
세션을 시작하며
안녕하세요, Microsoft Build 2026 DEM331 세션에 오신 걸 환영합니다. 오늘은 에이전트가 현실의 콘텐츠를 만났을 때 생기는 문제와, 그걸 어떻게 푸는지를 함께 살펴보겠습니다.

이번 세션의 제목은 Turn APIs, tools, and data into real agent velocity입니다. API와 도구, 데이터를 진짜 에이전트의 속도로 바꾸는 이야기를 해보겠습니다. 아, 세션이 원활히 진행되도록 제공된 헤드셋도 미리 착용해 주세요.
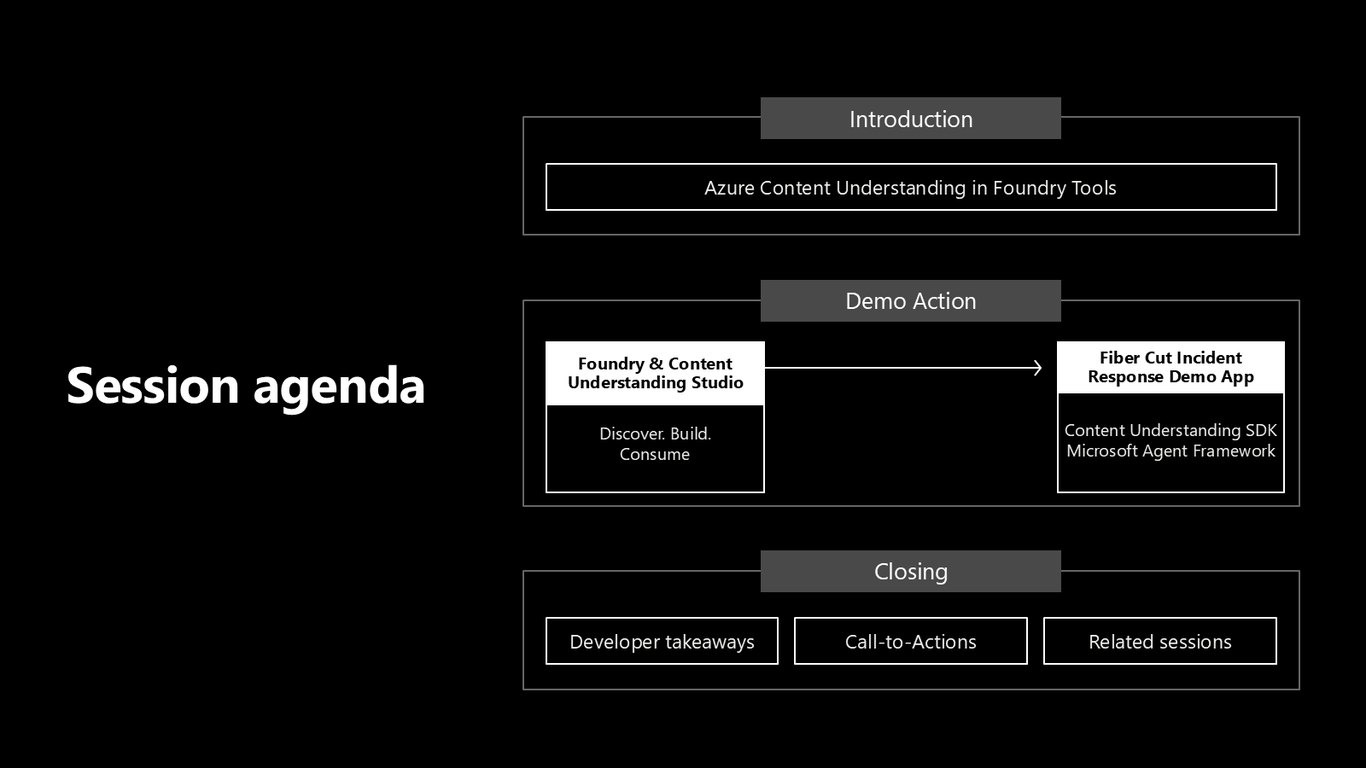
오늘의 세션 흐름
오늘 흐름은 이렇습니다. 먼저 Foundry Tools 안의 Azure Content Understanding을 간단히 소개하고, 이어서 광케이블 절단 사고 대응 시나리오로 이 도구를 Foundry 모델, 그리고 Microsoft Agent Framework와 함께 어떻게 활용하는지 직접 보여드리겠습니다.
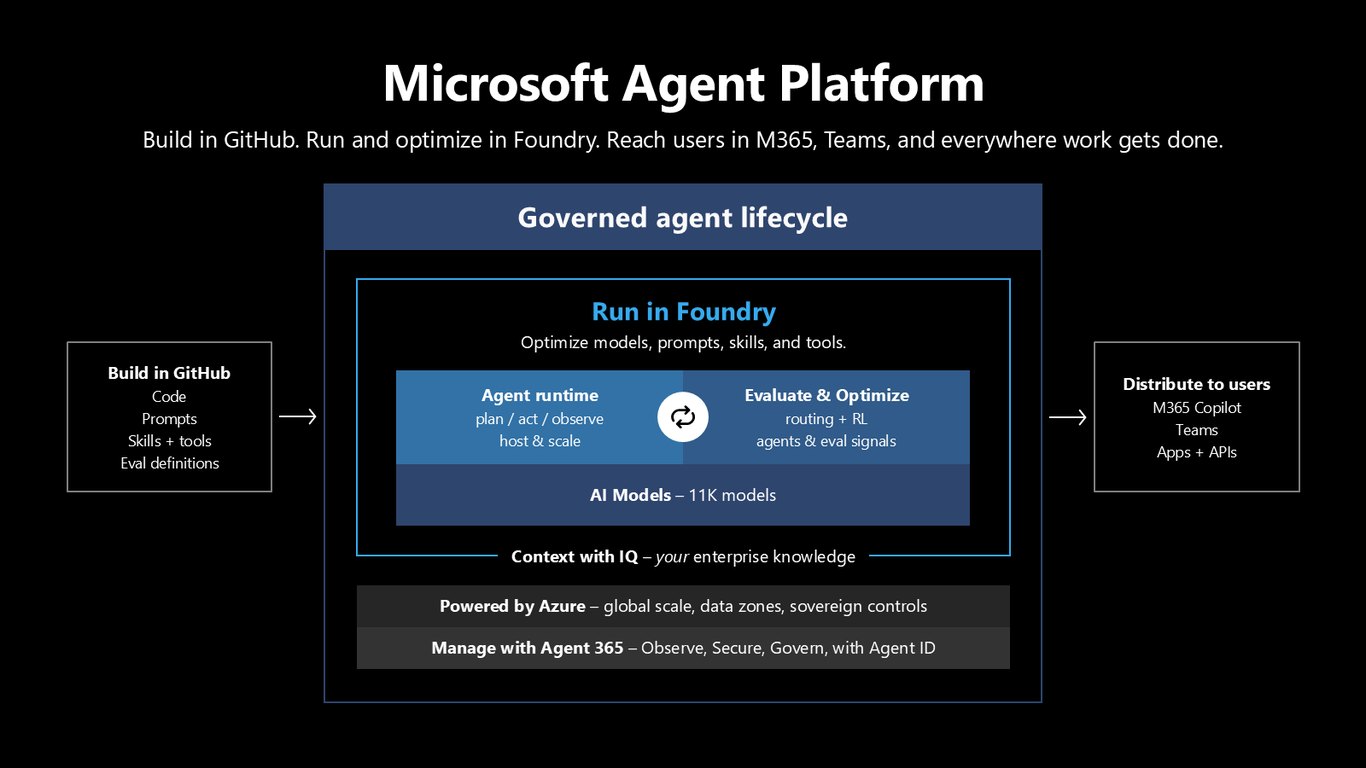
Microsoft Agent Platform
먼저 큰 그림입니다. Microsoft Agent Platform은 GitHub에서 만들고, Foundry에서 실행하고 최적화하고, M365와 Teams 등 일하는 모든 곳으로 사용자에게 전달합니다. 이 모든 걸 Azure가 떠받치고 Agent 365로 거버넌스까지 관리하죠. 흩어져 있던 기술을 하나로 엮어 실제로 맞물려 돌아가게 하는 게 Microsoft의 강점입니다.
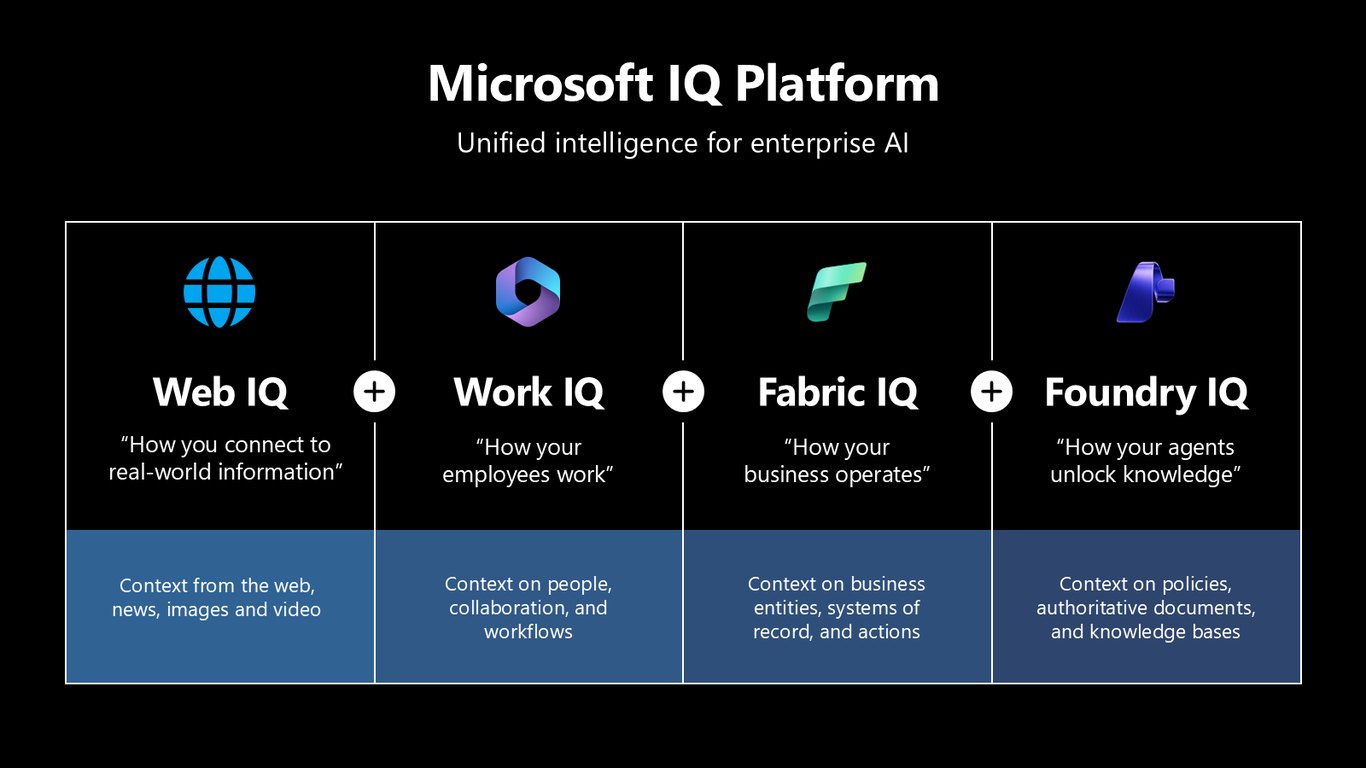
Microsoft IQ Platform
에이전트가 똑똑해지려면 맥락이 필요한데요, 그 엔진이 바로 Microsoft IQ입니다. 직원이 일하는 방식을 잇는 Work IQ, 비즈니스가 돌아가는 방식을 모델링한 Fabric IQ, 지식을 풀어내는 Foundry IQ, 그리고 웹 정보를 연결하는 Web IQ까지. 이 IQ들이 모여 에이전트에게 사람과 비즈니스, 지식에 대한 진짜 인식을 줍니다.

