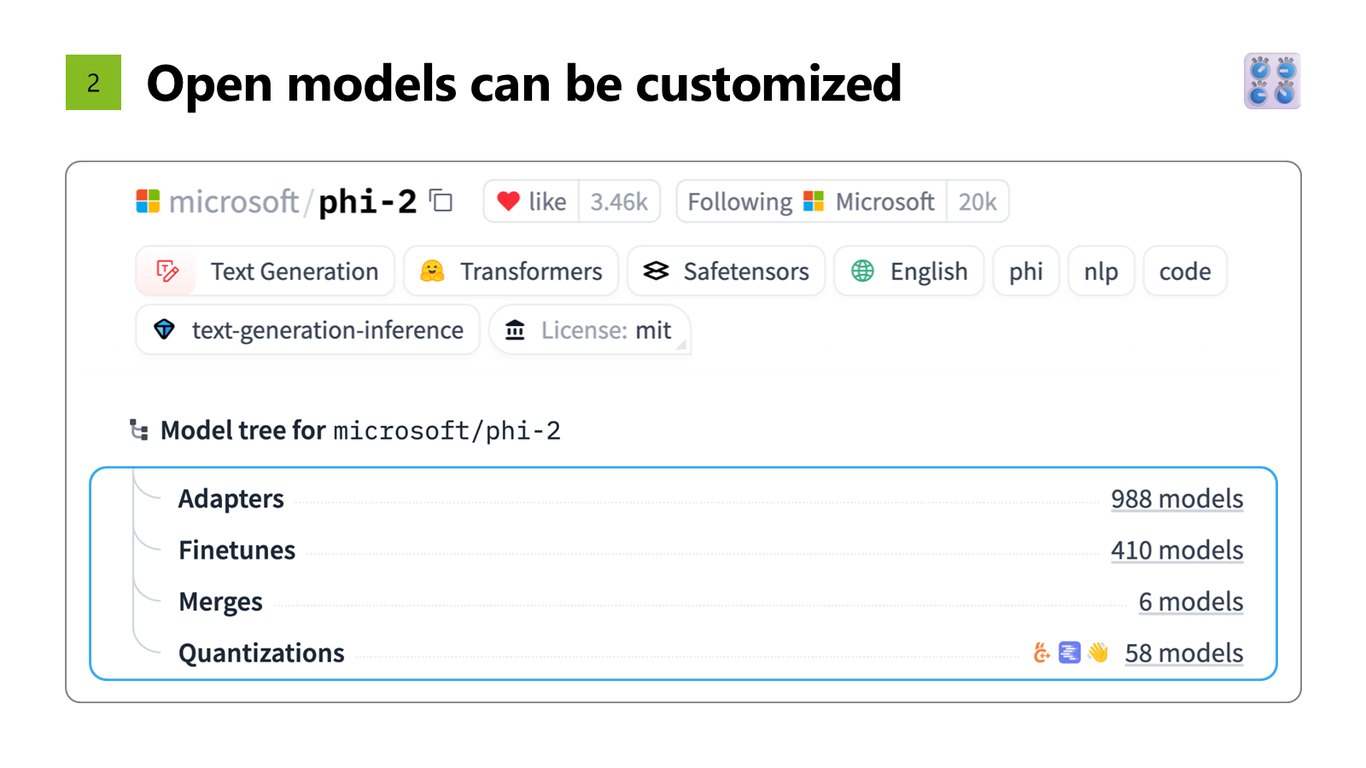
커스터마이즈가 자유롭다
둘째, 오픈 모델은 여러분이 원하는 대로 커스터마이즈할 수 있습니다. 파인튜닝이든 어댑터든, 우리 데이터와 워크플로에 맞게 모델을 손볼 수 있다는 게 큰 강점입니다.
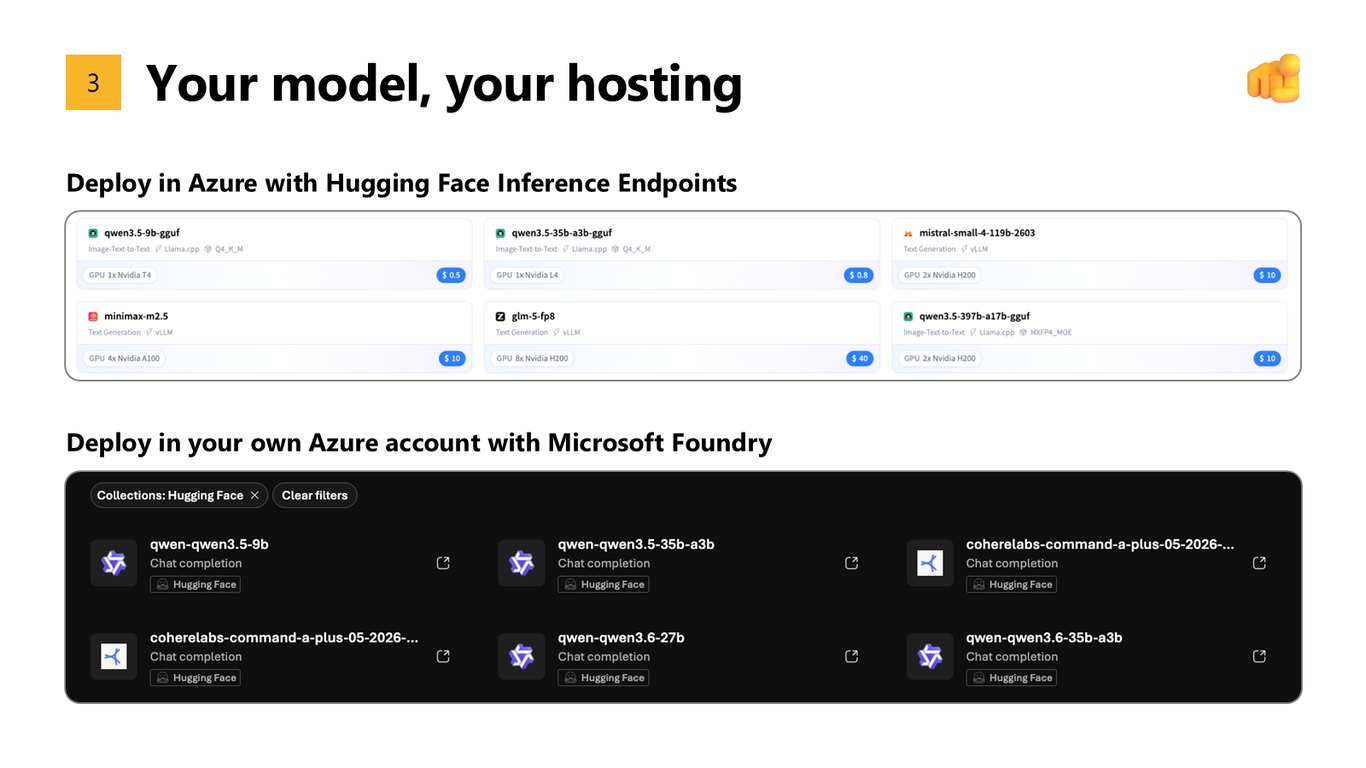
내 모델, 내 호스팅
셋째, 호스팅을 내가 통제합니다. Hugging Face Inference Endpoints로 Azure에 배포하거나, Microsoft Foundry로 여러분 자신의 Azure 계정 안에 배포할 수 있습니다.

