
안녕하세요. 오늘은 모델도, 비용도 끊임없이 바뀌는 환경에서 Microsoft Foundry로 어떻게 더 똑똑한 AI 시스템을 만들 수 있는지 이야기해 보겠습니다. 저는 Yina, 그리고 Naomi와 함께 진행합니다.

1년 전엔 쉬워 보였습니다
불과 1년 전만 해도 AI 앱을 만드는 건 꽤 단순해 보였습니다. 모델 하나 골라서 프롬프트만 잘 쓰면 되는 것처럼요.

지금은 훨씬 더 어려워졌습니다
그런데 지금은 상황이 달라졌죠. 모델과 도구 선택지는 폭발적으로 늘었고, 벤치마크는 오해를 부르고, 비용은 예측이 안 됩니다. 프로덕션은 어렵고, 시스템은 좀처럼 안정되지 않습니다.

여러분이 원하는 것
여러분이 진짜 원하는 건 명확합니다. 더 단순하게, 더 좋은 품질로, 더 저렴하게, 그리고 확장 가능하게. 결국 시스템 전체의 결과가 가장 좋아지길 바라시는 거죠.

여러분에게 필요한 것
그러려면 필요한 건 한 번 만들고 끝나는 앱이 아니라, 스스로 계속 개선되면서 여러분의 시간과 노력을 아껴 주는 프로덕션급 시스템입니다.
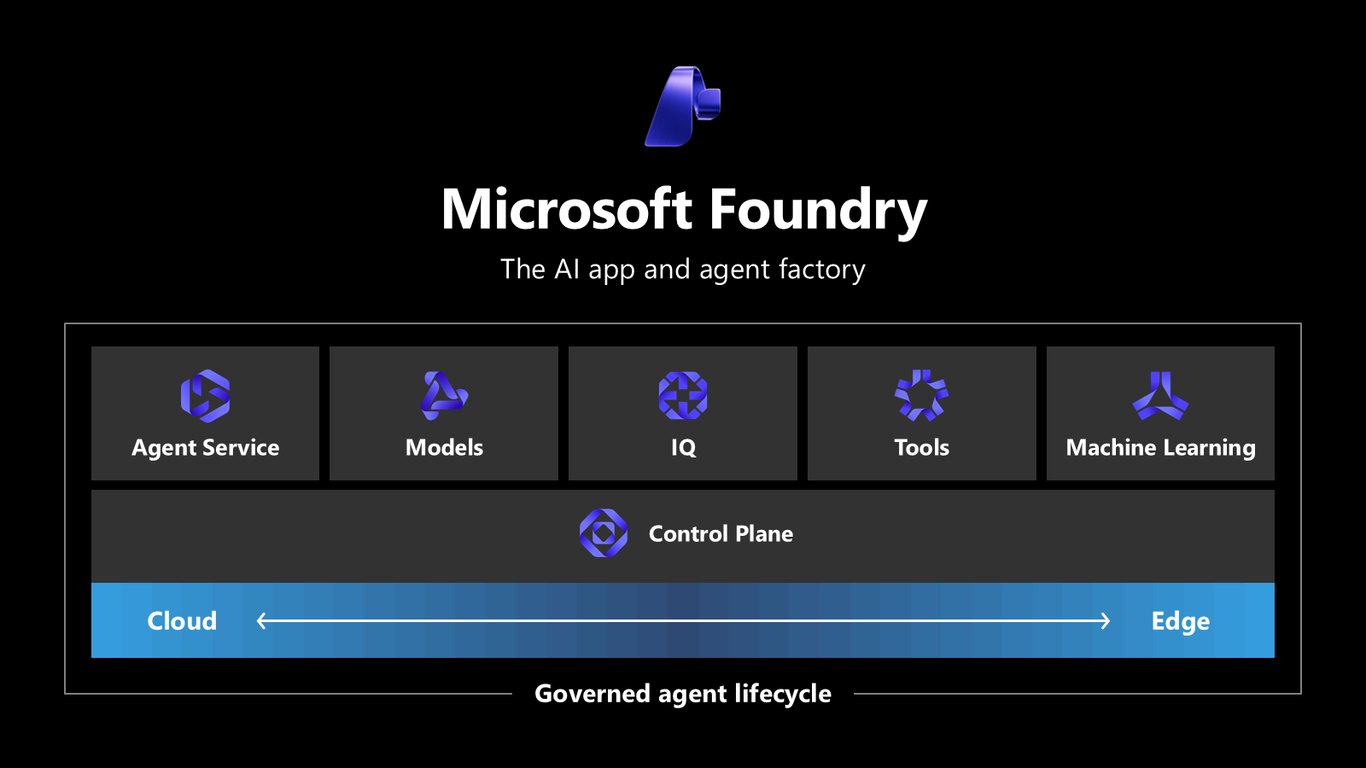
Microsoft Foundry: AI 앱·에이전트 팩토리
그 시스템을 만드는 곳이 바로 Microsoft Foundry입니다. Models, Tools, Agent Service, IQ, 그리고 거버넌스가 담긴 Control Plane까지, 클라우드부터 엣지까지 AI 앱과 에이전트를 찍어내는 팩토리라고 보시면 됩니다.