에이전트는 현실 콘텐츠에서 무너진다
그런데 이 에이전트들이 현실의 콘텐츠를 만나면 자주 무너집니다. 현실 데이터는 깔끔한 API로 오지 않죠. 46페이지 스캔 PDF, 8분짜리 영상, 23분 통화 녹음 같은 게 그대로 들어옵니다. 원본 바이트를 그냥 LLM에 던지면 토큰이 폭증하고, 표를 잘못 읽고, 응답은 느려지고 신뢰도는 떨어집니다. 바로 여기서 Content Understanding이 등장합니다.
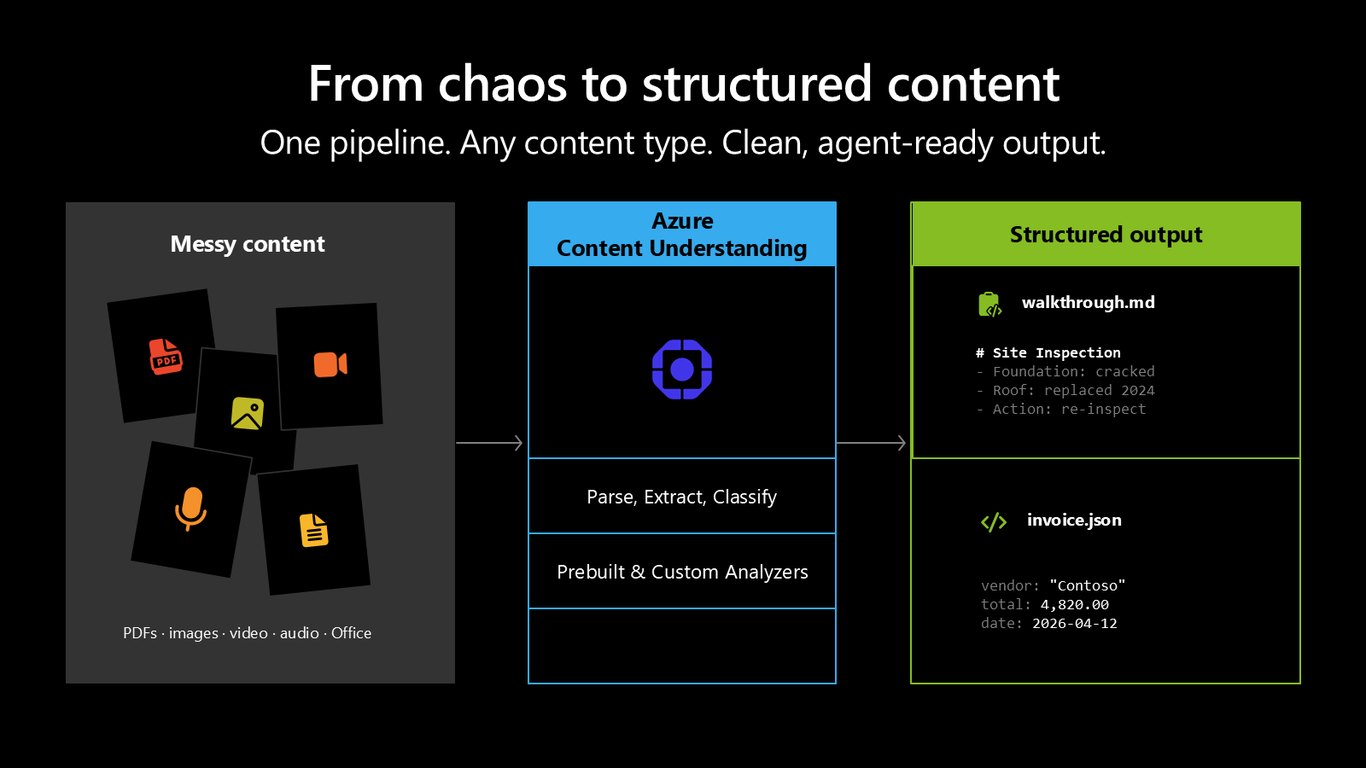
혼돈을 구조화된 콘텐츠로
Content Understanding은 지저분하고 형식도 제각각인 콘텐츠를 깔끔하게 구조화된, 에이전트가 바로 쓸 수 있는 출력으로 바꿔줍니다. 핵심 동작은 세 가지, Parse와 Classify, Extract고요. 결과는 키-값과 구조화된 데이터가 담긴 Markdown과 JSON입니다. 에이전트에게 원본 바이트 대신 근거 있는 입력을 주는 거죠.