AI 비용을 통제한다
넷째, 비용입니다. 예를 들어 Granite Docling은 258M 파라미터에 불과하죠. 작업에 딱 맞는 작은 모델을 쓰면 AI 비용을 훨씬 촘촘하게 통제할 수 있습니다.
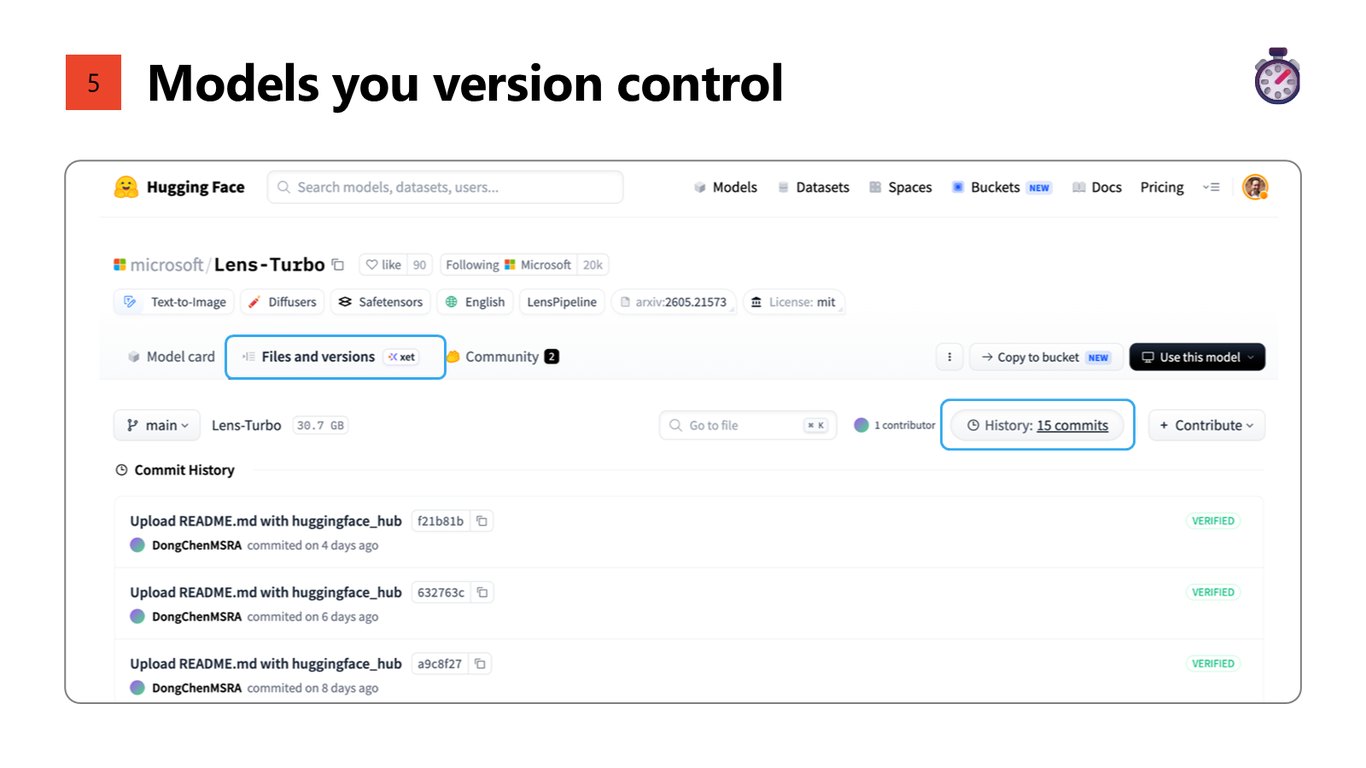
버전 관리가 되는 모델
다섯째, 버전 관리입니다. 오픈 모델은 어떤 버전을 쓰는지 정확히 고정하고 추적할 수 있어서, 어느 날 갑자기 모델이 바뀌어 있는 일이 없습니다.
