
안녕하세요. 오늘은 Foundry에서 오픈소스 추론 모델을 후처리 학습하고 배포해서, 개선의 루프를 어떻게 닫는지 이야기해 보겠습니다. 저는 Chris Lauren, 그리고 Vijay Aski와 함께합니다. 세션을 편하게 들으실 수 있도록 제공된 헤드셋을 리시버에 연결해 주시고, 나가실 때 반납 부탁드립니다.
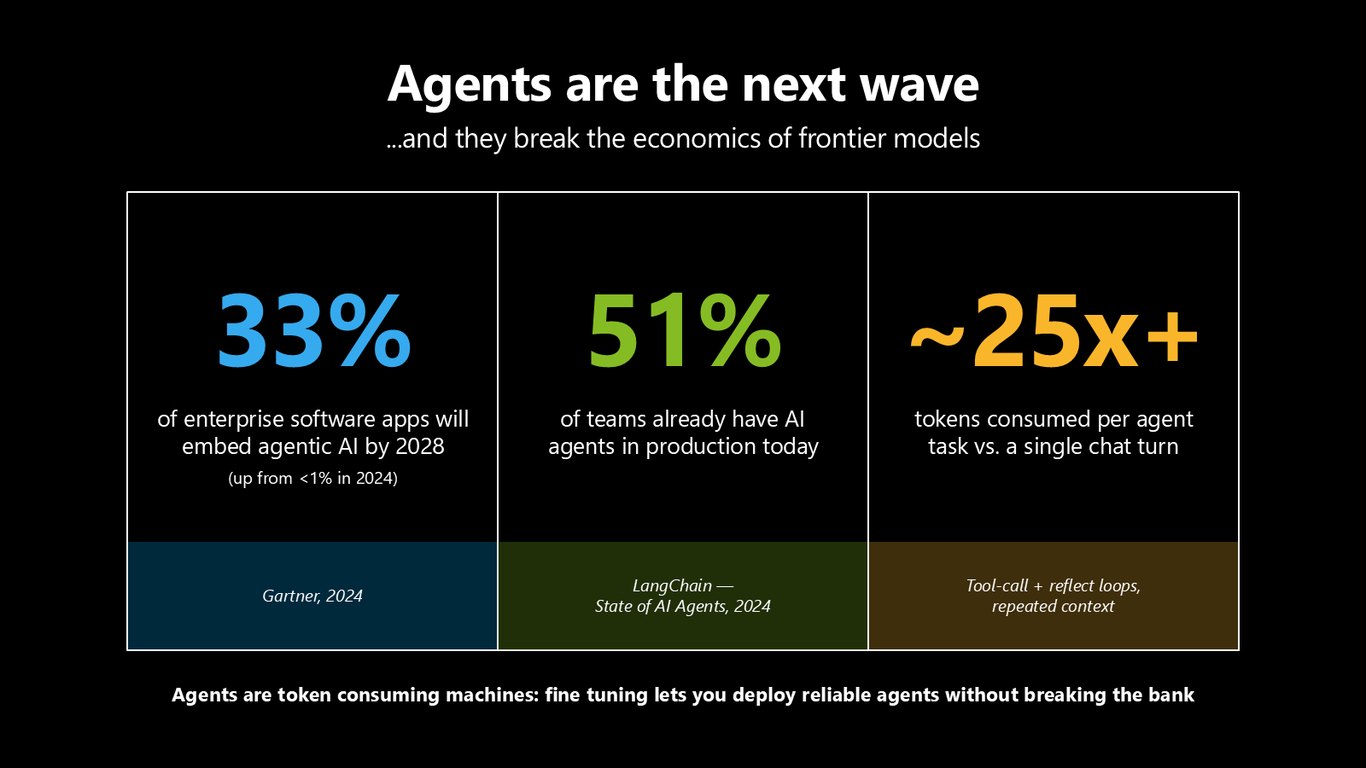
에이전트는 프런티어 모델의 경제학을 깨뜨린다
에이전트는 다음 물결입니다. 2028년이면 엔터프라이즈 앱의 33%가 에이전틱 AI를 품게 되고, 이미 절반이 넘는 팀이 프로덕션에서 에이전트를 돌리고 있죠. 문제는 에이전트가 한 번의 채팅 대비 25배 넘는 토큰을 태우는 토큰 소비 기계라는 겁니다. 진짜 질문은 이거예요. 어떻게 프로덕션에 올릴 뿐 아니라 계속 개선하느냐. 모델은 몇 달마다 새로 나옵니다. 모델을 쫓으면 러닝머신 위에 있는 거예요. 필요한 건 평가·파인튜닝·배포가 도는 하나의 시스템, 바로 루프입니다.