앱·에이전트·IQ의 콘텐츠 추출 계층
사실 이건 갓 나온 서비스가 아닙니다. 약 1년 반 전부터 시장에 있었고, 작년 Ignite 이후 정식 출시됐죠. 지금은 Microsoft 내부의 핵심 콘텐츠 추출 계층이 됐는데요, 이번 Build에서 GA되는 Foundry IQ의 추출 엔진이 바로 이겁니다. M365 Copilot에서 문서를 올릴 때도, Agent Framework나 LangChain, MarkItDown 연동에서도 이걸 씁니다.

Content Understanding 파이프라인
구조를 보면, Content Understanding은 하나의 파이프라인에서 시작합니다. 어떤 입력이든 Parse로 markdown 형태의 구조를 만들고, Classify로 어떤 콘텐츠인지 식별해 조각으로 나누고, Extract로 필요한 필드와 스키마를 뽑아냅니다.
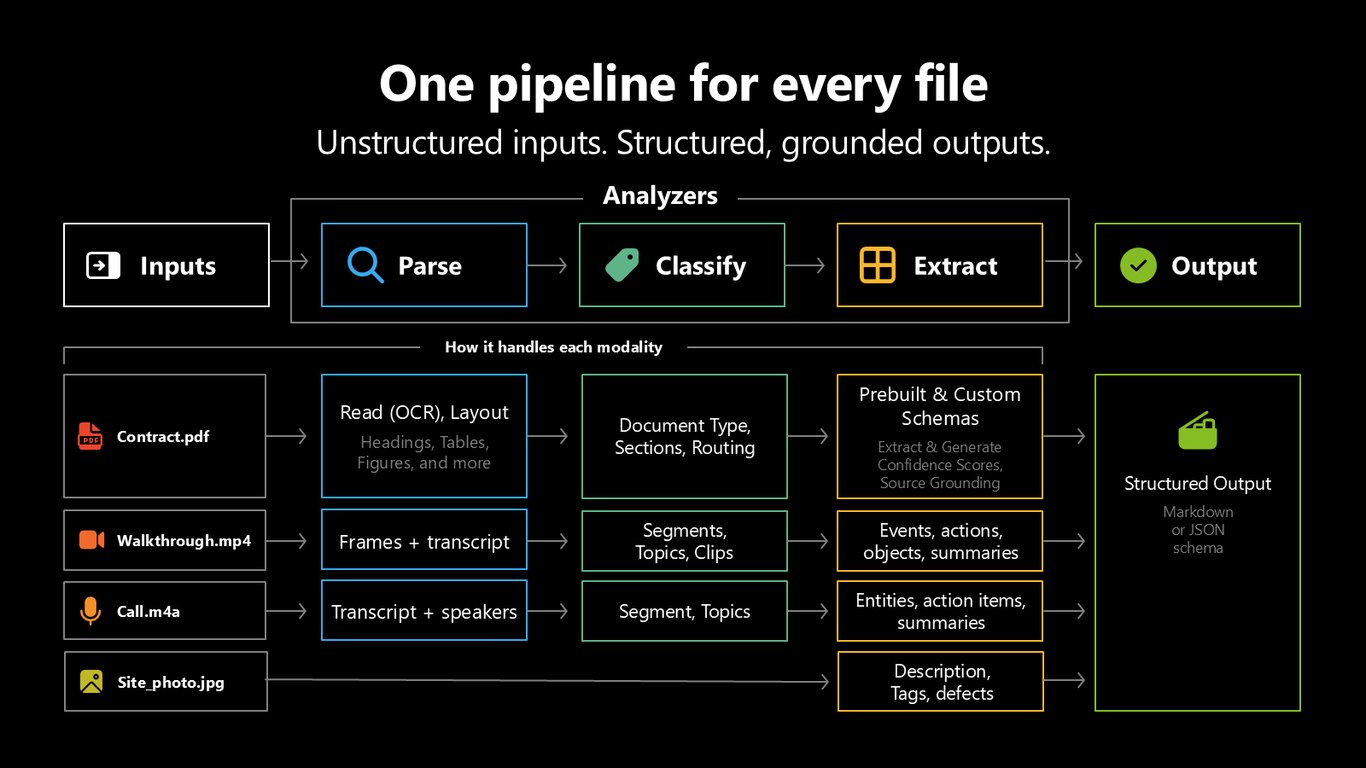
모든 파일을 위한 하나의 파이프라인
같은 파이프라인이지만 파일 종류마다 최적화돼 있습니다. 문서는 read와 layout으로 제목과 표, 그림을 뽑고, 영상은 프레임과 대본을 추출해 주제별 클립으로 나누고, 오디오와 이미지도 각각 전용 파이프라인으로 처리합니다. 하나의 파이프라인으로 모든 파일을 다루는 거죠.