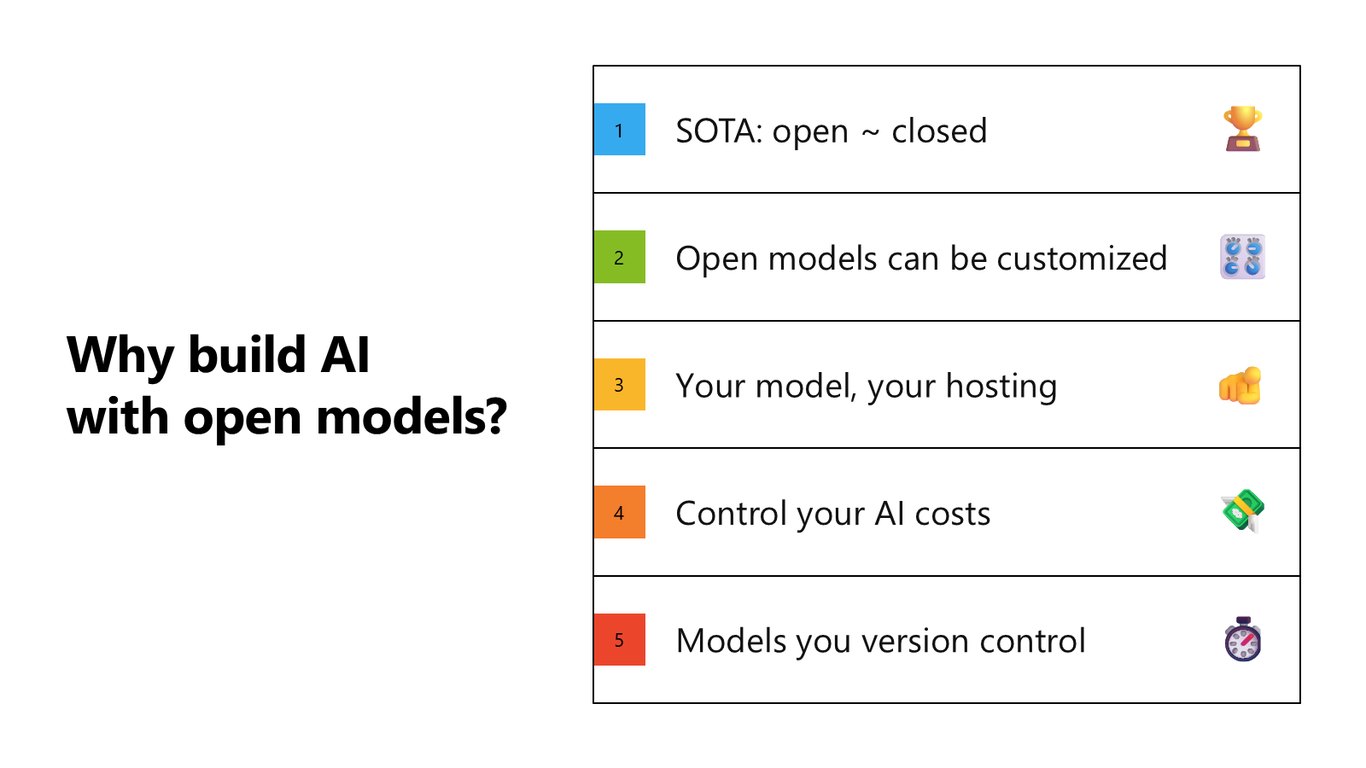
다섯 가지 이유 정리
정리하면 오픈 모델로 빌드하는 이유는 다섯 가지입니다. 오픈이 클로즈드 수준의 성능에 도달했고, 커스터마이즈가 자유롭고, 호스팅을 내가 통제하고, 비용을 아끼고, 버전까지 관리할 수 있다는 것이죠.

그럼 이 오픈 생태계의 중심에 있는 Hugging Face를 잠깐 소개하겠습니다.
