
오늘은 AI 앱과 에이전트를 위한 데이터베이스를 어떻게 설계해야 하는지 이야기해 보겠습니다. Charles, Abe, Bob, James, 이렇게 네 명이 함께 Azure Cosmos DB, Azure SQL, Azure HorizonDB를 차례로 보여드릴 텐데요, 단순히 데이터를 저장하는 걸 넘어 그 데이터를 추론에 쓰는 방향으로 넘어가 보겠습니다.
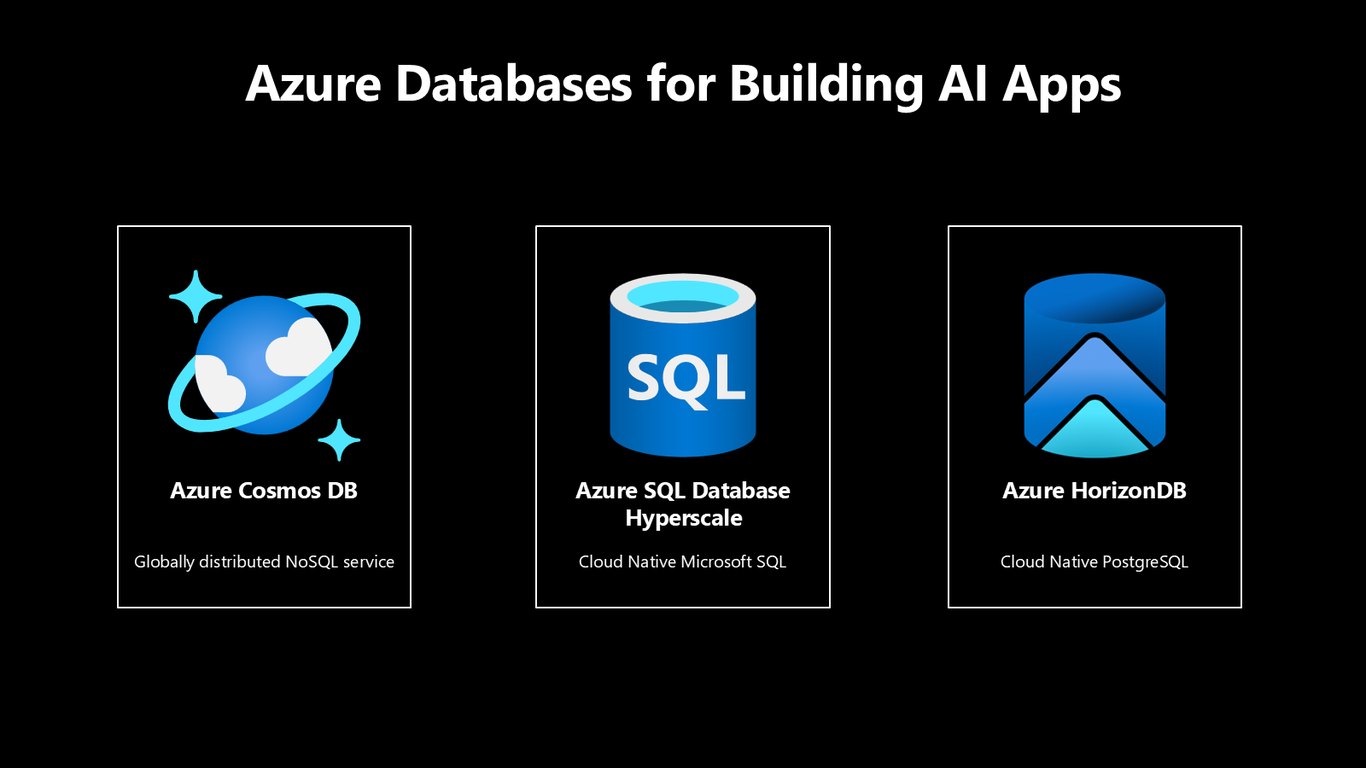
AI 앱을 위한 Azure 데이터베이스
AI 앱을 만들 때 쓸 수 있는 Azure 데이터베이스는 크게 세 가지입니다. 글로벌하게 분산되는 NoSQL인 Azure Cosmos DB, 클라우드 네이티브 SQL인 Azure SQL Database Hyperscale, 그리고 클라우드 네이티브 PostgreSQL인 Azure HorizonDB죠. 워크로드에 맞춰 골라 쓰시면 됩니다.