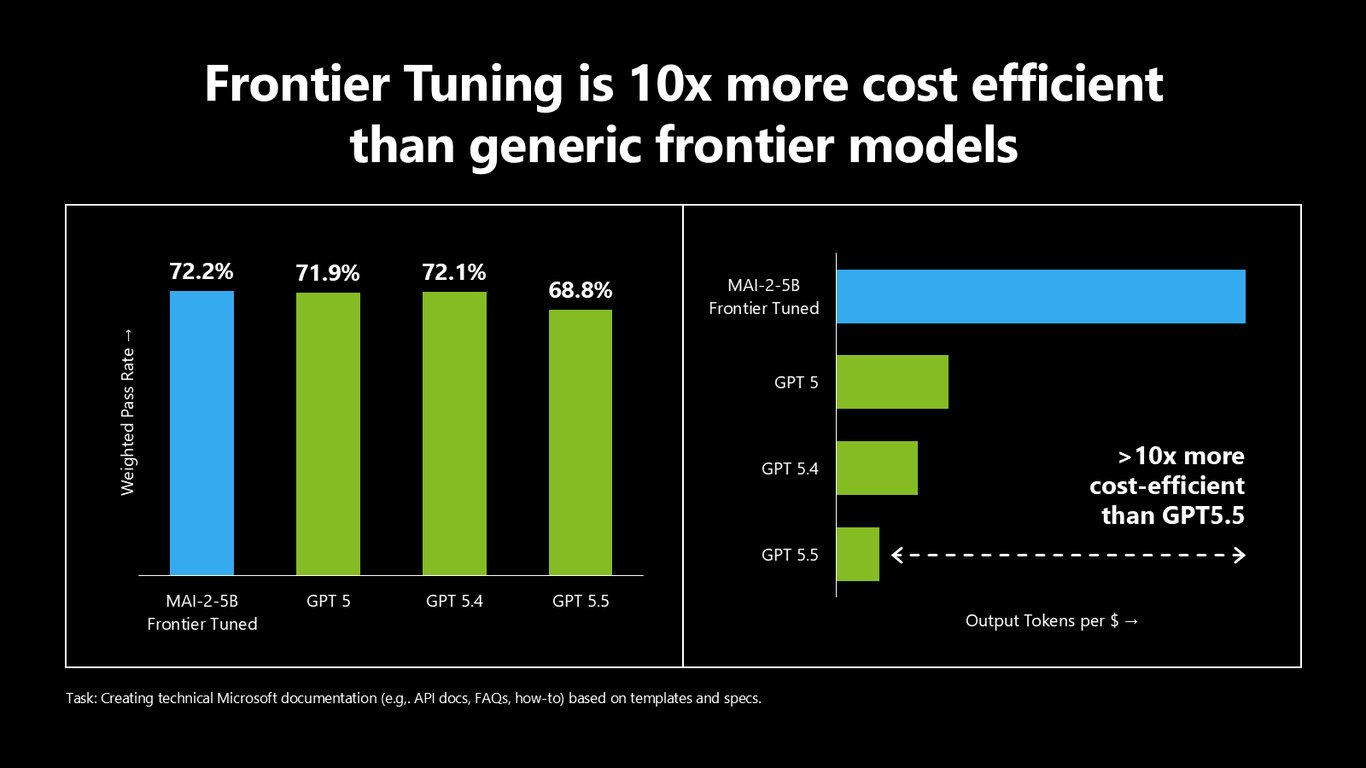
프런티어 튜닝은 10배 더 비용 효율적
그럼 왜 굳이 튜닝을 하느냐. 템플릿과 스펙 기반으로 Microsoft 기술 문서를 만드는 작업을 예로 들면, 프런티어 튜닝한 모델이 GPT5.5보다 10배 넘게 비용 효율적입니다. 같은 일을 훨씬 싸게 해내는 거죠.

평가가 곧 제품 스펙이다
여기서 사고방식을 한번 바꿔보시죠. 개선 루프 안에서 평가가 곧 제품 스펙입니다. 무엇이 좋은 것인지, 어떤 트레이드오프가 중요한지 정의하고, 시스템에 가하는 모든 변경을 재는 잣대가 되죠. 저희 여행 플래너의 경우 정확성, 정책 준수, 툴 호출 유효성, 에스컬레이션 정확도, 안전·프라이버시가 평가 계약에 들어갑니다. 모델을 바꾸든 프롬프트를 바꾸든, 전부 이 기준으로 측정됩니다.