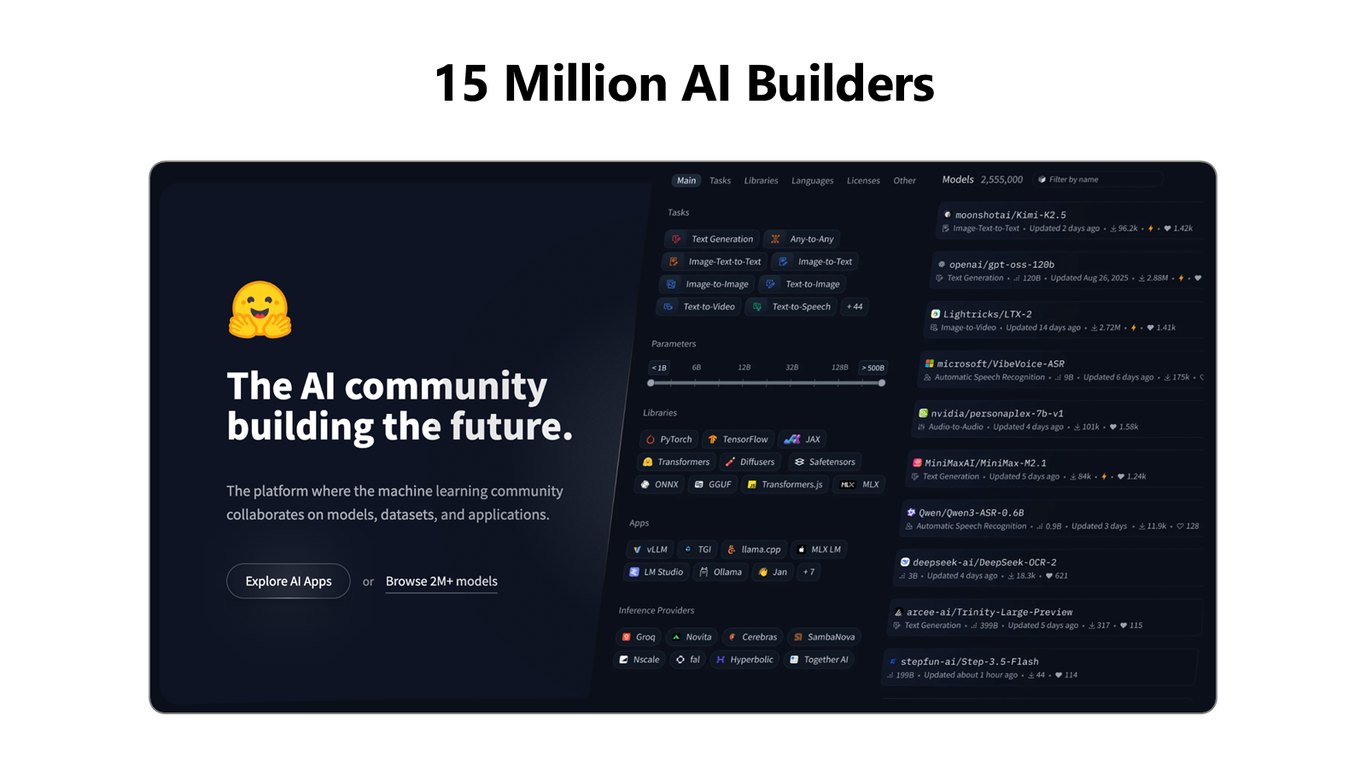
1,500만 명의 AI 빌더
먼저 규모부터 보시죠. 전 세계 1,500만 명의 AI 빌더가 Hugging Face에서 모델을 만들고 공유하고 있습니다.

40만 개 조직
그리고 40만 개가 넘는 조직이 여기서 활동하고 있습니다. 개인 개발자부터 대기업까지 모두 모여 있는 셈이죠.
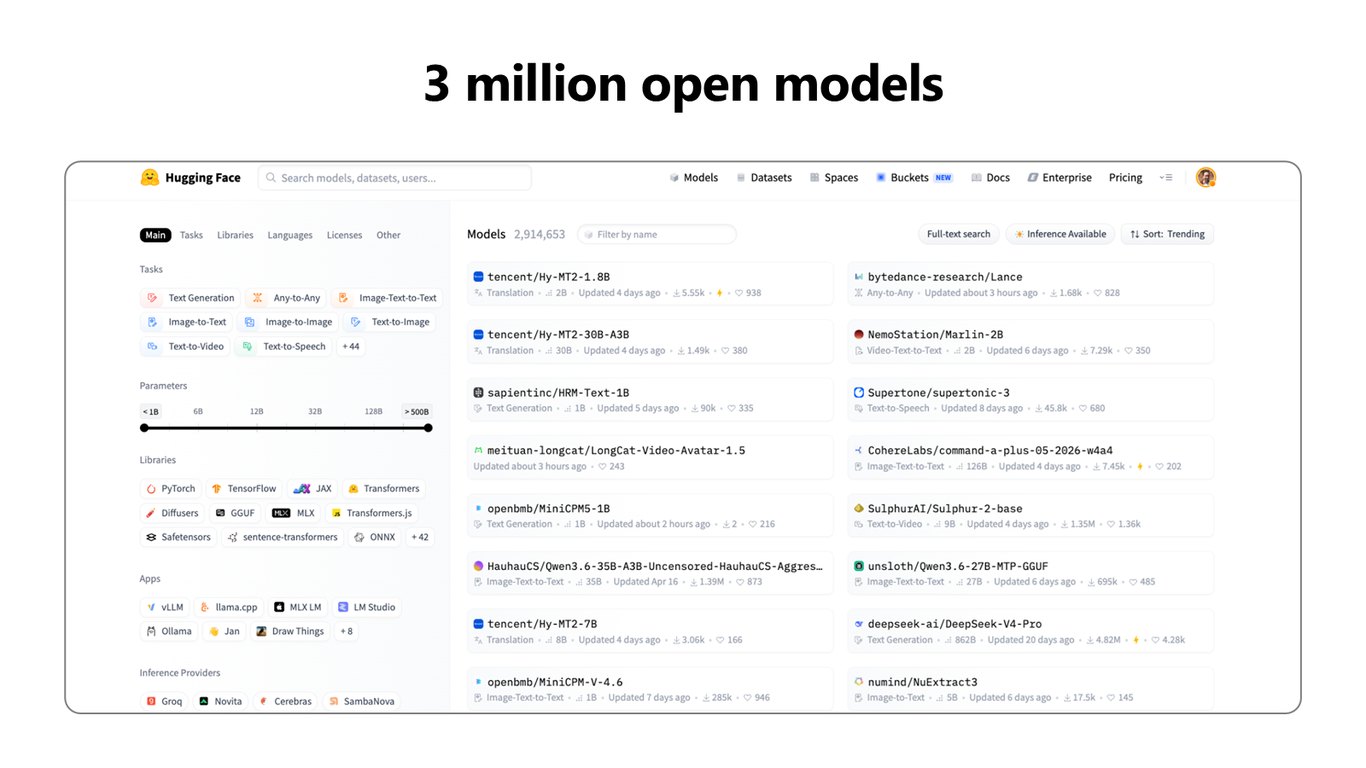
300만 개 오픈 모델
공개된 오픈 모델만 300만 개에 달합니다. 사실상 세계 최대의 오픈 모델 저장소라고 할 수 있습니다.