자, 이제 데모로 넘어가겠습니다. 직접 따라 해보고 싶으신 분은 화면의 QR 코드를 스캔하시면 GitHub 저장소로 바로 이동하실 수 있습니다.
Foundry에서 만나는 Content Understanding
먼저 Foundry 안에서 Content Understanding을 어떻게 탐색하고 사용하는지 보시겠습니다. 이어지는 영상에서는 Invoice 프리빌트와 Audio Search 프리빌트를 활용하는 모습을 직접 보여드립니다.
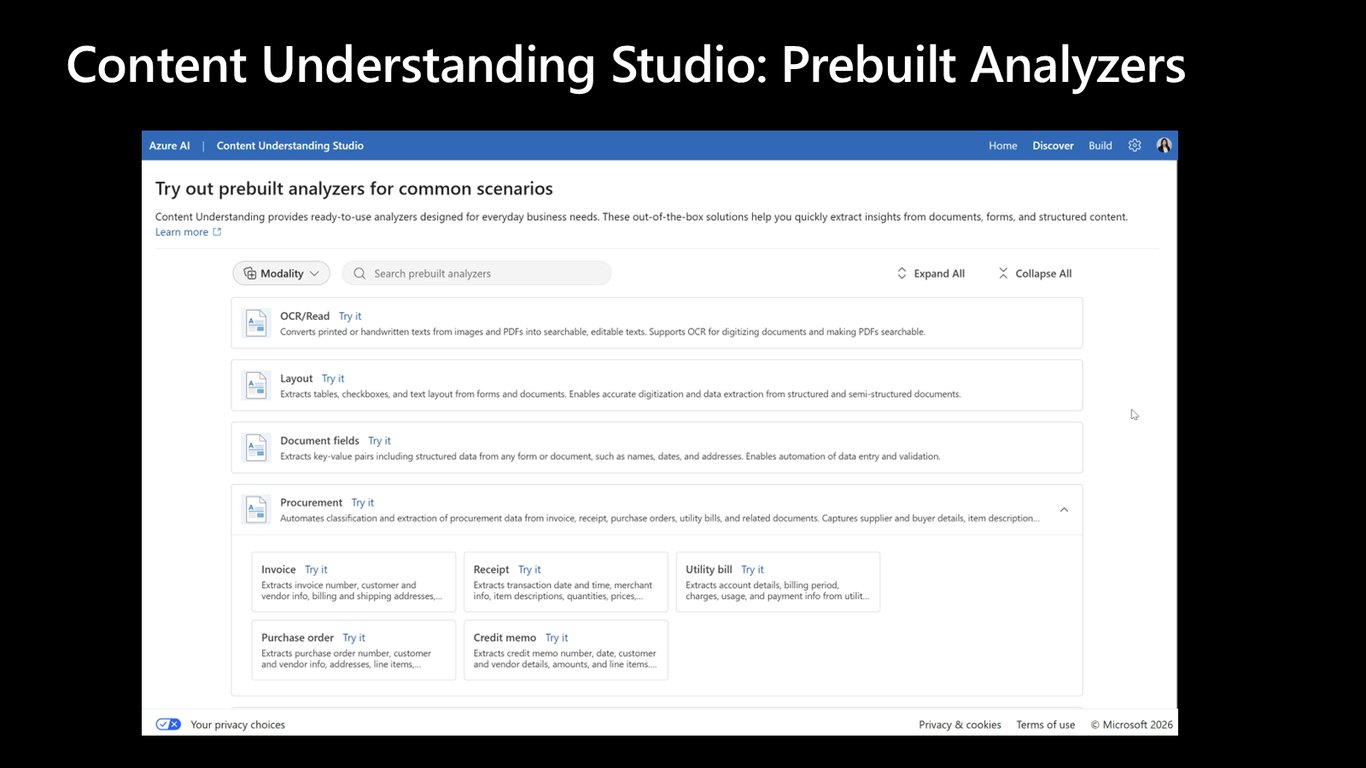
Studio의 프리빌트 분석기
이번엔 Content Understanding Studio입니다. 여기엔 바로 쓸 수 있는 프리빌트 분석기 목록이 있는데요, 예를 들어 video search 분석기로 영상 점검 리포트를 자동 생성하는 걸 영상으로 보여드립니다.
현장 시나리오로 들어가며
이제 실제 업무 시나리오를 하나 놓고 보겠습니다. 광케이블이 절단된 현장, 그 사고 대응 상황을 함께 가정해 보죠.

제각각인 현장 데이터
현장에서 올라오는 자료는 제각각입니다. 점검 리포트 PDF, 현장 영상, 통화 녹음까지 형식이 다 다르죠. 이 다양한 입력을 에이전트가 이해하게 만드는 게 바로 관건입니다.
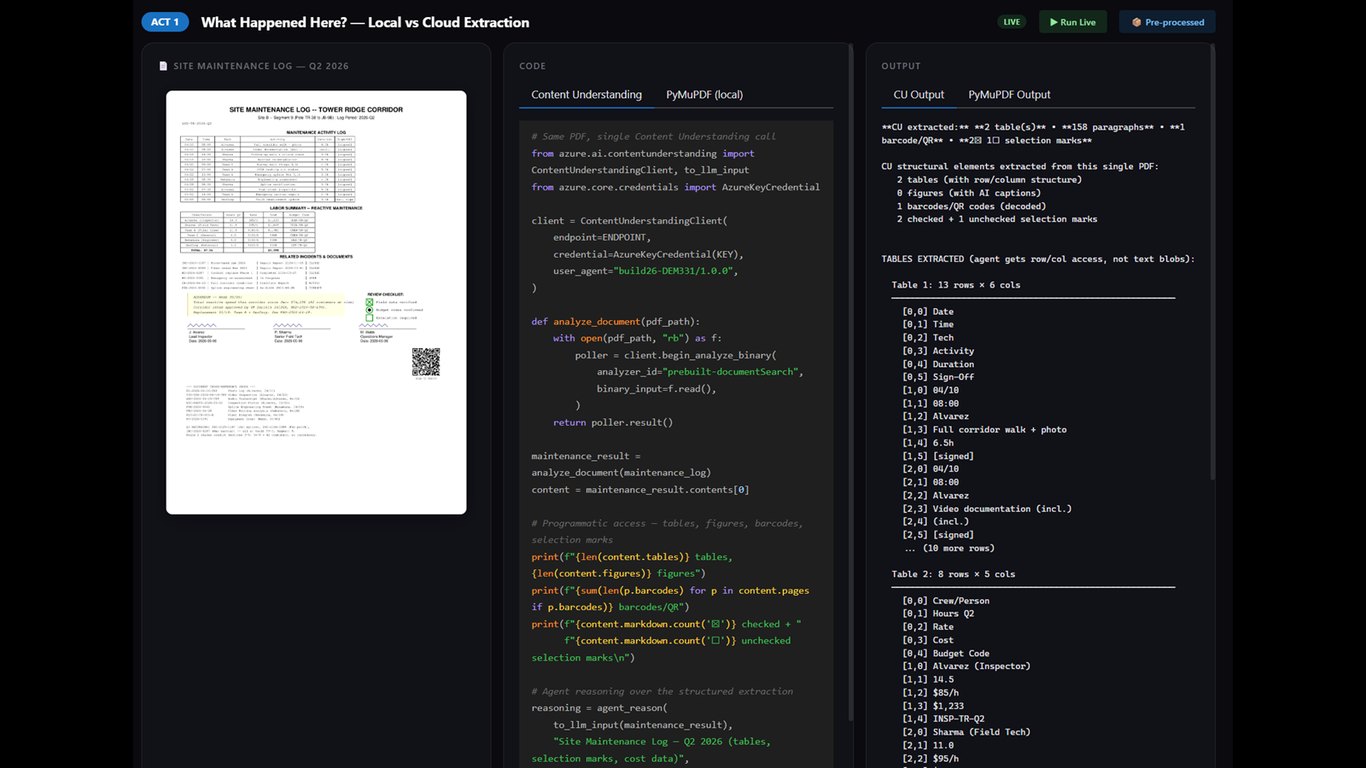
구조화가 만드는 차이
이 제각각인 자료를 Content Understanding으로 구조화하면, 에이전트가 현장 상황을 파악하고 다음 조치를 스스로 판단할 수 있게 됩니다.