핵심 데이터베이스 투자
세 제품 모두 이번에 정말 많은 기능이 GA와 Preview로 쏟아졌습니다. Cosmos DB는 글로벌 보조 인덱스와 분산 트랜잭션, SQL은 GitHub Copilot 통합과 SSMS 에이전트 모드, PostgreSQL은 마이그레이션 도구와 HorizonDB Preview까지요. 자세한 링크는 각 aka.ms 주소에 정리해 뒀습니다.
모든 데모 코드는 GitHub에
오늘 보여드릴 데모 코드는 전부 GitHub에 올려 뒀습니다. aka.ms/build26/BRK223에서 그대로 받아 직접 돌려보실 수 있으니 편하게 활용하세요.
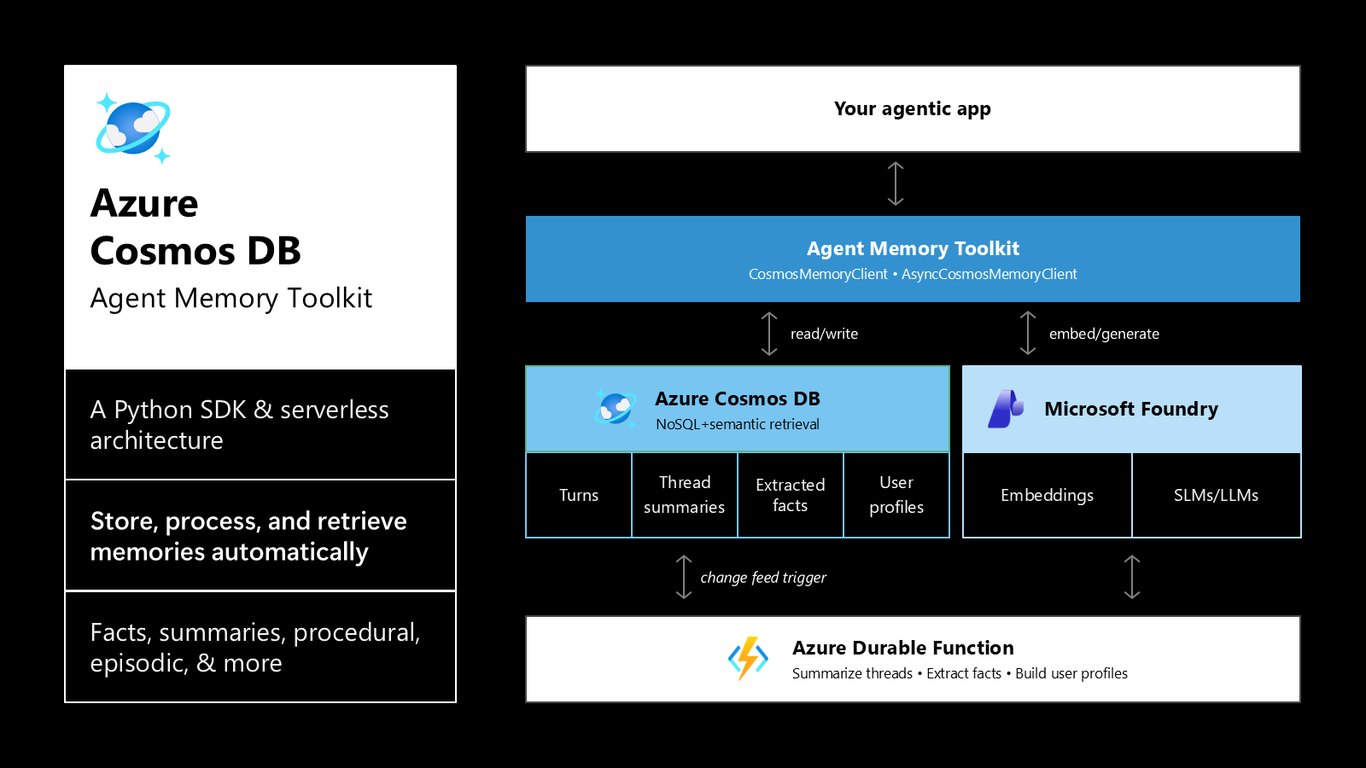
먼저 Cosmos DB부터 살펴보겠습니다. 새로 나온 Agent Memory Toolkit은 에이전트의 기억을 자동으로 관리해 주는데요, Python SDK와 서버리스 아키텍처로 대화 턴을 저장하고, Durable Function이 스레드를 요약하고 사실을 추출해 사용자 프로필까지 만들어 줍니다. 사실, 요약, 절차적·에피소드 기억을 Cosmos DB가 알아서 저장하고 검색해 줍니다.
데모 · James Codella
그럼 James가 직접 어떻게 동작하는지 보여드리겠습니다. Agent Memory Toolkit이 실제로 기억을 쌓고 꺼내 쓰는 모습을 함께 보시죠.
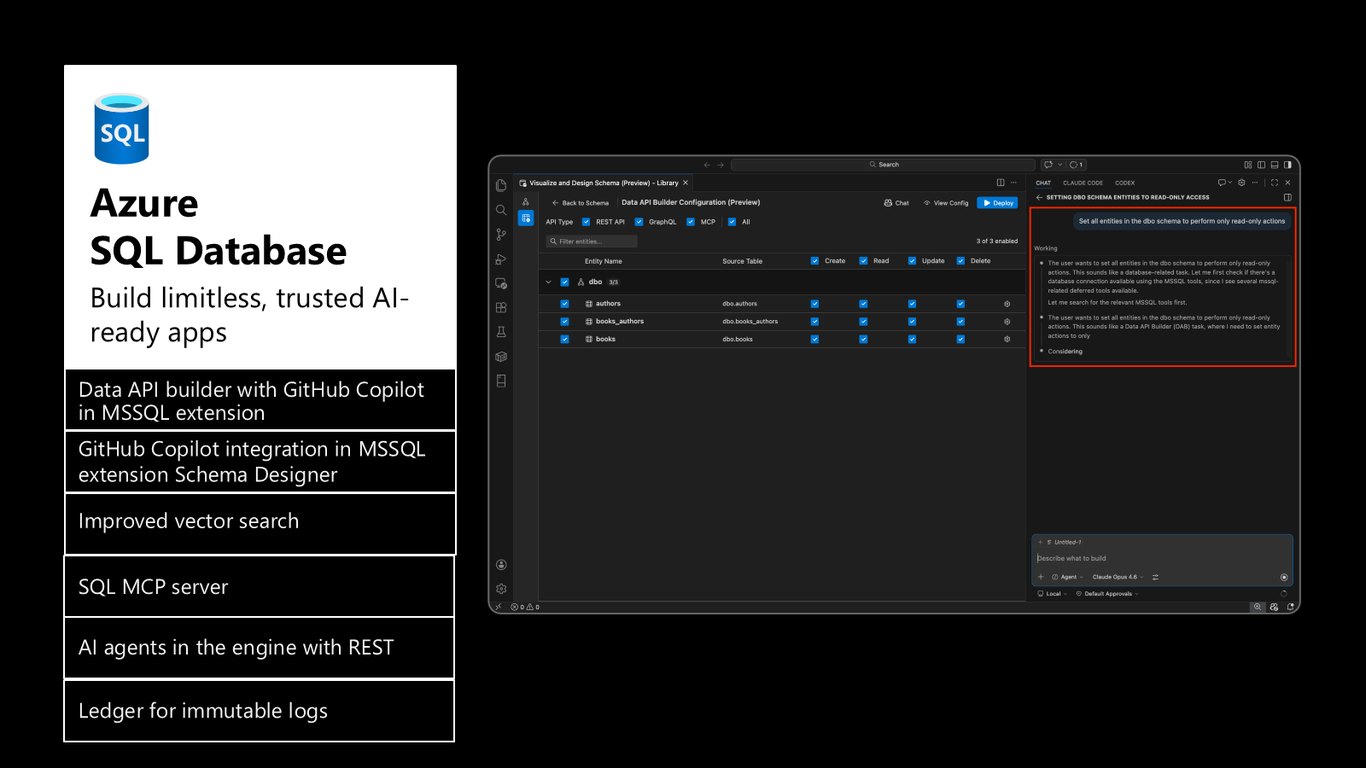
다음은 Azure SQL Database입니다. 신뢰할 수 있으면서 AI를 바로 얹을 수 있는 앱을 무한히 확장해서 만들 수 있는데요, MSSQL 확장의 Data API builder와 Copilot 통합, 향상된 벡터 검색, SQL MCP server, 엔진 안에서 REST로 도는 AI 에이전트, 그리고 변경 불가능한 로그를 위한 Ledger까지 준비돼 있습니다.

데모 · Bob Ward
이제 Bob이 Azure SQL과 AI로 실제 라이브사이트를 어떻게 지원하는지 보여드리겠습니다. 운영 현장에서 벌어지는 문제를 데이터베이스가 직접 풀어내는 흐름을 따라가 보시죠.