오픈소스로 AI를 만든다
한마디로 Hugging Face는 오픈소스로 AI를 만드는 곳입니다. 이 거대한 생태계를 이제 Foundry 위에서 그대로 활용할 수 있습니다.

그렇다면 왜 Microsoft Foundry 위에서 Hugging Face를 써야 하는지, 그 이유를 살펴보겠습니다.

최신 오픈 모델을 안전한 환경에서
agentic coding, 비디오 세그멘테이션, 음성, 임베딩 같은 새로운 프런티어 역량이 매주 Hugging Face에 올라옵니다. Microsoft Foundry는 이 오픈 생태계를 Azure 위의 안전하고 프로덕션 레디한 경험으로 가져옵니다. 보안 검사된 웨이트, 최적화 런타임, 관리형 엔드포인트로요. 이제 Managed Compute로 배포가 그 어느 때보다 쉬워졌습니다.

Foundry의 Hugging Face 컬렉션
현재 약 11,000개 모델이 Foundry의 Hugging Face 컬렉션에 올라와 있고, 매일 트렌딩 모델이 추가됩니다. Safetensors만, 원격 코드 없이, 보안 스캔을 거치고요. 텍스트·비전·오디오 등 모든 모달리티를 다루고, 모델마다 vLLM·SGLang·TEI·llama.cpp 중 가장 좋은 엔진을 붙여줍니다.

Managed Compute로 더 쉽게
게다가 이제 Foundry Managed Compute와 함께 쓸 수 있습니다. A100, H100, MI300X 중 가속기만 고르면 되고, Foundry 전용 쿼터로 GPU 확보가 쉬우며, 레플리카 수만 설정하면 자동 프로비저닝과 확장이 됩니다.

이제 실제로 Foundry 위에서 Hugging Face 모델을 어떻게 빌드하는지, 단계별로 보여드리겠습니다.
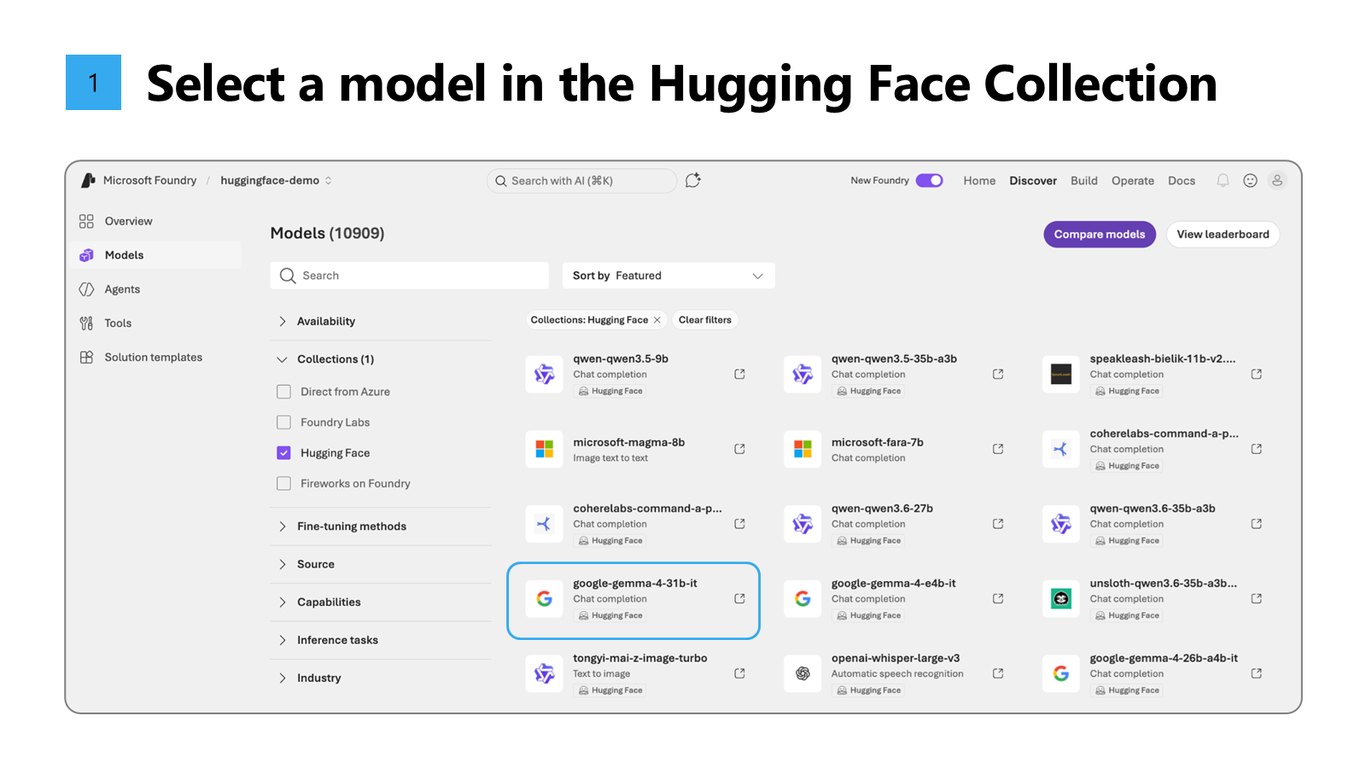
1. 모델 선택
첫 번째, Hugging Face 컬렉션에서 원하는 모델을 고릅니다.