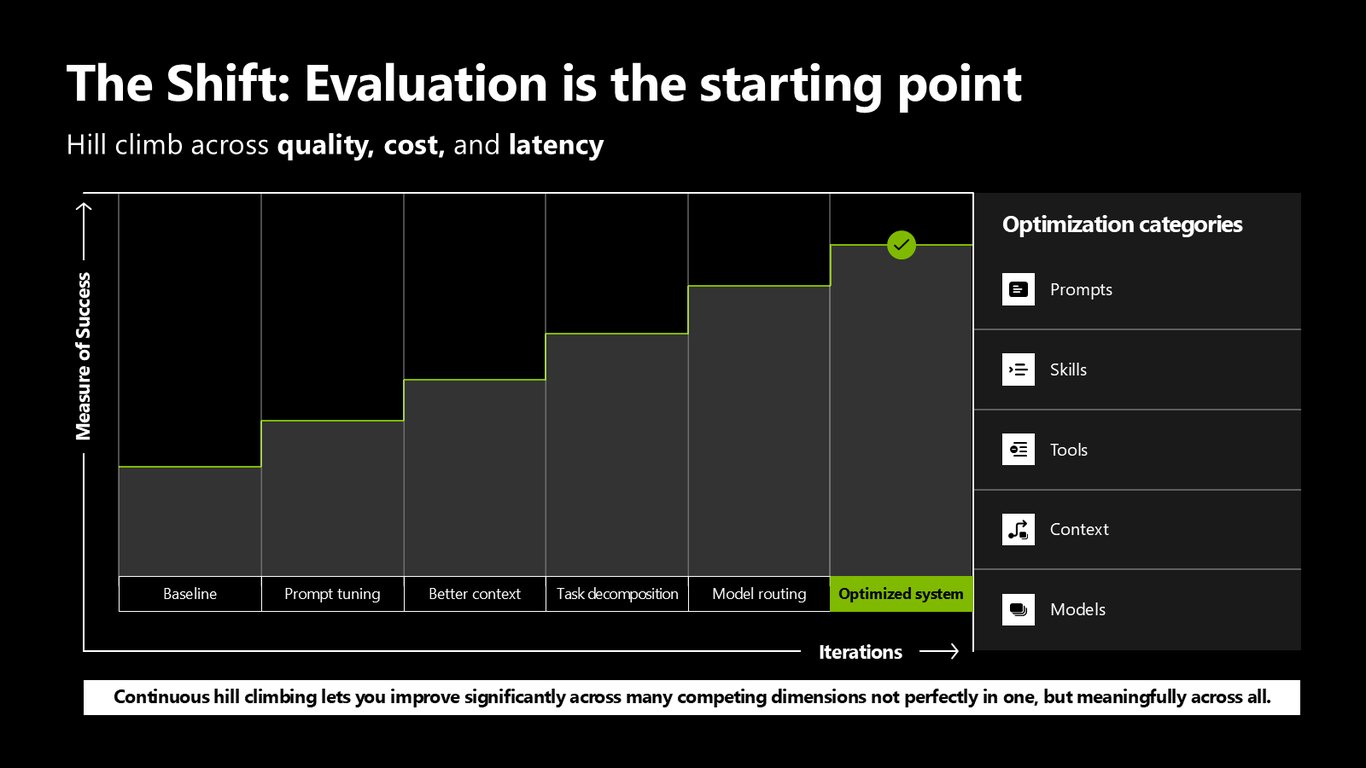
평가는 끝이 아니라 출발점
그래서 평가는 마지막에 하는 게 아니라 출발점입니다. 어떤 모델, 어떤 프롬프트, 어떤 아키텍처든 품질·비용·지연이라는 언덕을 기준으로 재면서 계속 올라가는 거죠. 프롬프트, 컨텍스트, 스킬, 툴, 그리고 마지막엔 모델까지 순서대로 최적화해 나갑니다. 세 축을 한 번에 완벽하게 올리긴 어렵지만, 꾸준히 언덕을 오르면 모든 방향에서 의미 있게 나아갈 수 있습니다.

자, 이제 말로만 하지 말고 직접 보여드리겠습니다. Naomi가 Foundry에서 후처리 학습을 어떻게 돌리는지 데모로 함께 보시죠.