Zava 온콜 엔지니어의 고민
Zava의 온콜 엔지니어를 한번 떠올려 보겠습니다. 운영 데이터, 그걸 설명해 주는 런북, 그리고 그 위에서 추론할 AI가 전부 따로 놀고 있죠. 새벽에 SEV1 장애가 터지고 배치 작업에서 데드락이 몰아치는데요, 만약 이 네 가지가 전부 데이터베이스 한곳에 있다면 어떨까요?
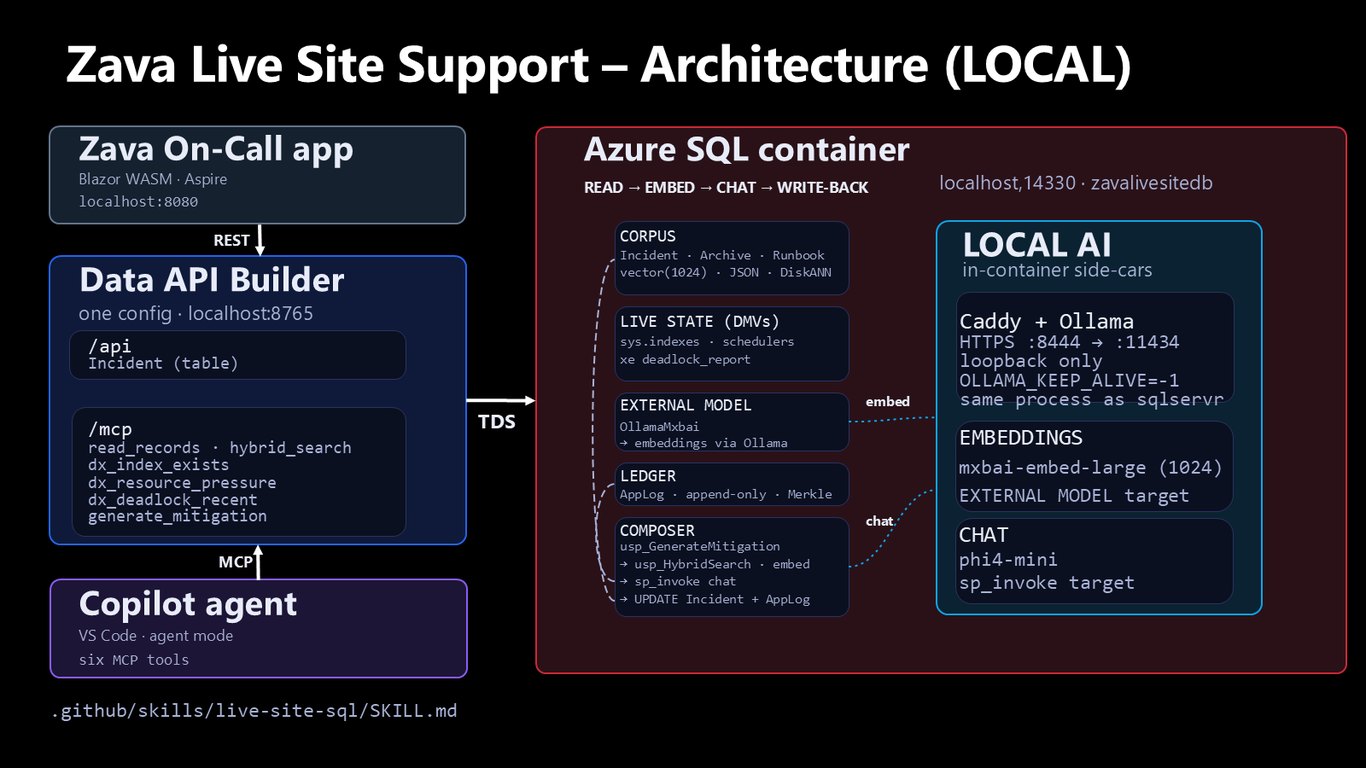
아키텍처 (로컬)
먼저 로컬 환경 구성입니다. Blazor 앱과 VS Code의 Copilot 에이전트가 여섯 개의 MCP 도구를 통해 Data API Builder로 Azure SQL 컨테이너에 붙는데요, 인시던트와 런북을 벡터와 DiskANN으로 저장하고, 컨테이너 안 사이드카로 Ollama 임베딩과 채팅 모델을 돌립니다. 읽고, 임베딩하고, 추론하고, 다시 써넣는 흐름이 전부 한 곳에서 이뤄집니다.
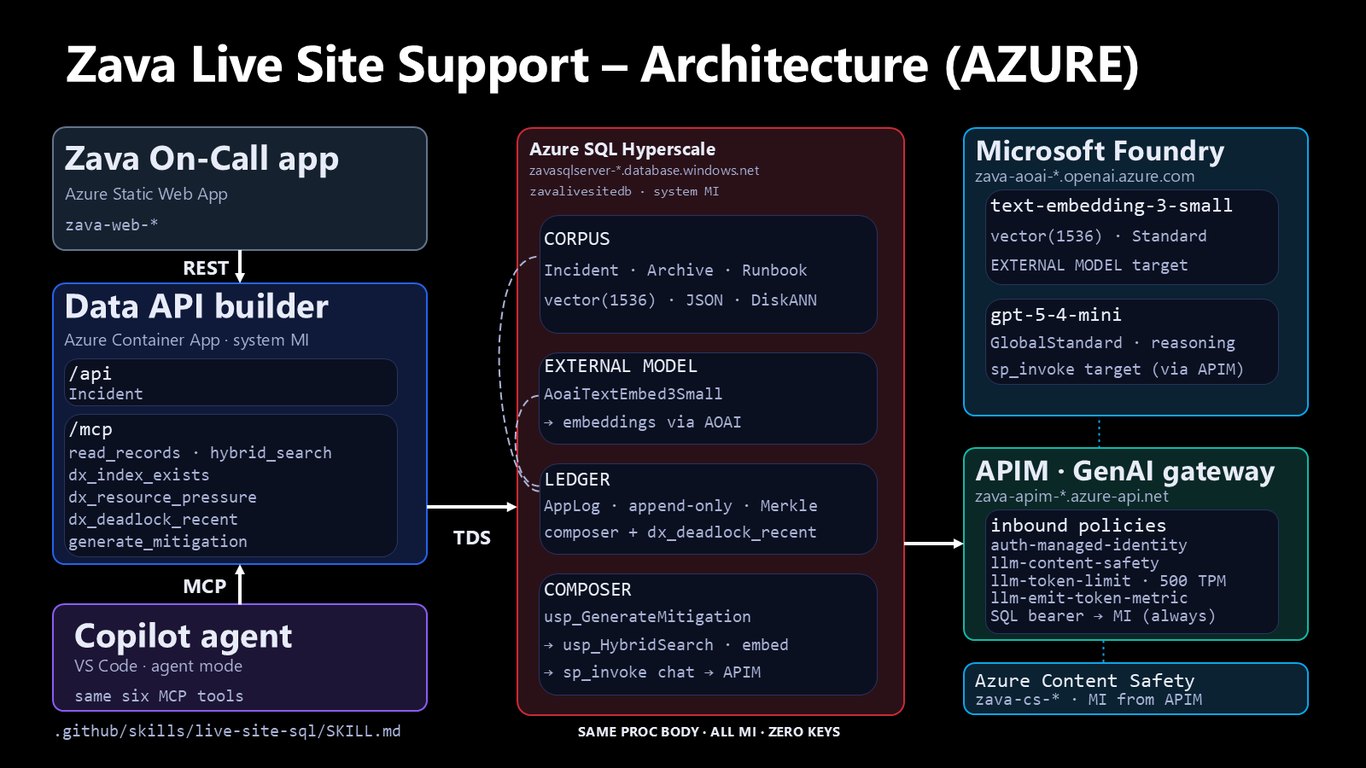
아키텍처 (Azure)
똑같은 앱과 똑같은 프로시저를 이번엔 Azure로 그대로 올립니다. Hyperscale과 APIM GenAI 게이트웨이, Microsoft Foundry를 붙이고, 전부 관리 ID로 인증하니 키가 하나도 없습니다. APIM에서 콘텐츠 안전성과 토큰 제한 정책까지 걸리고요, 코드는 한 줄도 안 바꾸고 클라우드로 넘어갑니다.