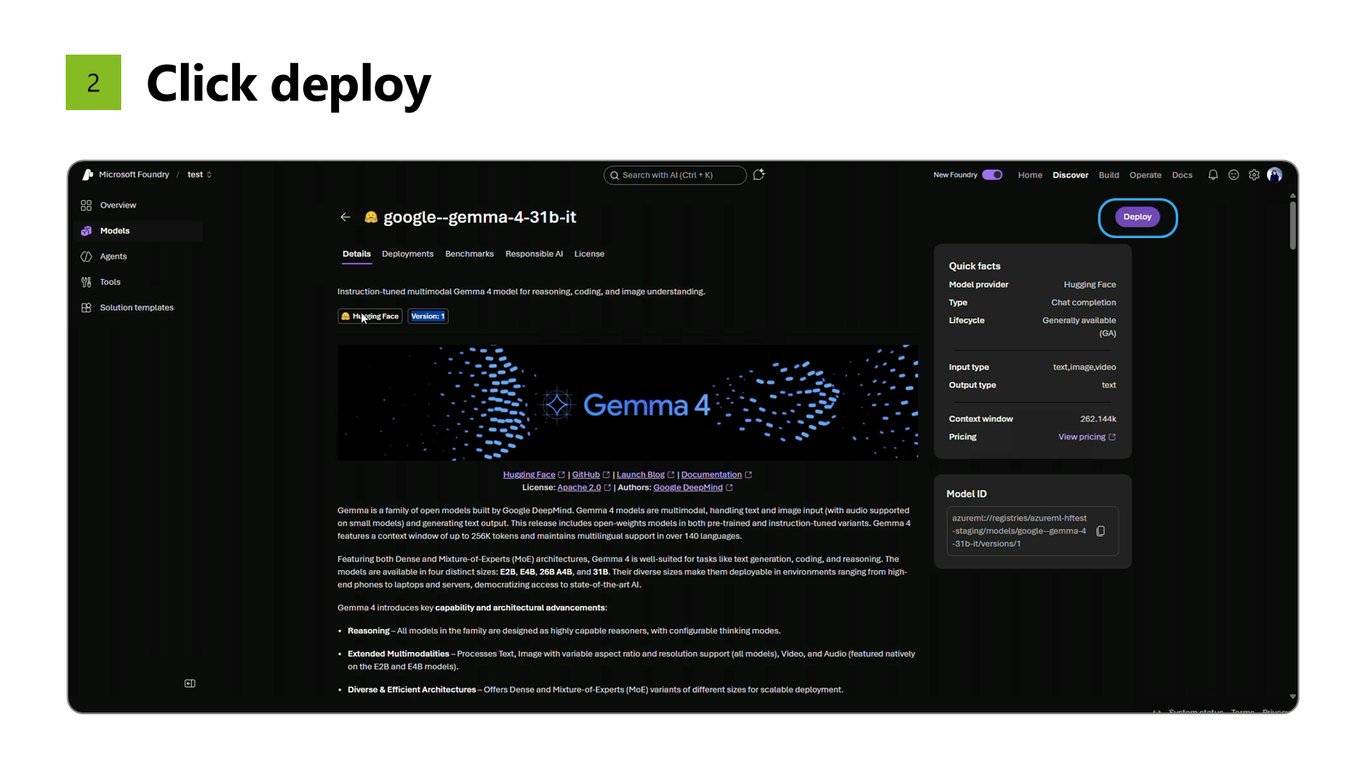
2. Deploy 클릭
두 번째, Deploy 버튼을 누릅니다. 정말 이게 끝입니다.