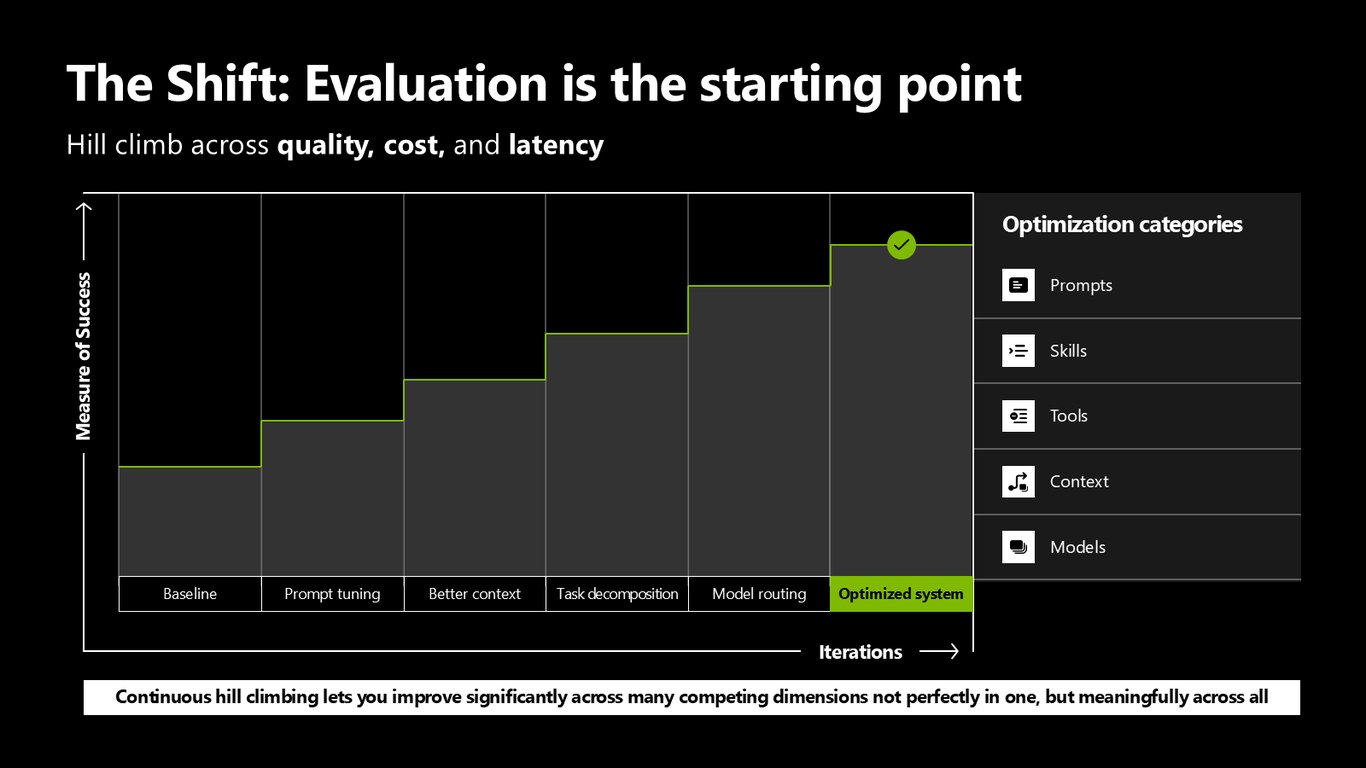
출발점은 평가입니다
핵심 전환은 평가가 출발점이 된다는 겁니다. 품질, 비용, 지연 사이를 한 번에 완벽하게가 아니라, 반복하면서 조금씩 언덕을 오르듯 올려 갑니다. 이게 hill climbing이에요.
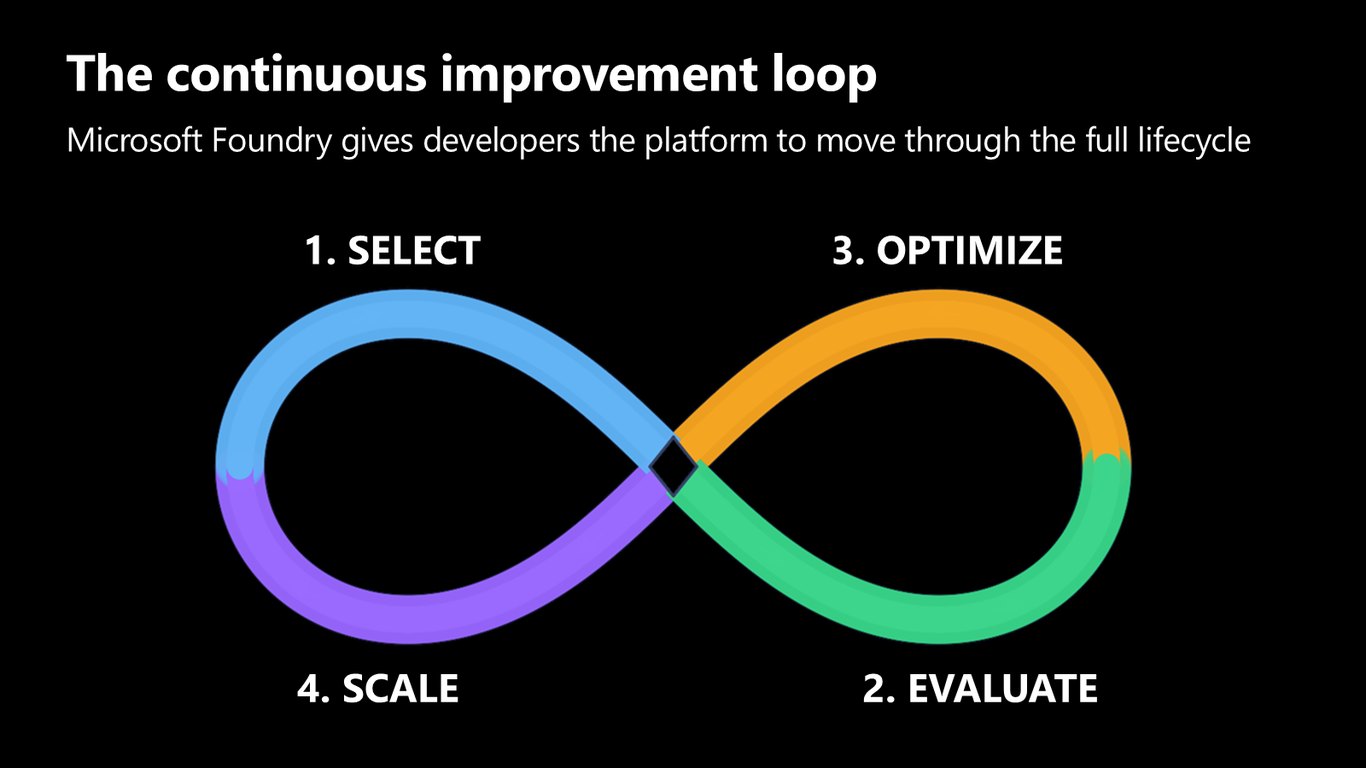
지속적 개선 루프
Foundry는 이 전 과정을 하나의 루프로 돌릴 수 있게 해 줍니다. Select, Evaluate, Optimize, Scale, 이 네 단계를 계속 돌면서 시스템을 발전시키는 거죠.
오늘의 초점: 모델을 둘러싼 루프
오늘 이 세션에서는 그중에서도 모델을 중심으로 도는 루프에 집중하겠습니다. 모델을 고르고, 평가하고, 최적화하는 흐름이요.

