
안녕하세요, 오늘은 큰 모델의 실력을 작은 모델에 옮겨 담는 model distillation을 실제 에이전트에 어떻게 적용하는지 이야기해 보겠습니다. 이론이 아니라, 프로덕션에서 바로 써먹을 수 있는 관점으로 풀어드릴게요.

핵심 메시지는 간단합니다. fine-tuning으로 모델을 증류하면 더 작고, 더 빠르면서도, 더 똑똑한 모델을 만들 수 있다는 거죠. 오늘 이 세 가지를 어떻게 동시에 잡는지 보여드리겠습니다.

model distillation이란?
distillation은 두 모델 사이의 도제식 학습이라고 생각하시면 쉽습니다. 크고 유능한 teacher 모델이 실제 과제를 풀면서 그 과정을 다 보여주면, 우리는 teacher가 무슨 말을 하고 어떤 도구를 어떤 순서로 쓰는지 수많은 예시로 모읍니다. 그리고 작고 저렴한 student 모델을 그 예시대로 fine-tuning하죠. 중요한 건 student가 정답을 외우는 게 아니라 teacher의 습관을 배운다는 점입니다. 그래서 같은 도메인의 새로운 질문도 훨씬 싼 비용과 짧은 지연으로 처리할 수 있습니다.
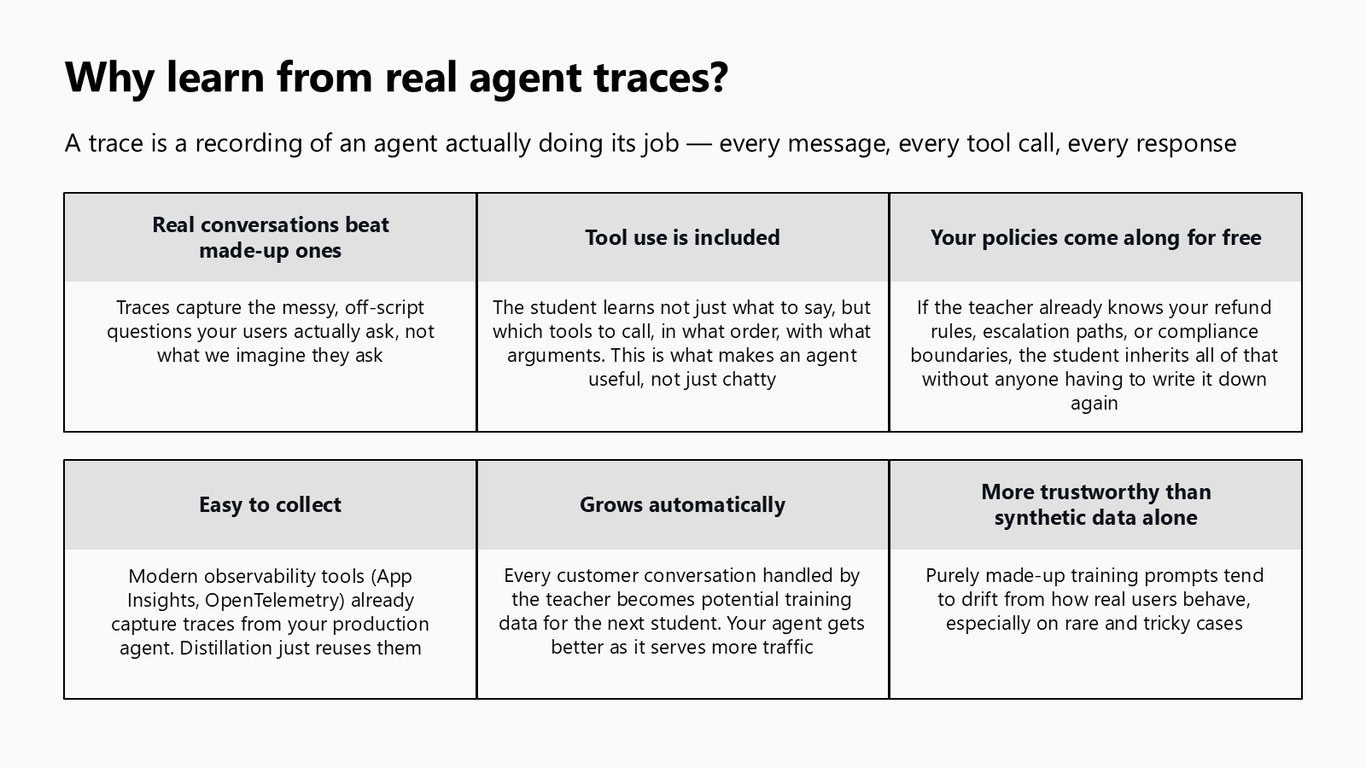
왜 실제 trace로 배우나
그러면 왜 실제 에이전트 trace로 학습해야 할까요? trace는 에이전트가 실제로 일하는 모든 과정, 즉 모든 메시지와 도구 호출, 응답을 그대로 담은 기록입니다. 사용자가 진짜로 던지는 지저분하고 예상 밖인 질문이 담기고, 어떤 도구를 어떤 순서로 어떤 인자로 호출하는지까지 student가 배웁니다. 게다가 teacher가 이미 알고 있는 환불 규칙이나 에스컬레이션, 컴플라이언스 경계까지 student가 그대로 물려받죠. App Insights나 OpenTelemetry 같은 관측 도구가 이미 이 trace를 수집하고 있으니, distillation은 그걸 재활용하는 셈입니다. 트래픽이 늘수록 학습 데이터도 자동으로 쌓입니다.