SQL Database dev container
개발 경험도 한층 좋아졌습니다. Azure SQL Database dev container가 private preview로 나와서, 클라우드용 SQL 앱을 로컬에서 그대로 만들고 테스트할 수 있는데요, VS Code와 Docker, WSL과 연동되고 x64와 ARM 모두 지원합니다. aka.ms/sqldbcontainerpreview-signup에서 신청하세요.

이제 PostgreSQL 이야기로 넘어가 보겠습니다. Microsoft가 PostgreSQL에 어떻게 기여하고 있고, 그 위에서 무엇을 만들고 있는지 살펴보시죠.

PostgreSQL 생태계 기여
Microsoft는 PostgreSQL 생태계에 여러 방식으로 기여하고 있습니다. Azure Database for PostgreSQL과 HorizonDB 같은 제품은 물론이고, POSETTE 행사, Talking Postgres 팟캐스트, VS Code용 확장, 그리고 업스트림 코드 기여까지 커뮤니티 전반을 함께 키워가고 있죠.

Postgres 19 기여
구체적인 숫자로 보면, Postgres 19에 Microsoft가 커밋의 약 11%인 345건, 코드 변경의 약 8%인 6만 4천 라인을 기여했습니다. 쿼리 엔진, 비동기 IO, 관측성 같은 핵심 영역에 실제로 손을 대고 있다는 뜻입니다.

Azure Database for PostgreSQL GA
Azure Database for PostgreSQL은 관리형 오픈소스 PostgreSQL로 GA 됐습니다. 포크 없이 주요 버전을 출시 첫날부터 쓸 수 있고, 완전한 엔터프라이즈 보안과 데이터 보호, 그리고 70개가 넘는 확장을 지원합니다.

지속적인 기능 제공
게다가 이건 한 번 만들고 끝나는 게 아닙니다. Azure Database for PostgreSQL은 새로운 기능을 꾸준히, 계속해서 앞으로 밀어붙이고 있습니다.
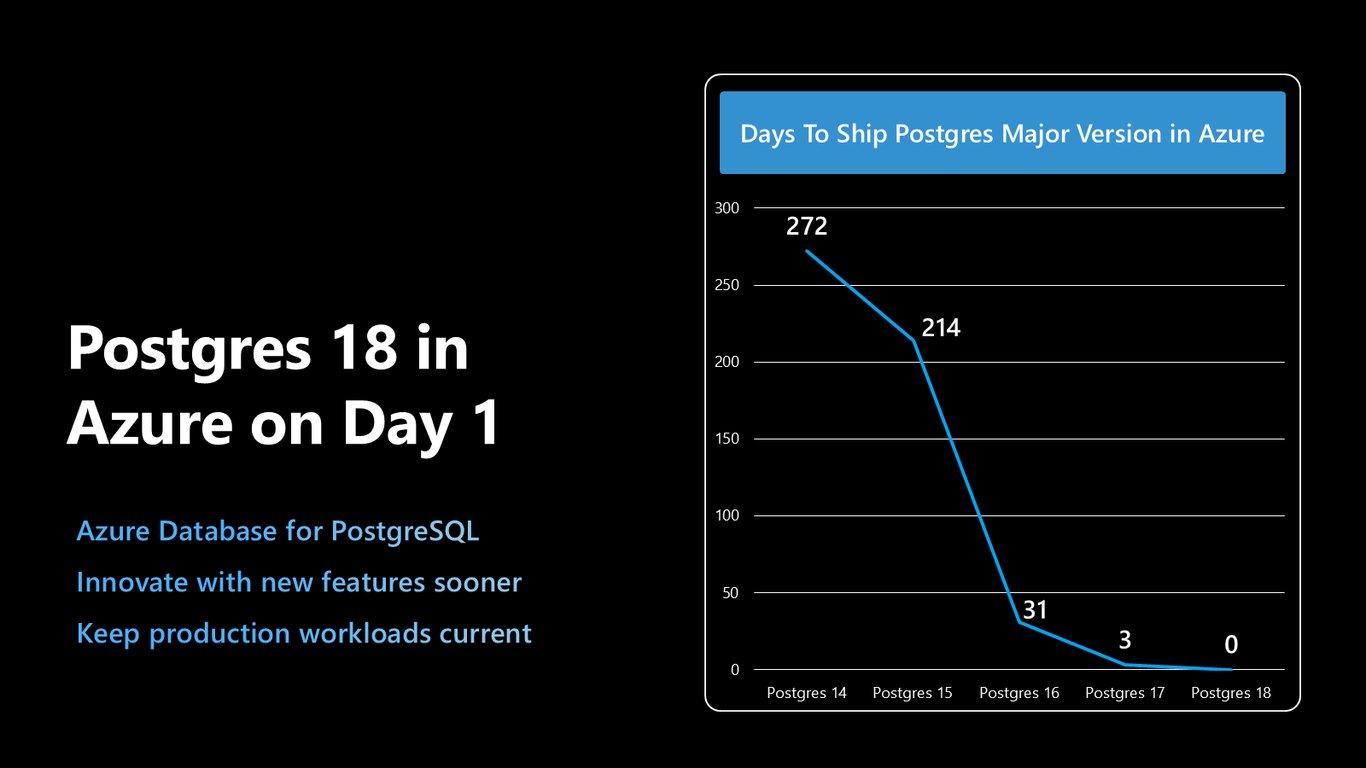
출시 첫날 Postgres 18 지원
그 속도를 잘 보여주는 게 Postgres 18입니다. Azure에서는 주요 버전을 출시 첫날 바로 쓸 수 있는데요, 덕분에 새 기능을 더 일찍 도입하면서도 운영 워크로드를 최신 상태로 유지할 수 있습니다.

자, 오늘의 하이라이트인 Azure HorizonDB를 소개하겠습니다. public preview로 공개됐고, 엔터프라이즈에 바로 쓸 수 있으면서 개발자를 위해 설계됐는데요, 내장 AI 함수와 파이프라인, 셀프 매니지드 대비 최대 3배 빠른 OLTP와 벡터 검색, 그리고 128TB까지 자동 확장되는 존 복원 스토리지를 갖췄습니다.