데모: Fiber Cut 사고 대응 앱
이제 핵심 데모, Fiber Cut 사고 대응 앱입니다. 현장에서 들어온 영상과 음성, 문서를 Content Understanding이 구조화하고, 에이전트가 그걸 근거로 상황을 판단해 대응하는 전체 흐름을 영상으로 보여드립니다.
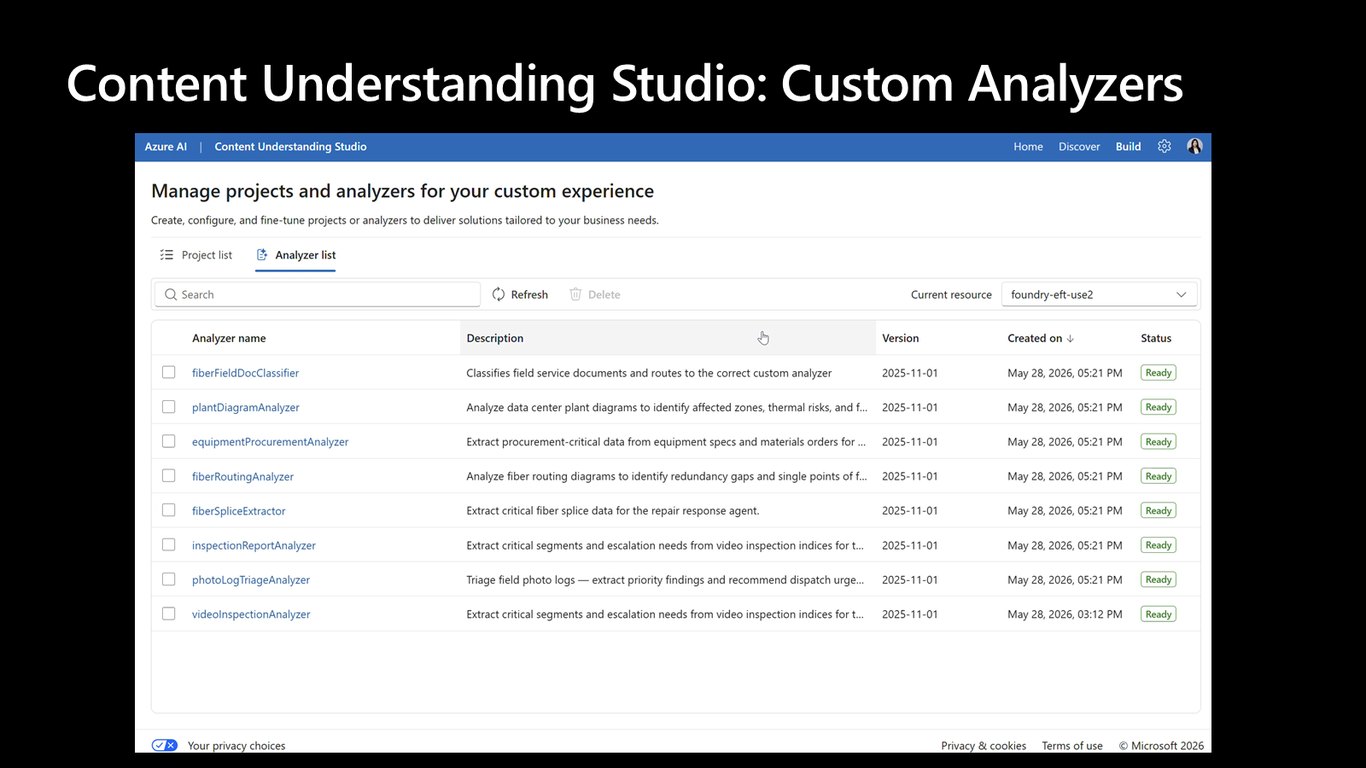
Studio의 커스텀 분석기
다음은 Content Understanding Studio에서 커스텀 분석기를 만드는 모습입니다. 우리 업무에 딱 맞는 스키마로 원하는 값을 뽑아내도록 직접 구성해봅니다.
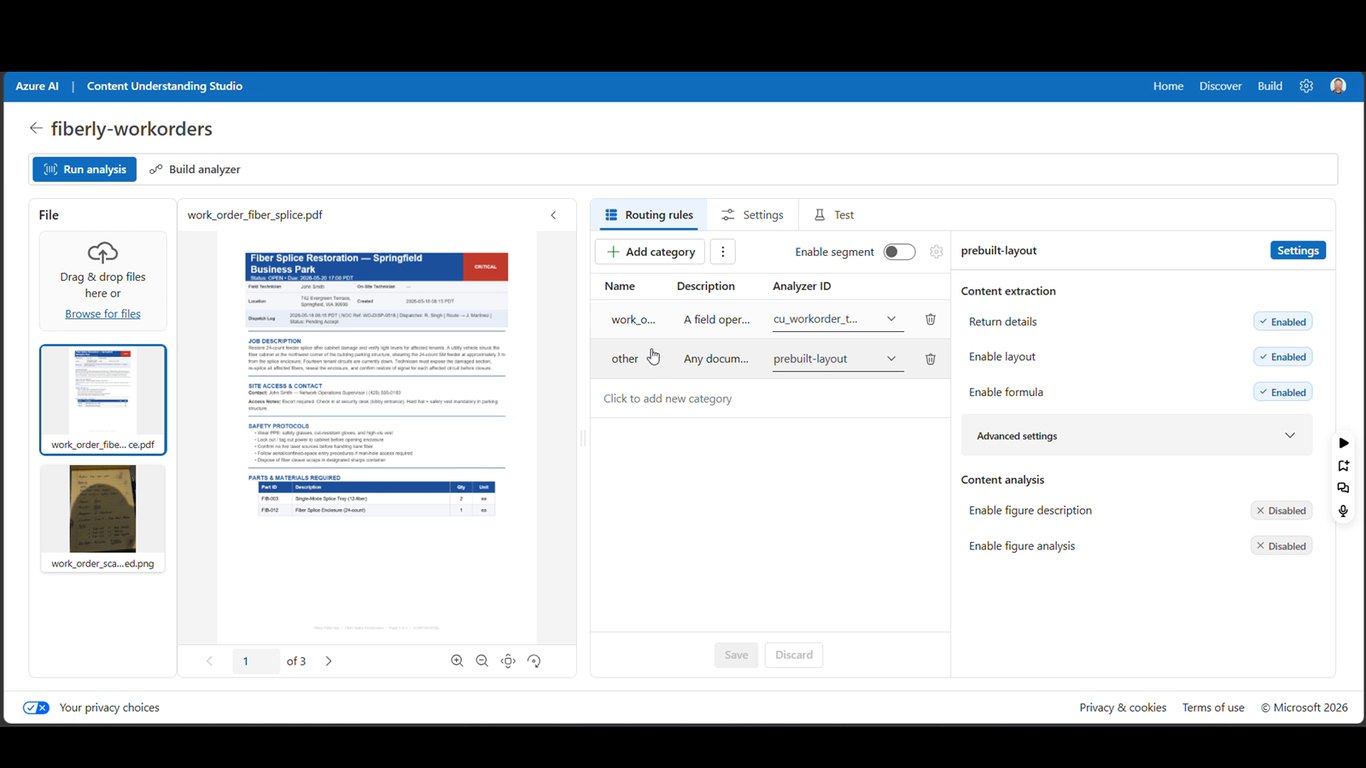
분류기와 라우팅 규칙 구성
여기서는 분류기와 커스텀 분석기를 함께 만듭니다. 들어오는 파일을 분류해서, 작업 지시서는 파싱해 핵심 값을 추출하고 나머지는 프리빌트 layout으로 처리하게 하죠. 그리고 라우팅 규칙까지 넣어서, 사람이 라우팅되면 그 사람이 배정된 기술자가 되도록 만듭니다.