증류로 얻는 네 가지
증류한 student를 프로덕션에 올리면 서로 맞물려 커지는 네 가지 이득이 있습니다. 우선 호출당 비용이 한 자릿수 이상 싸져서, 적자 나던 제품이 수익이 나는 제품으로 바뀝니다. 응답도 훨씬 빨라져서 실시간이나 온디바이스 환경까지 노려볼 수 있고요. 학습시킨 좁은 과제에서는 teacher에 가까운 품질을 회복합니다. 그리고 무엇보다, 실행할 때마다 결과가 더 일관됩니다. 고객을 마주하는 서비스에서는 최고 정확도보다 이 예측 가능성이 더 중요하죠.
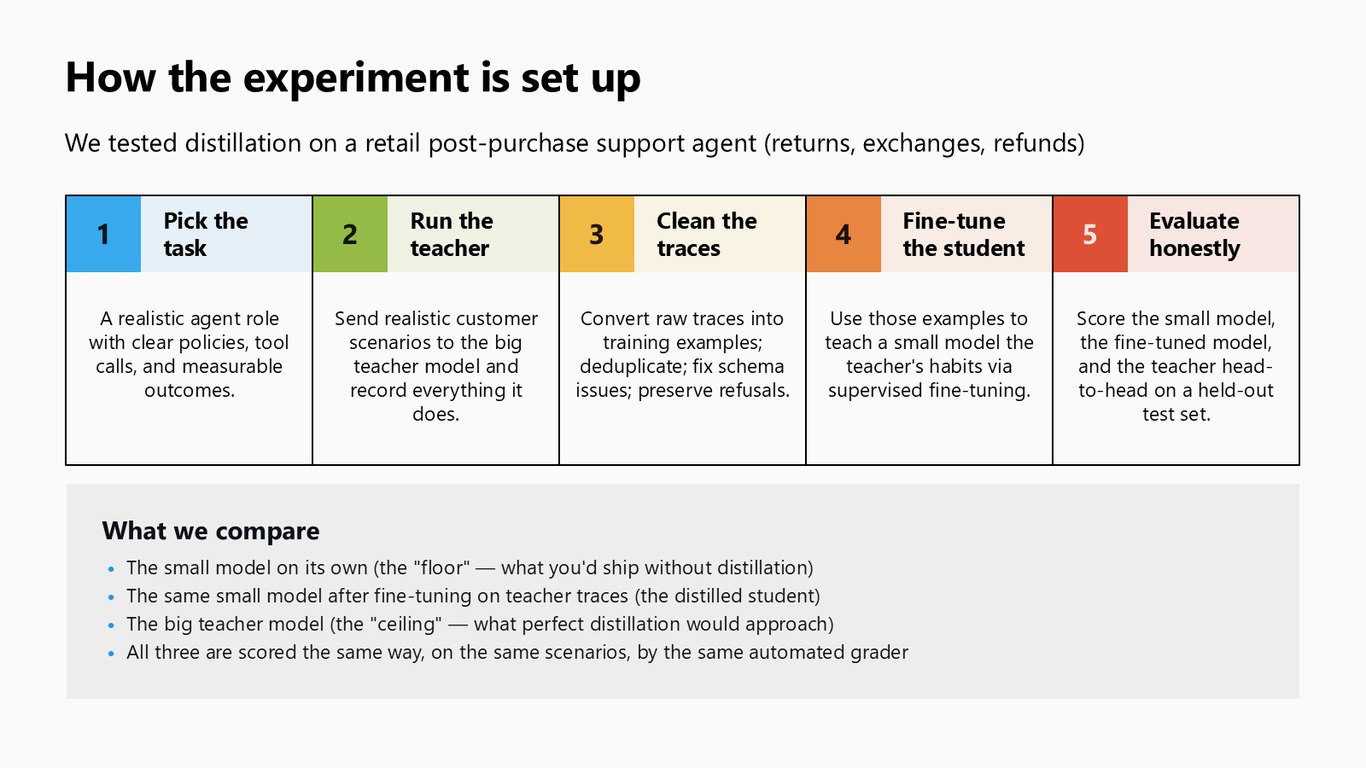
실험은 이렇게 구성했습니다
이제 실제 실험을 보겠습니다. 반품, 교환, 환불을 다루는 리테일 구매 후 지원 에이전트를 대상으로 잡았습니다. 먼저 명확한 정책과 도구 호출이 있는 과제를 정하고, teacher에 현실적인 고객 시나리오를 던져 모든 걸 기록합니다. 그 다음 raw trace를 학습 예시로 정제하면서 중복을 제거하고 스키마를 고치되 거절 응답은 남겨둡니다. 이 예시로 작은 모델을 supervised fine-tuning하고요. 마지막으로 원본 작은 모델, 증류된 student, teacher 이 셋을 같은 채점기로 같은 held-out 테스트셋에서 정직하게 비교합니다.