HorizonDB 소개 영상
먼저 영상으로 HorizonDB가 어떤 서비스인지 한눈에 보여드리겠습니다. 시작부터 확장까지, 개발자 워크플로에 어떻게 녹아드는지 함께 보시죠.
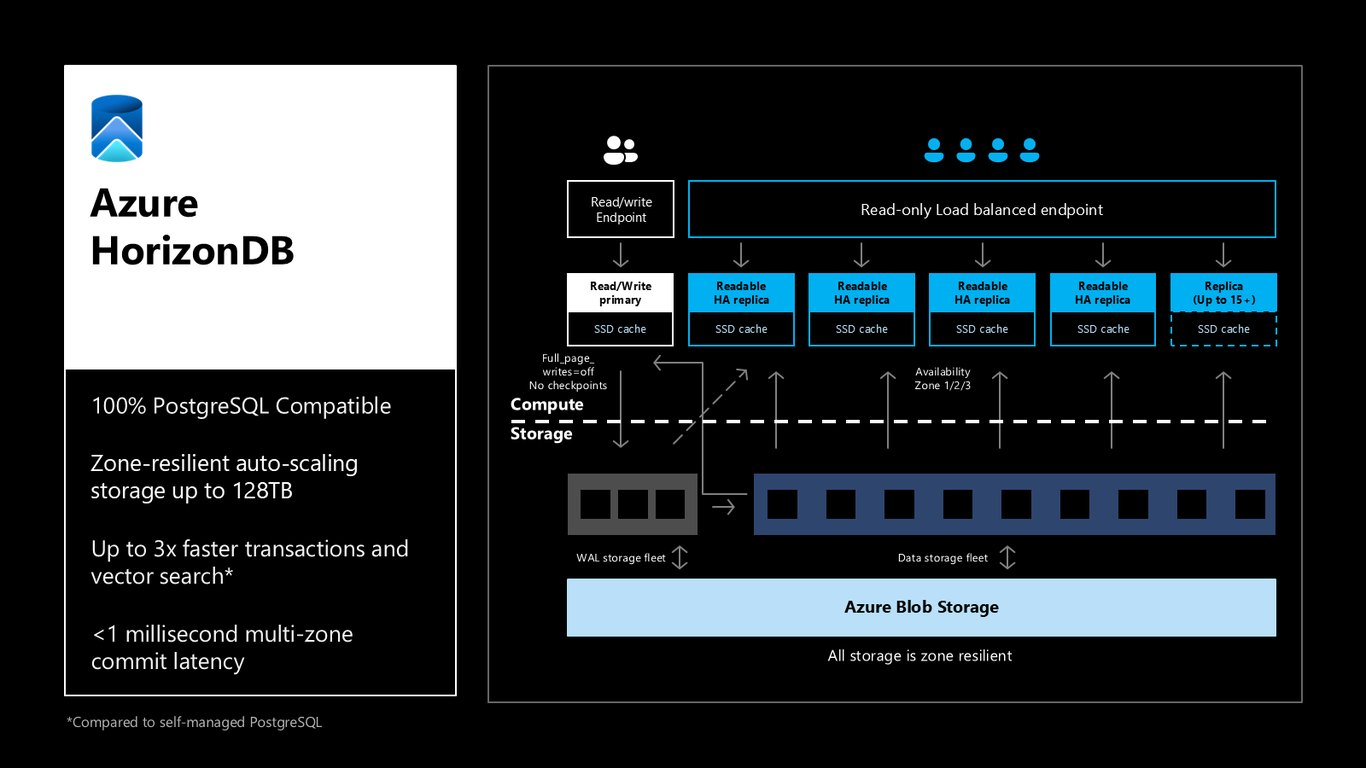
HorizonDB 아키텍처
HorizonDB는 100% PostgreSQL 호환입니다. 컴퓨트와 스토리지를 분리하고, 읽기/쓰기 프라이머리와 최대 15개 이상의 읽기 복제본을 두는데요, 모든 스토리지가 존 복원형이라 멀티 존 커밋 지연이 1밀리초 미만입니다. 128TB까지 자동 확장되는 구조 덕분에 성능과 안정성을 동시에 가져갑니다.