자, 그럼 첫 번째 막, 모델 선택부터 시작해 보겠습니다.
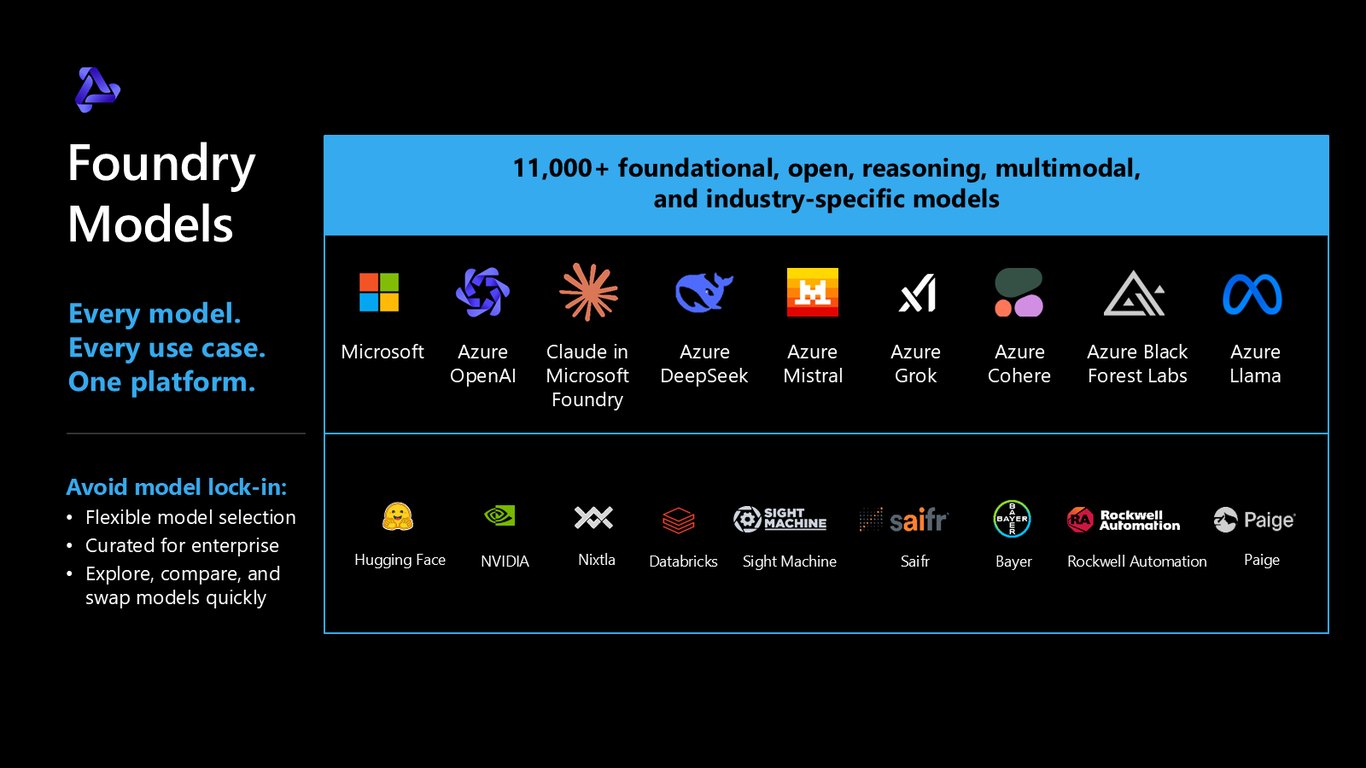
Foundry Models: 모든 모델, 하나의 플랫폼
Foundry Models에는 11,000개가 넘는 파운데이션·오픈·추론·멀티모달·산업 특화 모델이 모여 있습니다. Azure OpenAI, Claude, DeepSeek, Mistral, Grok, Llama까지요. 덕분에 특정 모델에 종속되지 않고 빠르게 탐색하고 비교하고 교체할 수 있습니다.