여기까지 보셨으면 이제 직접 시작해 보실 차례입니다. Content Understanding과 Microsoft Agent Framework로 바로 시작해 보시고, 데모 앱과 노트북도 QR 코드로 받아 가세요. 더 깊은 내용은 Breakout Session #242에서 Foundry Toolbox와의 연동까지 함께 다룹니다.

다음 단계는 여기서
여기서 더 나아가고 싶으시다면 가장 빠른 다음 단계를 알려드릴게요. ai.azure.com에서 Foundry로 빌드를 시작하시고, 이번 세션 코드는 aka.ms/build26-DEM331에서 받으시고, Discord 커뮤니티에도 꼭 함께해 주세요.

Agents League Hackathon
혹시 아이디어가 떠오르셨다면, 바로 만들어볼 무대가 있습니다. Agents League Hackathon인데요, 5월 19일부터 6월 14일까지 크리에이티브 앱, 추론 에이전트, 엔터프라이즈 에이전트로 프로젝트를 제출하고 상금에 도전하실 수 있습니다.

이어서 볼 Foundry 세션들
Microsoft Build 2026에서 이 세션은 하나의 시작점일 뿐입니다. 더 깊이 들어가고 싶으시면 모델, Responsible AI, 앱과 에이전트 구축까지 Foundry 세션 가이드를 참고하세요. BRK230, BRK250, BRK241 같은 세션들이 준비돼 있습니다.

이제 남은 시간에는 Content Understanding의 각 단계가 실제로 어떻게 동작하고, 앞으로 무엇이 더해지는지 조금 더 깊이 들여다보겠습니다.
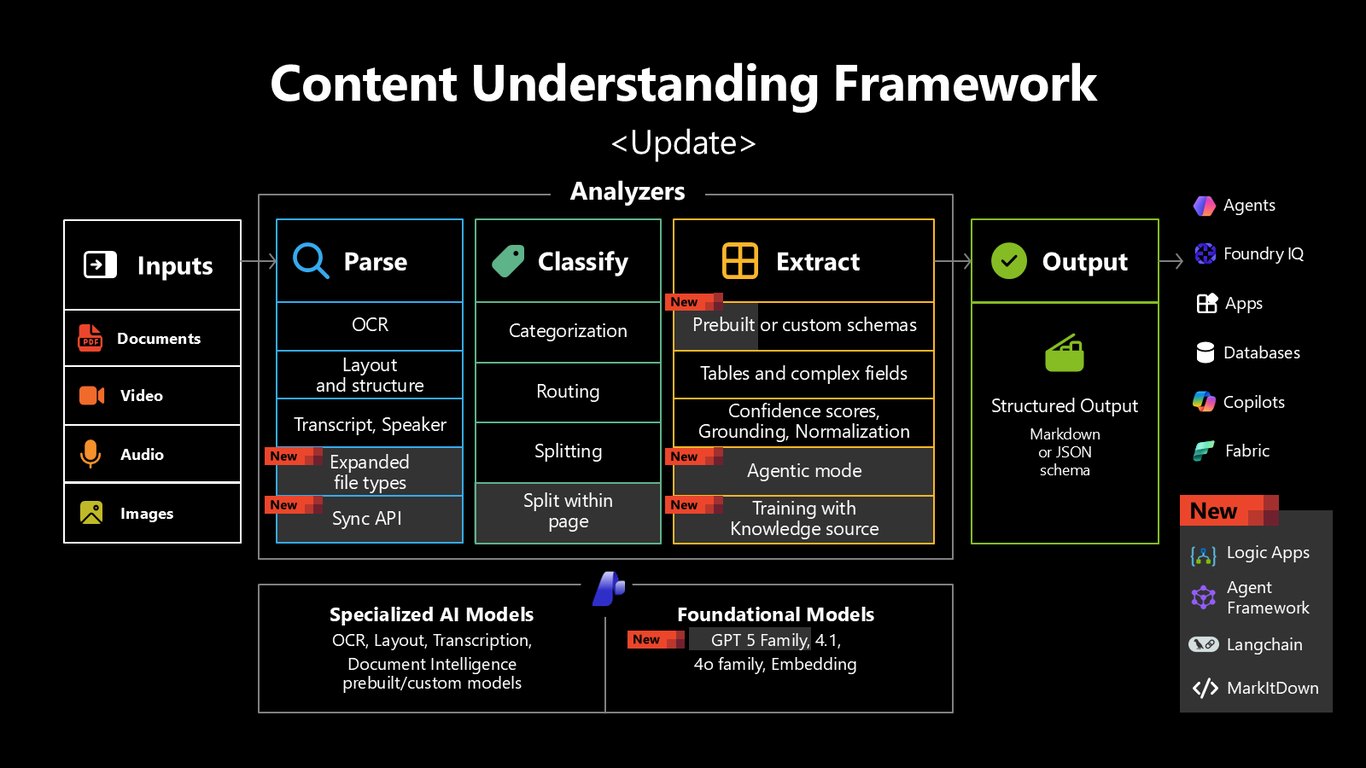
각 단계를 떠받치는 특화 모델
Content Understanding의 각 단계는 특화된 모델들로 구동됩니다. Parse와 Classify, Extract는 OCR과 layout, transcription 같은 전문 모델, 그리고 GPT-5 계열 같은 파운데이션 모델 위에서 동작하는데요, 지금은 GPT-5.2를 쓰고 GPT-5.1과 5.5도 곧 들어옵니다. 계속 새 기능을 더하며 발전시키고 있습니다.