데모 · 성능
말로만 3배 빠르다고 하면 와닿지 않으실 테니, 실제 성능을 데모로 직접 보여드리겠습니다.
데모
HorizonDB가 부하 아래에서 트랜잭션과 벡터 검색을 얼마나 빠르게 처리하는지 화면으로 함께 확인해 보시죠.
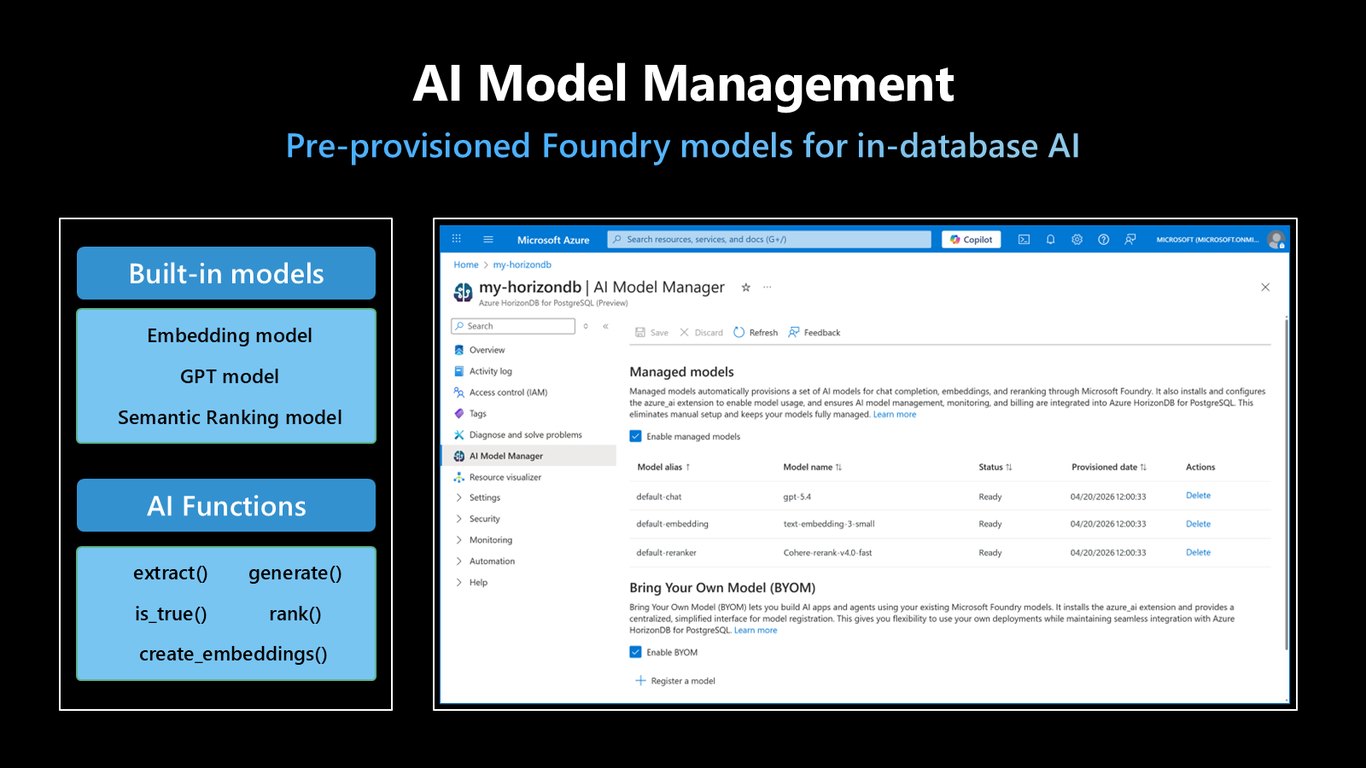
AI 모델 관리
HorizonDB는 AI를 데이터베이스 안으로 직접 가져옵니다. Foundry 모델을 미리 프로비저닝해 두고, 임베딩·GPT·시맨틱 랭킹 모델을 데이터베이스 안에서 바로 쓸 수 있는데요, extract, generate, rank, create_embeddings 같은 AI 함수를 SQL에서 그대로 호출하면 됩니다.
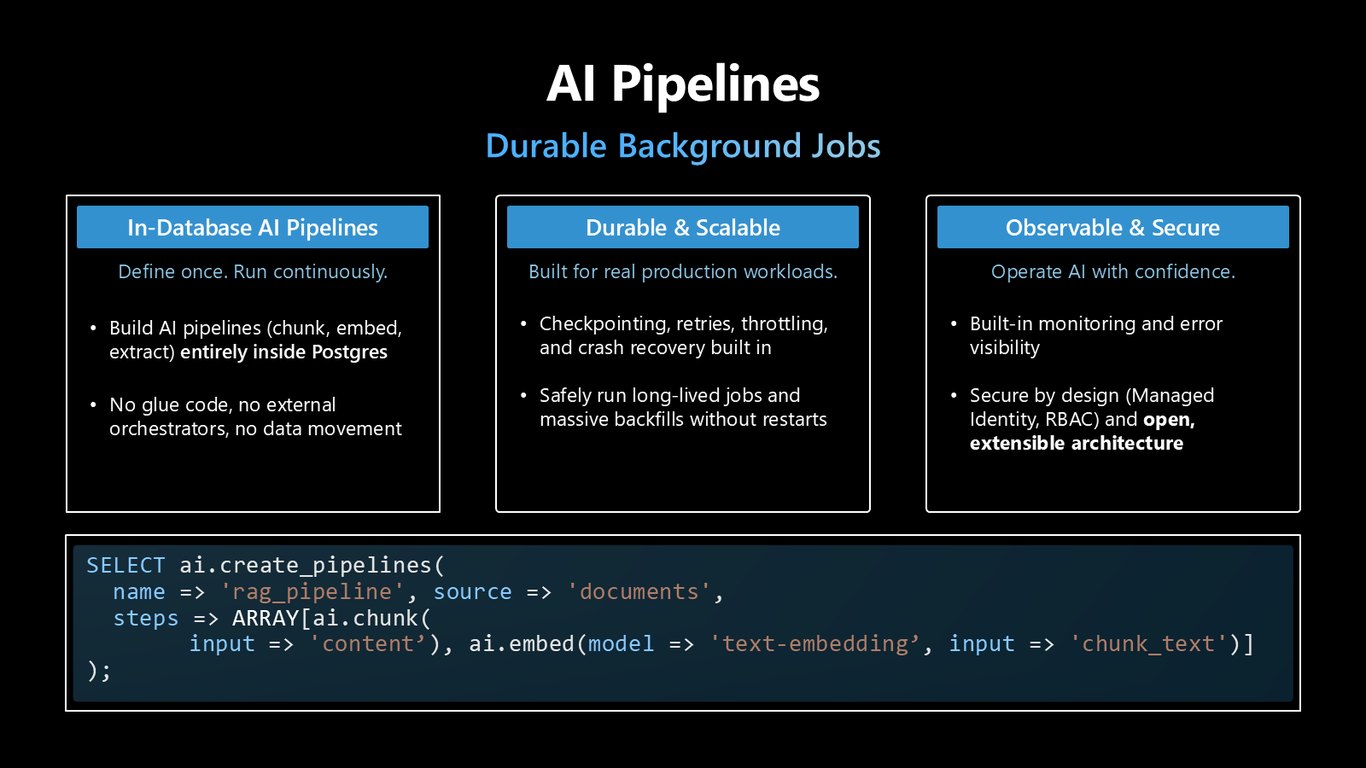
AI 파이프라인
더 나아가 AI 파이프라인을 Postgres 안에서 정의할 수 있습니다. 청킹, 임베딩, 추출을 한 번 정의해 두면 계속 돌아가는데요, 글루 코드나 외부 오케스트레이터, 데이터 이동이 전혀 필요 없습니다. 체크포인트와 재시도, 크래시 복구가 내장돼 있어서 오래 걸리는 대규모 작업도 안전하게 돌릴 수 있죠.