베스트 프랙티스 1 — 평가부터
첫 번째 베스트 프랙티스는, 무엇보다 평가를 먼저 제대로 세우라는 겁니다. 측정할 수 없으면 개선할 수 없으니까요. 쉬운 문제를 잔뜩 모으기보다, 정말 어렵고 적대적인 시나리오를 손으로 골라 작지만 단단한 테스트셋을 만드세요. 그리고 첫날부터 별도의 held-out 셋을 떼어 두고 학습 중엔 절대 들여다보지 마세요. 단발 질문이 아니라 실제처럼 여러 턴으로 테스트하고, 평균 정확도만이 아니라 반복했을 때의 일관성까지 재야 합니다. 사용자가 진짜 신경 쓰는 것, 즉 올바른 결과와 정확한 도구, 정책 준수를 채점하고, 모든 모델에 같은 채점기와 같은 시나리오를 쓰세요.

베스트 프랙티스 2 — 데이터 품질
두 번째는 데이터 품질입니다. 프로덕션 trace와 합성 예시를 섞는 건 잘만 하면 효과적입니다. 프로덕션 trace가 흔한 경우를 커버하면, 잘 안 나오는 희귀 카테고리나 엣지 케이스는 겨냥한 합성 예시로 메우는 거죠. 학습 전에 스키마를 반드시 검증하고, 같은 시나리오가 똑같이 반복되지 않도록 대화 단위로 중복을 제거하세요. 짧은 답이나 거절은 노이즈처럼 보여도 정책 경계를 담고 있으니 버리지 마시고요. 시스템 프롬프트는 모든 학습 행에서 동일하게 유지하고, 카테고리별 예시 수를 세어 가장 적은 쪽을 학습 전에 보강하세요.

베스트 프랙티스 3 — 빠른 반복
세 번째는 fine-tuning 도구로 빠르게 반복하라는 겁니다. 사실 병목은 학습 실행 자체가 아니라 그 주변의 모든 것이에요. 데이터 변환, 학습 인프라, 배포를 대신 처리해 주는 관리형 서비스에 기대세요. 평가 결과는 적극적으로 캐시해서, 작은 변경 뒤 다시 돌릴 때 바뀐 부분만 재실행되게 만드세요. fine-tuning 엔드포인트는 용량이 작을 수 있으니 single-tenant로 보고 트래픽을 직렬화하는 게 좋습니다. 평가 하네스는 학습 파이프라인보다 먼저 만들고, 스크립트를 파라미터화해 어떤 시나리오 파일이든 경로만 바꿔 돌아가게 하세요. 그리고 방어 가능한 held-out 숫자와, 이야기를 만들려고 고른 하이라이트는 분명히 구분하세요.

핵심 정리
정리하겠습니다. distillation은 연구실의 호기심이 아니라 실무에서 당장 당길 수 있는 레버입니다. 운영 중인 에이전트의 trace는 공짜이면서 품질 높은 학습 신호이고, 그걸로 fine-tuning한 작은 모델은 teacher와의 격차를 대부분 좁히면서 비용은 훨씬 낮춥니다. 세 가지만 기억하세요. 첫째, 평가에 먼저 투자하세요. 둘째, 데이터를 신중하게 큐레이션하세요. 양보다 품질과 커버리지입니다. 셋째, 도구를 활용하세요. 관리형 fine-tuning과 캐싱, 재사용 가능한 스크립트가 몇 달 걸릴 일을 몇 주로 줄여줍니다. 감사합니다.