Claude in Microsoft Foundry
그중 Claude가 이제 Azure의 GB300 위에서 네이티브로 돌아갑니다. 추론, 코딩, 에이전트 워크플로에 강한 모델들을 오늘 바로 시작해 보실 수 있습니다.

새로운 Microsoft AI 모델 공개
그리고 새로운 Microsoft AI 모델들을 발표합니다. 사고 모델 MAI-Thinking-1, 이미지, 코드, 음성까지 채팅·이미지·보이스·스피치를 아우르는 효율적인 멀티모달 스택입니다.

AI 스펙트럼 전반의 혁신
Microsoft는 프로덕션급 프런티어 모델은 Foundry로, 실험적인 최첨단 AI는 Foundry Labs로 제공합니다. 상용과 실험, 양쪽 스펙트럼을 모두 커버합니다.

도메인 특화 목적형 모델
여기에 지리공간, 로보틱스, 바이오메디컬, 분자·소재, 코드, 검색, 생성 미디어처럼 전문 도메인을 위한 목적형 모델들도 준비돼 있습니다. Aurora, MatterGen, gpt-image-2 같은 모델들이죠.

Foundry의 NVIDIA 모델
또한 NVIDIA 모델도 Foundry에 들어옵니다. 에이전틱 코딩의 Nemotron 3, GEO AI의 Earth-2, 피지컬 AI의 Cosmos 3까지 오늘 AI.AZURE.COM에서 바로 써 보실 수 있습니다.