Parse — 업계 최고의 OCR·Layout
먼저 Parse입니다. 여기엔 Microsoft가 20년 넘게 다듬어 온, 지금도 최고 수준인 OCR과 layout 기술이 들어갑니다. 표와 다이어그램, 제목, 그림은 물론 구겨진 종이 같은 까다로운 경우까지 정교하게 뽑아내고요, 이게 Foundry IQ의 검색 인제스천 기반이 됩니다.
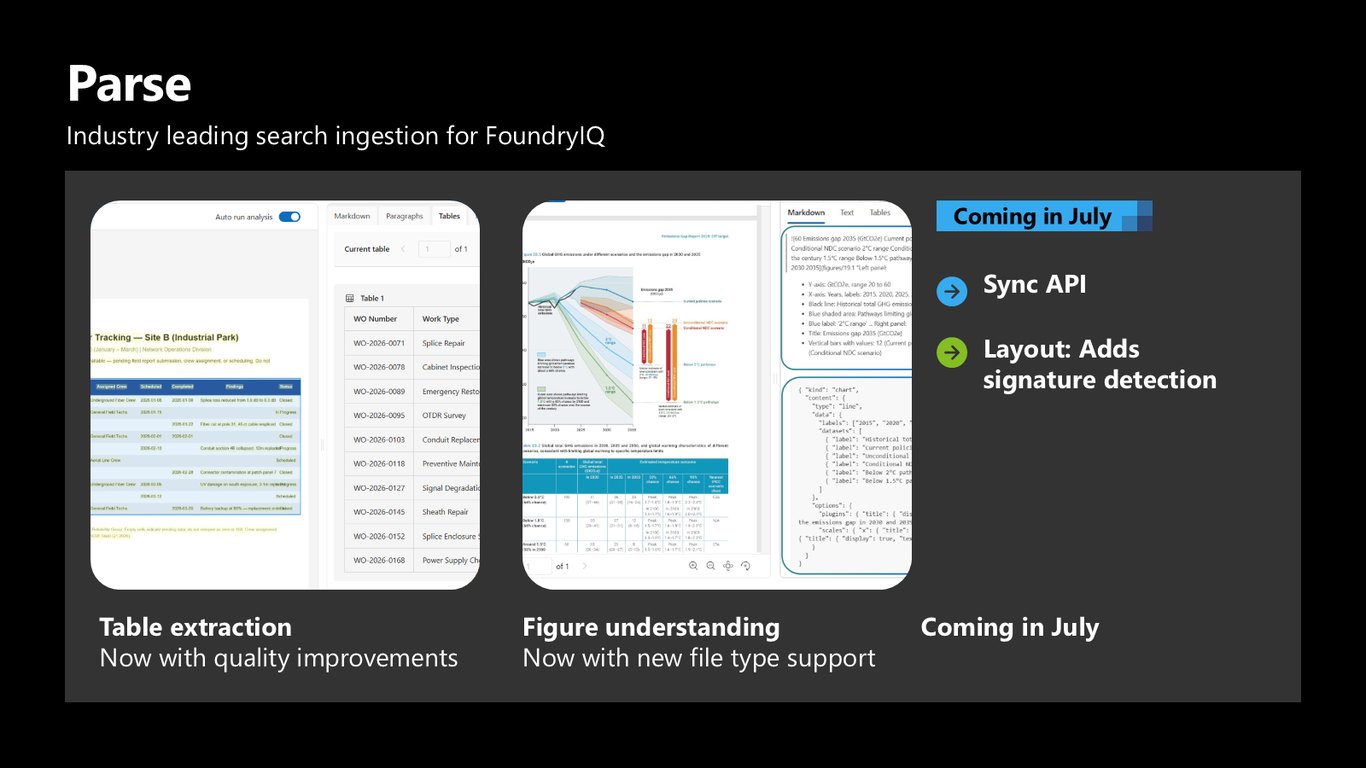
Parse — Foundry IQ를 위한 검색 인제스천
Foundry IQ는 이 Parse의 표 추출을 활용합니다. 덕분에 예전엔 불가능했던, 표 안의 세부 질문에도 RAG가 답할 수 있게 됐죠. 그림 이해는 새로운 파일 형식까지 지원하고, 7월엔 짧은 문서를 인라인으로 바로 처리하는 sync API와 서명 감지 같은 기능이 추가됩니다.
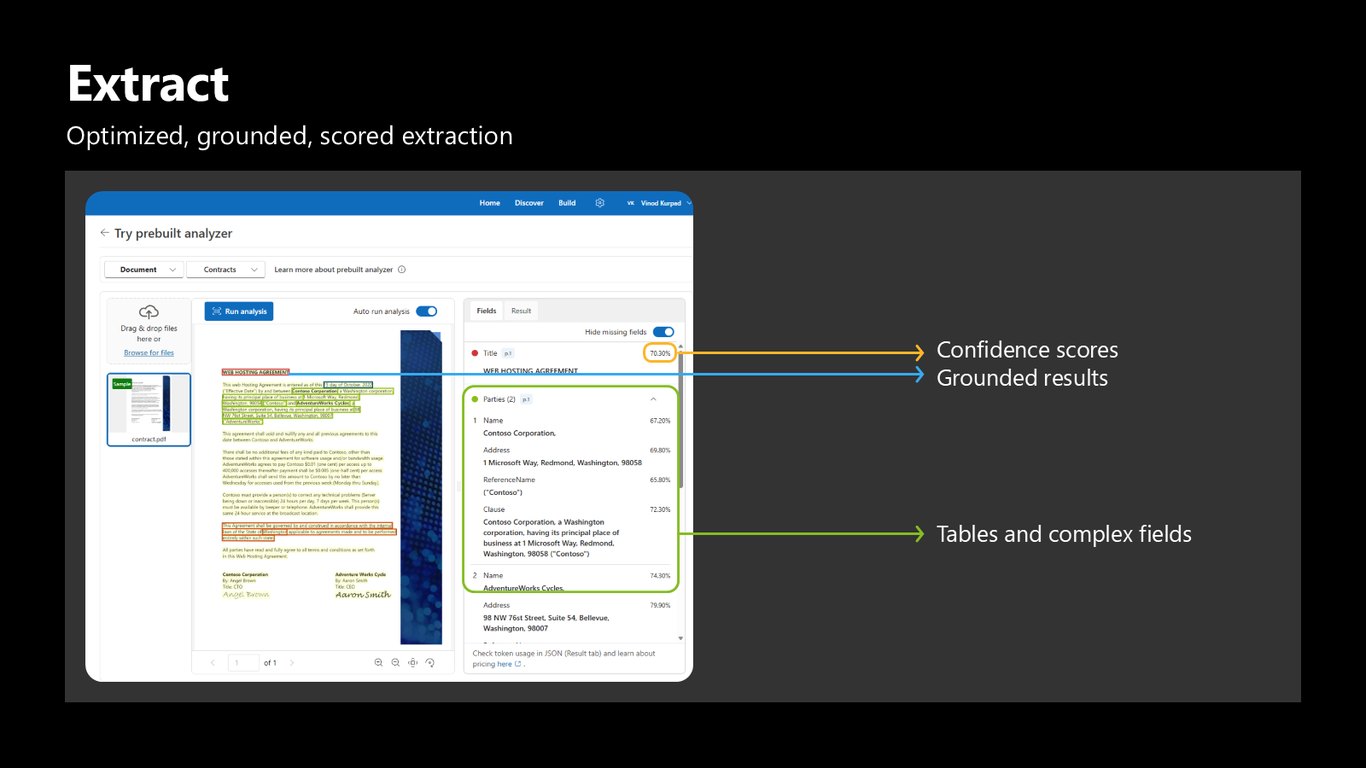
Extract — 근거와 점수가 붙은 추출
Extract는 파싱된 콘텐츠를 구조화된 필드와 스키마 출력으로 바꿉니다. 키-값과 표, 복잡한 객체까지 뽑아내고, 모든 필드에 신뢰도 점수와 근거를 붙이죠. 값이 문서의 특정 위치를 가리키기 때문에, 신뢰도가 높으면 자동 승인하고 낮으면 사람 검토로 넘기고, 언제든 원본까지 추적할 수 있습니다. 추측이 아니라 근거 있는 결과인 겁니다.