데이터를 고르고, 행동을 고른다 — 당신의 조합
후처리 학습은 정해진 파이프라인이 아니라 레시피 북이라고 보시면 됩니다. 왼쪽에는 모을 수 있는 여섯 가지 데이터 소스가 있어요. 디스틸레이션, 에이전트 트래젝토리, 합성 데이터, 사람의 선호, 검증 가능한 보상, 그리고 도메인 코퍼스죠. 오른쪽에는 원하는 여섯 가지 행동이 있고, 이 둘은 자유롭게 이어집니다. 어떤 데이터든 어떤 행동이든 빚어낼 수 있어요. 핵심은 학습 시간의 약 80%가 실제 훈련이 아니라 데이터 준비라는 점이고, 바로 여기서 여러분의 도메인 전문성이 가장 큰 힘을 발휘합니다.
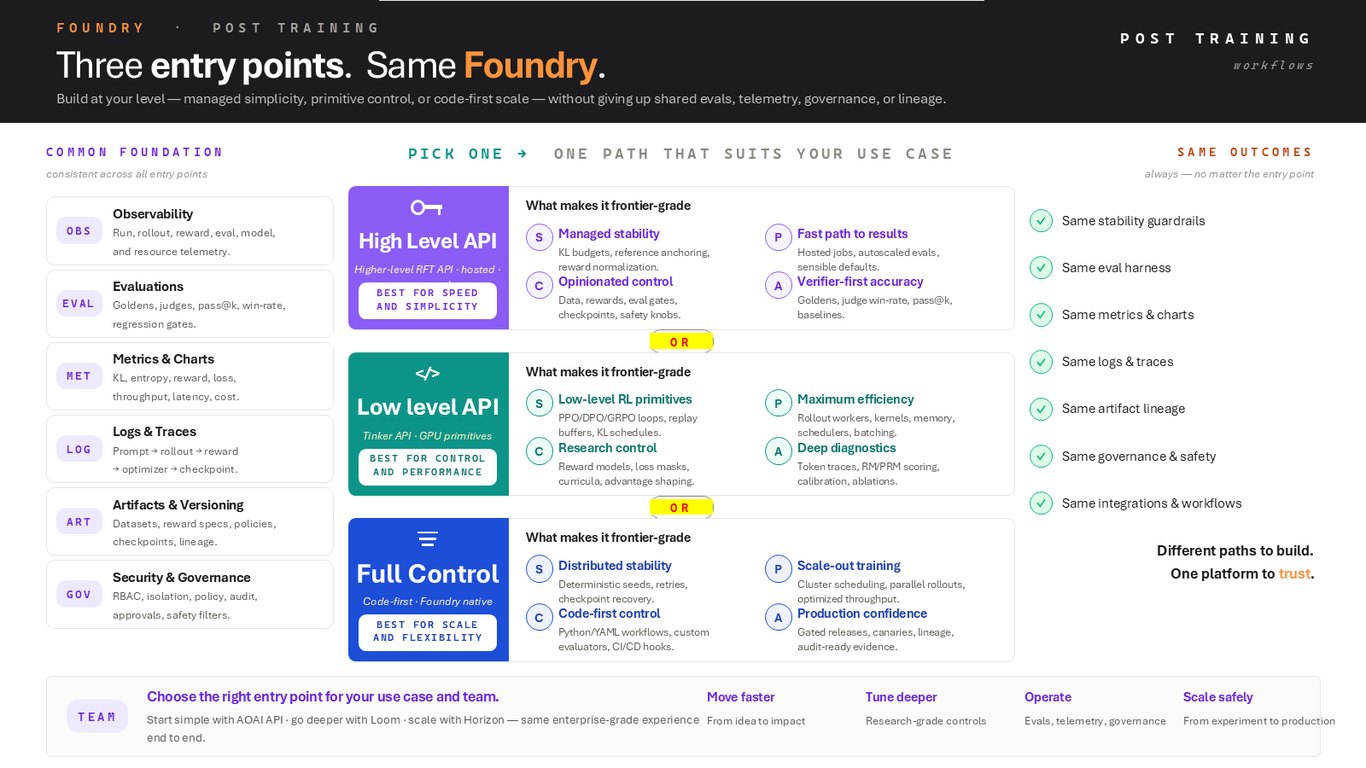
세 개의 진입점, 하나의 Foundry
플랫폼은 하나지만 진입점은 세 개입니다. 관리형으로 빠르게 가는 High Level API, GPU 프리미티브까지 제어하는 Loom, 코드 우선으로 확장하는 Horizon. 어느 길을 택하든 관측성, 평가, 메트릭, 로그와 트레이스, 아티팩트와 버전 관리, 보안·거버넌스라는 공통 토대는 그대로 공유합니다. 한 진입점에서 졸업하는 게 아니라, 문제의 성격이 바뀌면 필요한 층으로 내려가거나 올라가는 거죠. 만들 때 길은 달라도 믿는 플랫폼은 하나입니다.