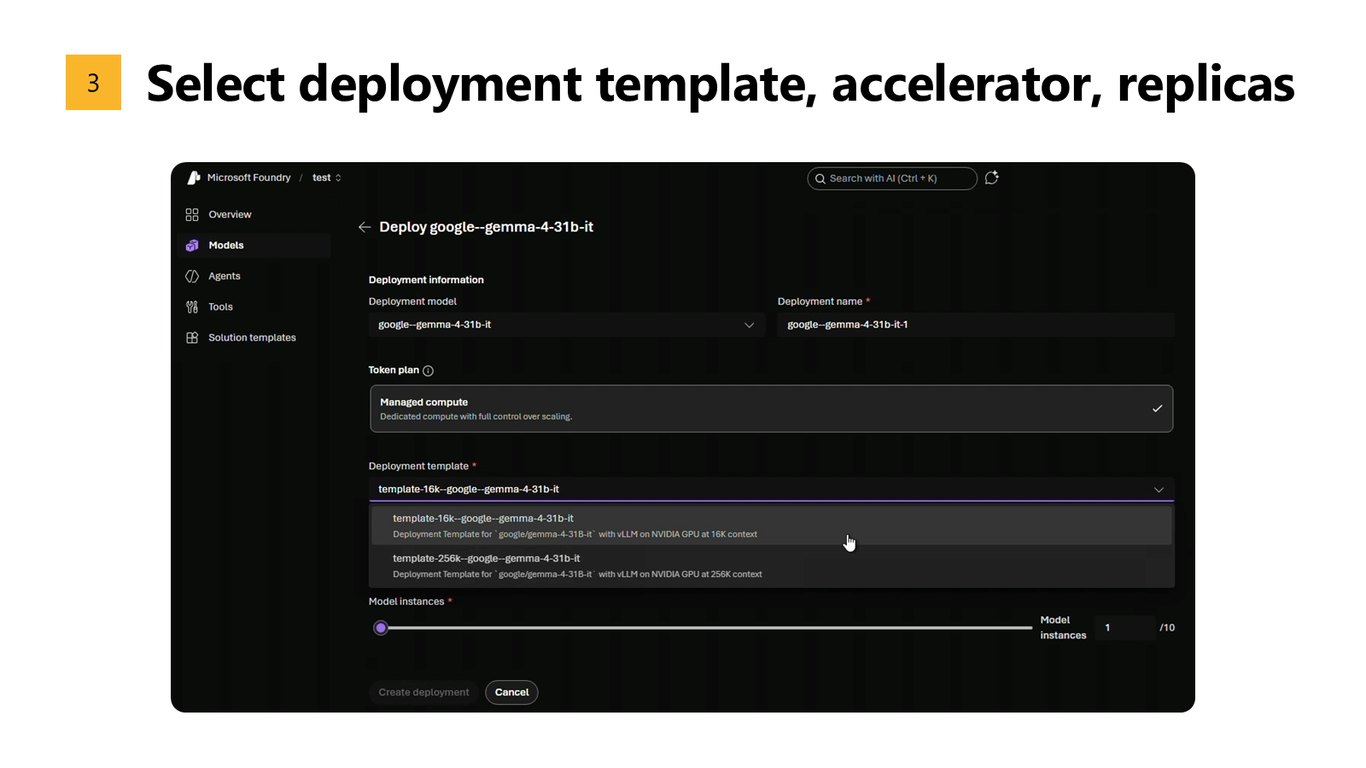
3. 템플릿·가속기·레플리카 설정
세 번째, 배포 템플릿과 가속기, 그리고 레플리카 수를 선택합니다. VM 계산 같은 건 할 필요가 없죠.
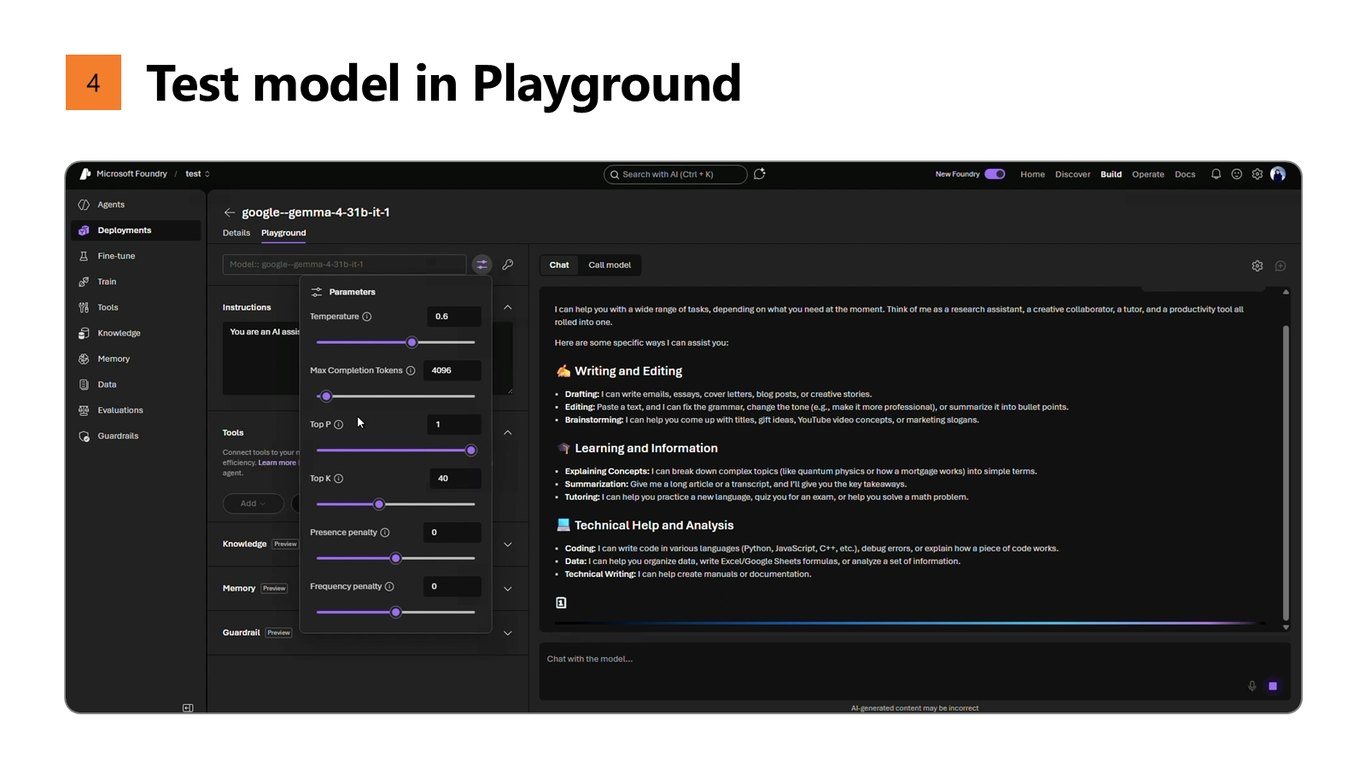
4. Playground에서 테스트
네 번째, Playground에서 모델을 바로 테스트해봅니다. 배포된 모델이 잘 동작하는지 즉시 확인할 수 있습니다.