AI 파이프라인 예시
실제 코드는 이렇게 간단합니다. create_pipeline 하나로 소스 테이블을 지정하고, 청크 크기와 임베딩 모델, 차원, 배치 크기를 정하고, 변경이 생길 때마다 자동으로 돌게 트리거를 걸면 끝입니다. 결과는 지정한 싱크 테이블로 들어갑니다.
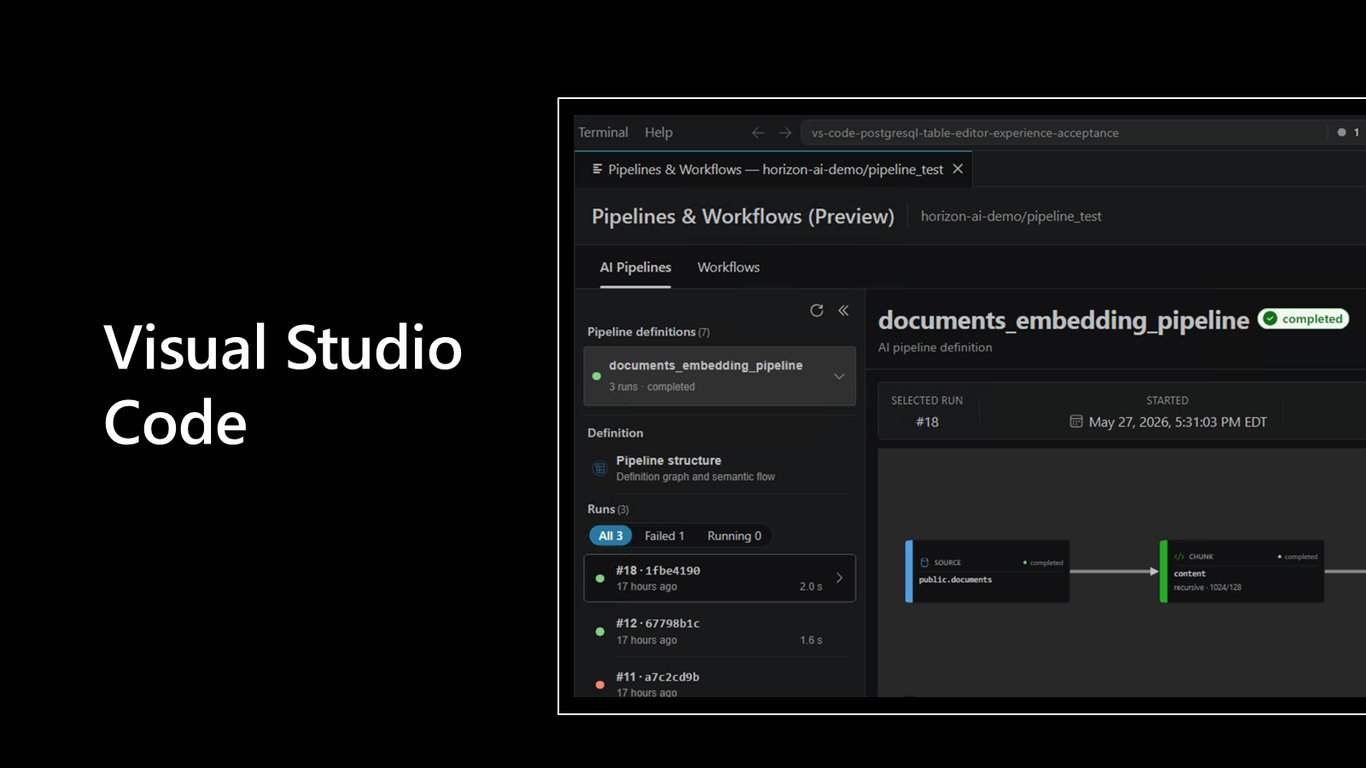
Visual Studio Code 경험
이 모든 걸 Visual Studio Code 안에서 편하게 다룰 수 있습니다. 에디터를 떠나지 않고 HorizonDB를 개발하고 관리하는 경험을 보여드리겠습니다.
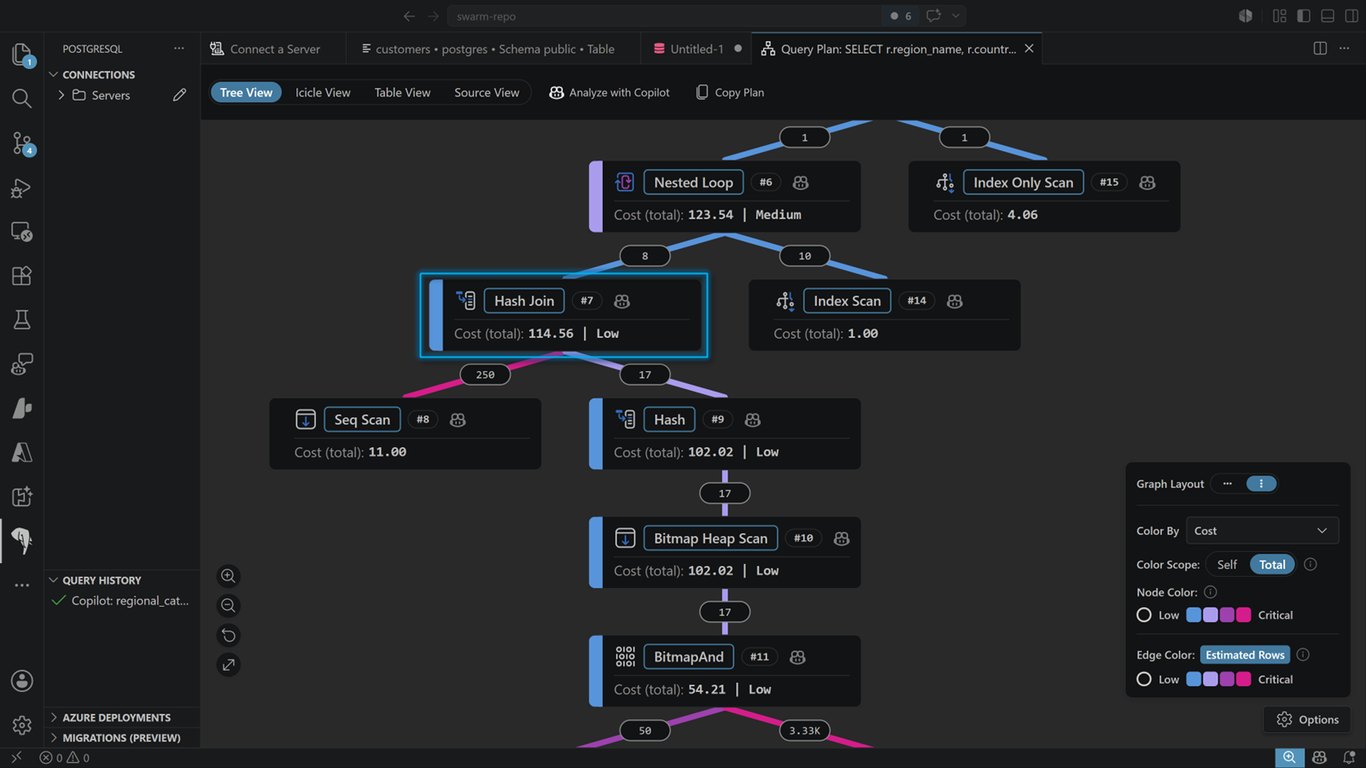
데모
VS Code에서 HorizonDB에 연결해 실제로 작업하는 모습을 함께 보시죠.
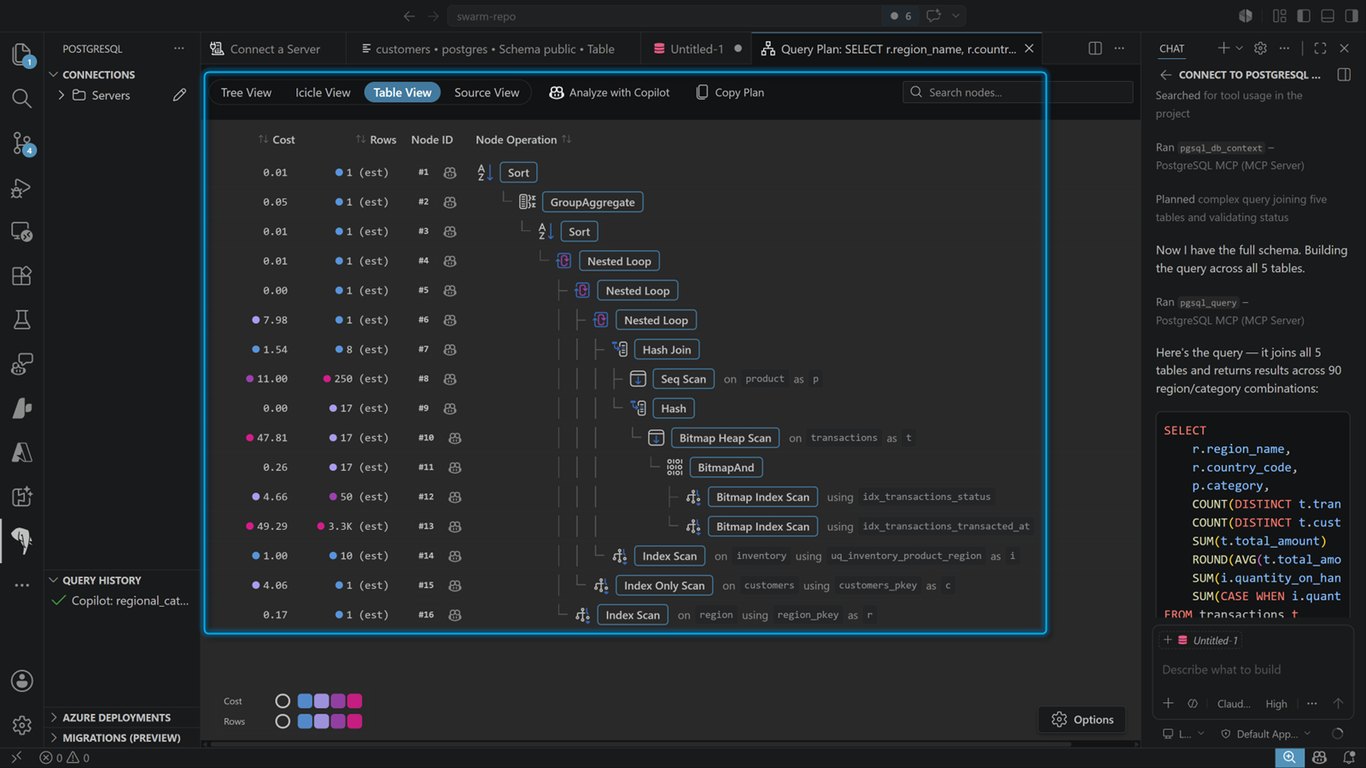
데모
이어서 AI 함수와 파이프라인을 데이터베이스 안에서 어떻게 활용하는지 계속 보여드리겠습니다.
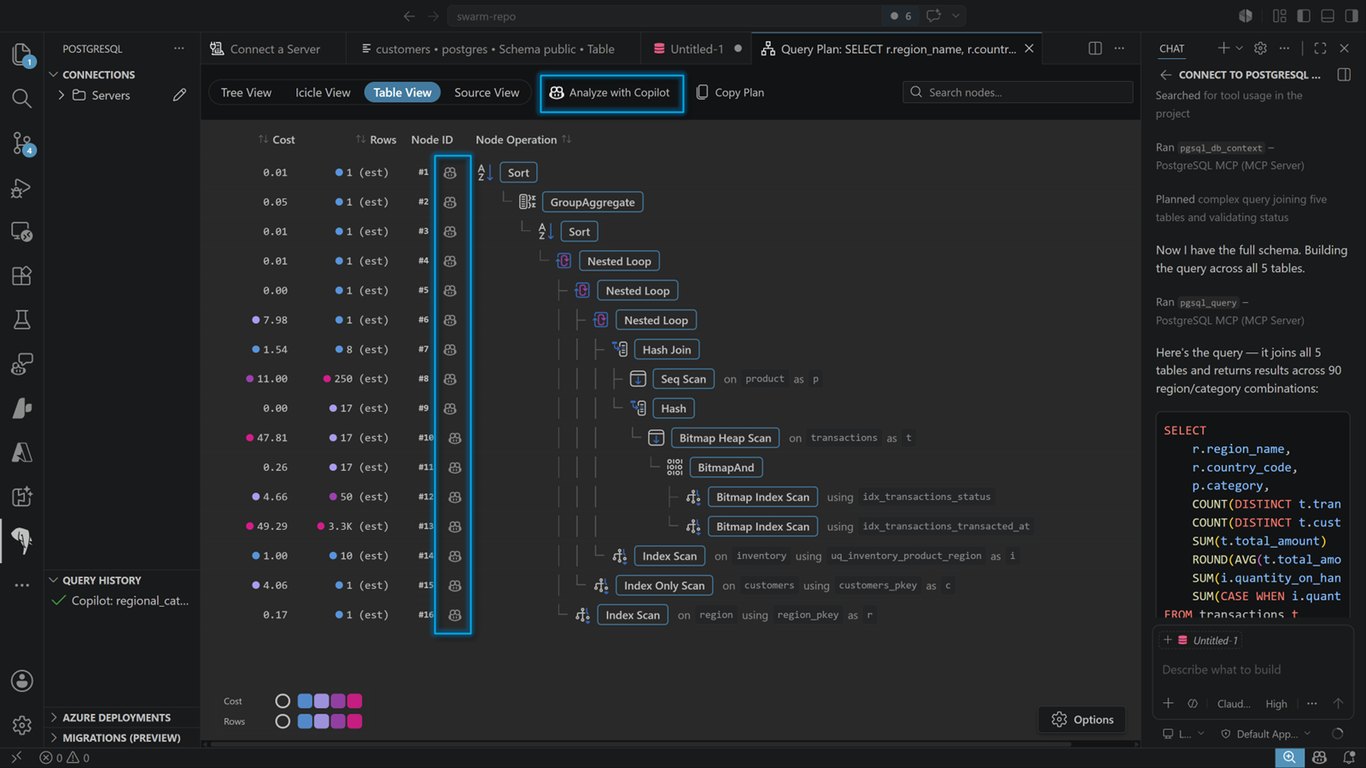
데모
파이프라인이 데이터를 수집하고 임베딩하는 과정을 실제 화면으로 확인해 보시죠.