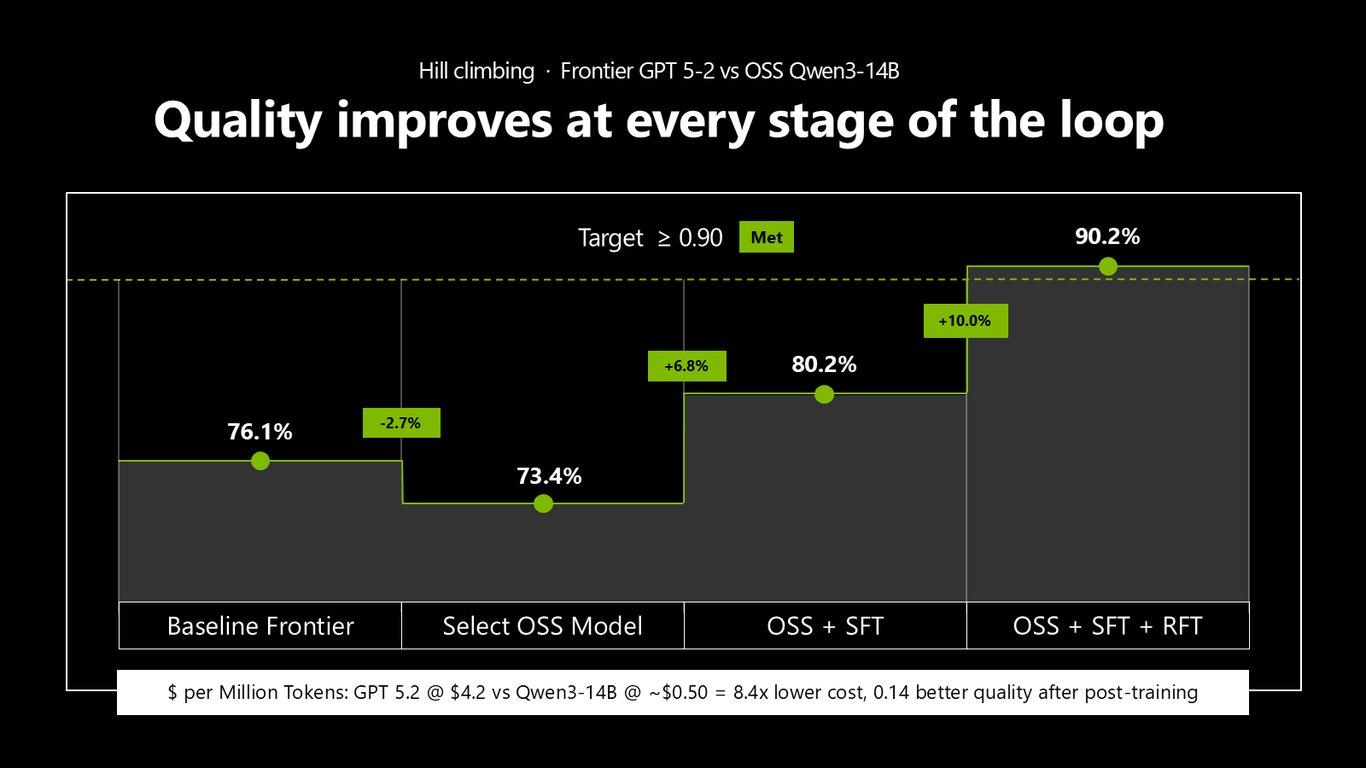
루프의 모든 단계에서 품질이 오른다
결과를 보시죠. 목표는 0.90 이상이었습니다. 오픈소스 Qwen3-14B로 시작하면 73.4%였는데, SFT를 얹어 80.2%, 여기에 RFT까지 더하니 90.2%로 목표를 넘겼습니다. 프런티어 GPT 5.2 대비 품질은 0.14 더 좋으면서, 토큰당 비용은 8.4배 낮습니다. 루프의 매 단계에서 품질이 올라간다는 걸 숫자로 보여드린 거예요.

오늘 밤부터 시작하세요
여러분의 에이전트 튜닝, 오늘 밤부터 바로 시작하실 수 있습니다. 감사합니다.