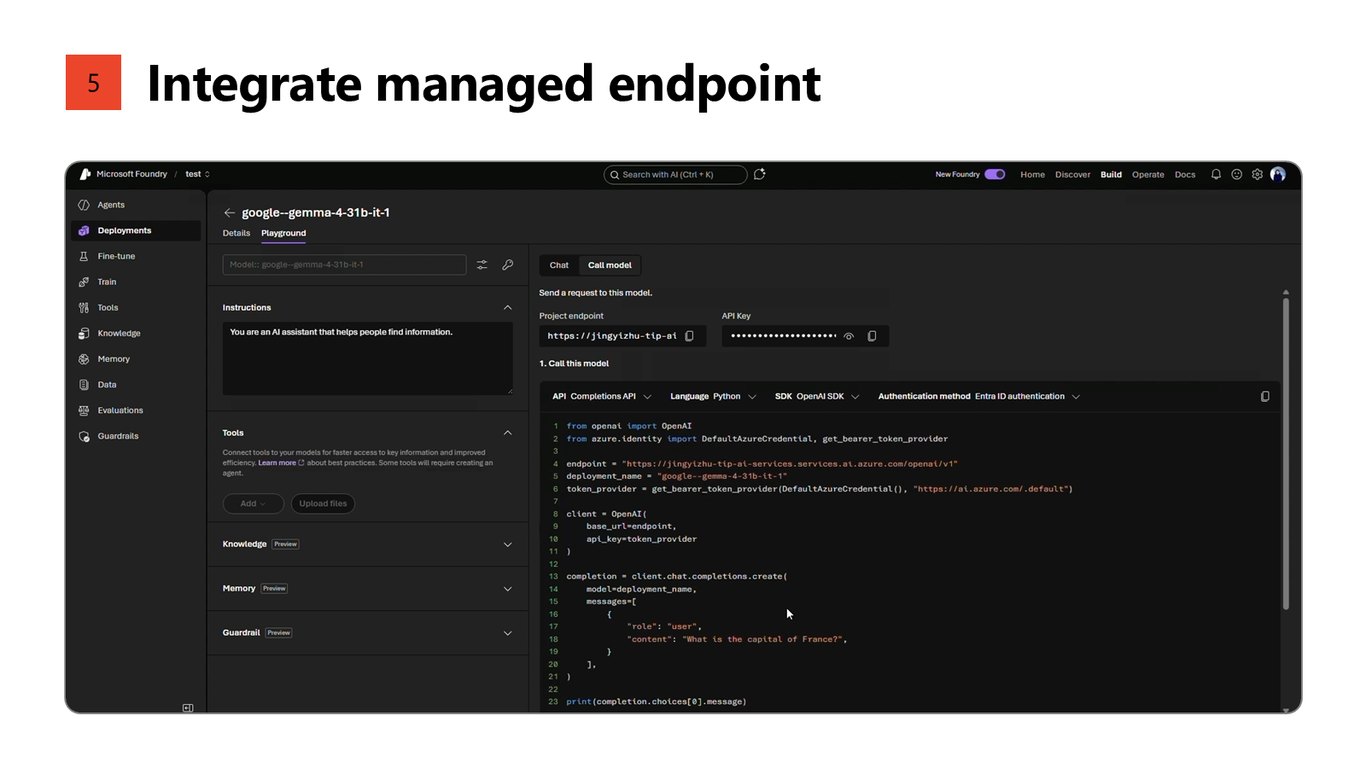
5. 관리형 엔드포인트 통합
다섯 번째, 관리형 엔드포인트를 여러분의 애플리케이션에 통합합니다. 기존 Foundry 키와 SDK가 그대로 동작하니 코드 변경이 거의 없습니다.

자, 그럼 말로만 하지 말고 실제로 보여드리죠. 지금부터 데모를 시작하겠습니다.

감사합니다
들어주셔서 감사합니다. 질문 있으시면 지금 편하게 나눠보시죠.