긴 복합 문서를 이해하기
Classify는 문서 유형을 식별하고 큰 파일을 조각으로 나눕니다. 대출 서류나 사건 파일처럼, 사실 하나의 문서가 아니라 여러 문서가 묶인 패키지가 많거든요. 이걸 분해해서 각 조각에 맞는 추출 로직을 적용합니다. 7월엔 페이지 경계뿐 아니라 섹션 단위로도 나눌 수 있게 됩니다.
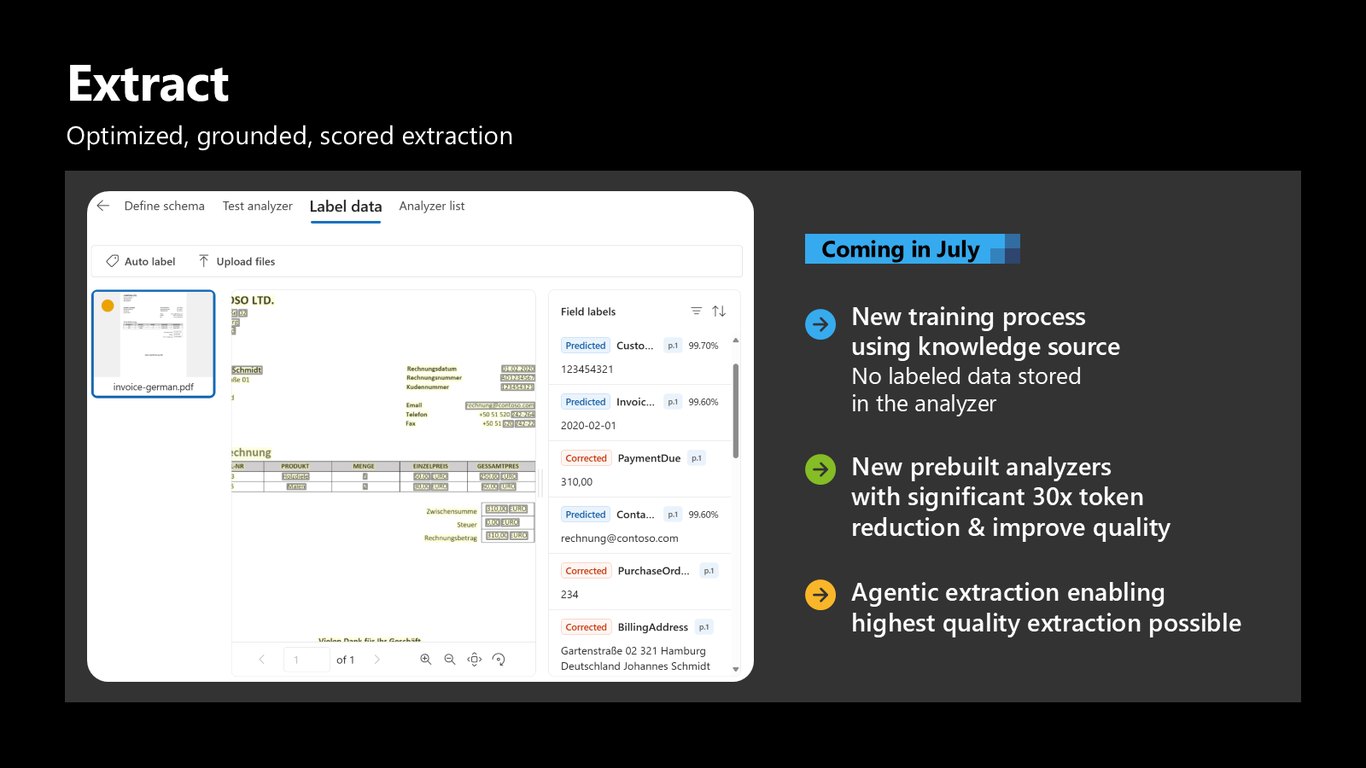
Extract — 새 학습과 에이전틱 추출
Extract에는 7월에 지식 소스를 활용한 새 학습 방식이 들어옵니다. 세금 양식이나 작업 지시서처럼 중요한 문서에 예시를 주면, 그 시나리오의 품질을 끌어올릴 수 있죠. 라벨 데이터는 분석기에 저장되지 않고요. 여기에 토큰을 30배 줄인 새 프리빌트 분석기, 그리고 가능한 최고 품질을 뽑아내는 에이전틱 추출도 함께 옵니다.

Extract 에이전틱 모드
마지막으로 에이전틱 모드입니다. 답이 문서 안에 이미 있는 게 아니라, 근거를 넘나들며 단계적으로 만들어내야 하는 가장 어려운 문제를 위한 기능이죠. 예를 들어 여러 수정 계약을 종합해 지금 어떤 조항이 유효한지, A와 B를 비교하면 어떤지 같은 질문 말입니다. 아직 개발 중이라 짧은 녹화 데모로 개념을 보여드립니다.
세션 진행 구성 (내부용)
참고로 이건 세션을 준비하며 정리한 내부 진행 계획입니다. 45분을 문제 제기와 데모, 마무리로 어떻게 배분했는지 담고 있는, 발표 자체보다는 준비 과정의 뼈대라고 보시면 됩니다. 오늘 함께해 주셔서 감사합니다.