데모 · Zava Room Designer Agent
마지막으로 Abe가 Zava Room Designer Agent를 보여드립니다. HorizonDB 위에서 실제 AI 네이티브 에이전트가 어떻게 동작하는지 직접 보시죠.

HorizonDB로 만드는 AI 네이티브 앱
정리하면, HorizonDB 하나로 AI 스택의 모든 계층을 덮을 수 있습니다. 데이터를 수집하고 풍부하게 만드는 파이프라인, 데이터를 찾는 하이브리드 검색, 데이터를 연결하는 그래프, 그리고 그 위에서 추론하는 내장 AI 모델까지요. Postgres 데이터베이스 하나로 전부 됩니다.
다시 정리해 보면, 오늘 살펴본 세 가지 선택지가 있습니다. 글로벌 분산 NoSQL인 Azure Cosmos DB, 클라우드 네이티브 SQL인 Azure SQL Database Hyperscale, 그리고 클라우드 네이티브 PostgreSQL인 Azure HorizonDB죠. 워크로드에 맞는 걸 고르시면 됩니다.
모든 데모 코드는 GitHub에
오늘 보여드린 데모 코드는 전부 aka.ms/build26/BRK223에 있습니다. 세션이 끝나고 직접 받아서 돌려보세요.

Build의 다른 세션들
더 깊이 파고들고 싶으시다면 Build의 다른 세션들도 챙겨보시길 권합니다. HorizonDB, Cosmos DB, Azure SQL 각각에 대해 랩과 데모, 라이트닝 토크가 준비돼 있으니 관심 있는 주제를 골라 들어보세요.

피드백 부탁드립니다
세션 상세 페이지에서 튜토리얼과 자료, 코드를 바로 확인하실 수 있습니다. 그리고 aka.ms/build/evals에서 설문에 참여해 주시면 큰 도움이 됩니다.

감사합니다
감사합니다.