데모: Foundry Models
말로만 설명하기보다 직접 보여드리는 게 낫겠죠. Foundry Models를 데모로 함께 살펴보겠습니다.
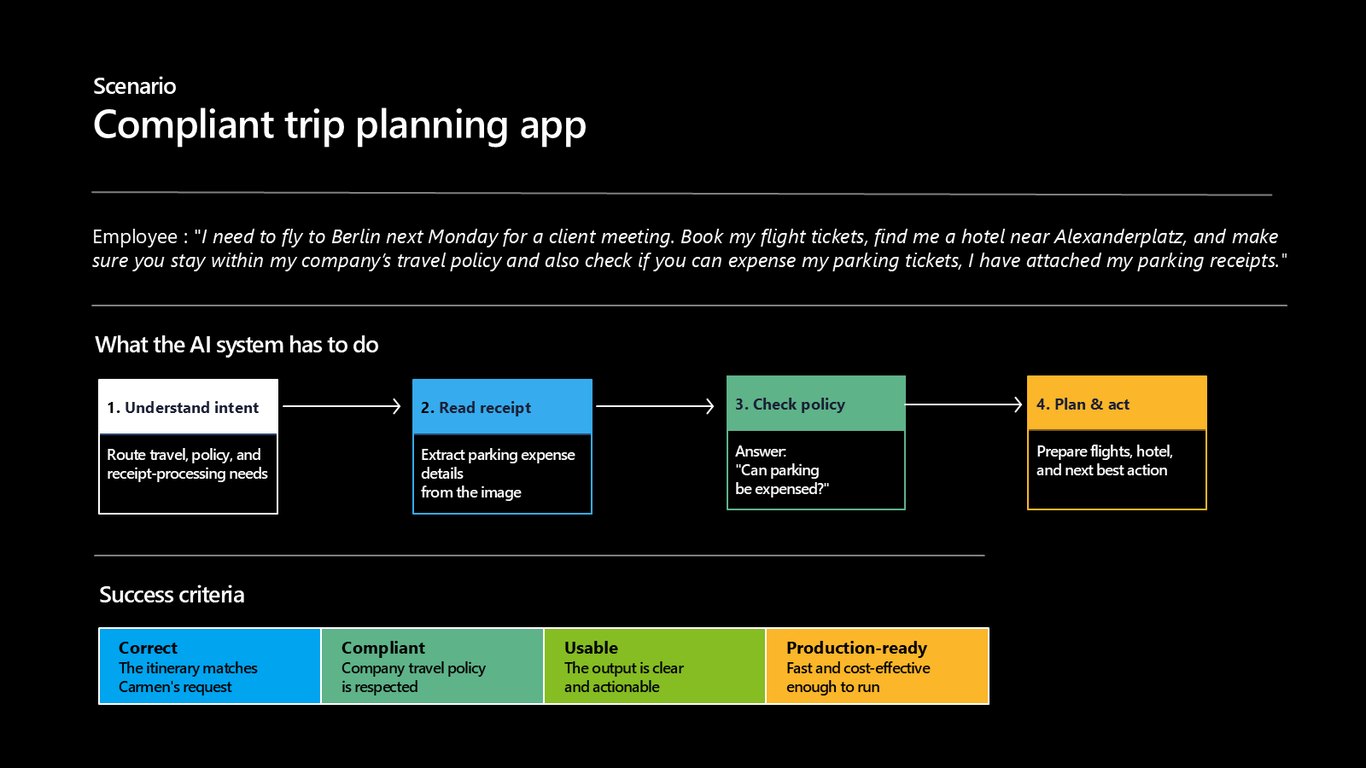
시나리오: 규정 준수 출장 계획 앱
오늘 관통할 시나리오는 이겁니다. 한 직원이 베를린 출장을 요청하면서 항공권 예약, Alexanderplatz 근처 호텔, 회사 출장 정책 준수, 주차 영수증 경비 처리까지 한꺼번에 부탁합니다. AI 시스템이 이 모든 걸 해내야 하죠.
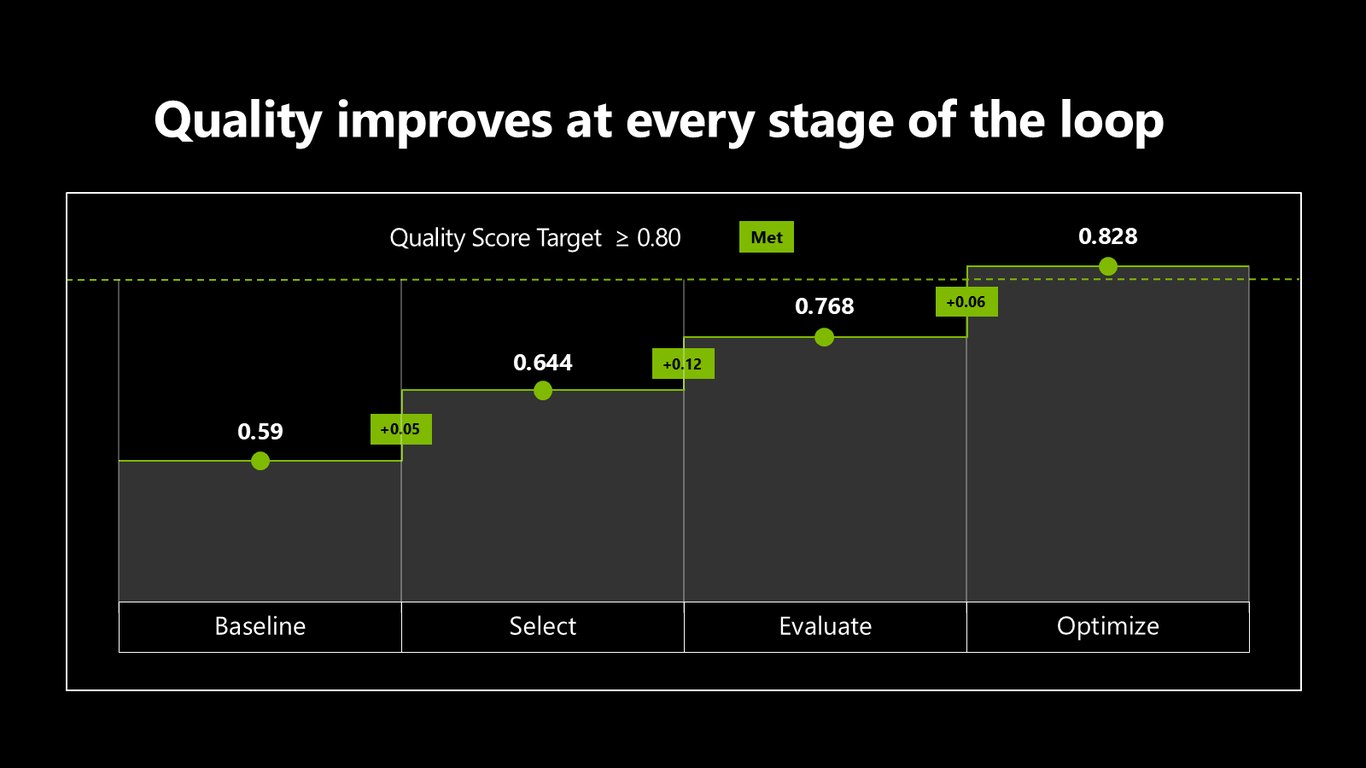
언덕 오르기: 단계마다 품질이 오른다
목표 품질 점수는 0.80입니다. 베이스라인 0.59에서 시작해 Select, Evaluate, Optimize를 거치며 0.828까지, 단계마다 조금씩 올라가는 걸 오늘 직접 확인하시게 됩니다.
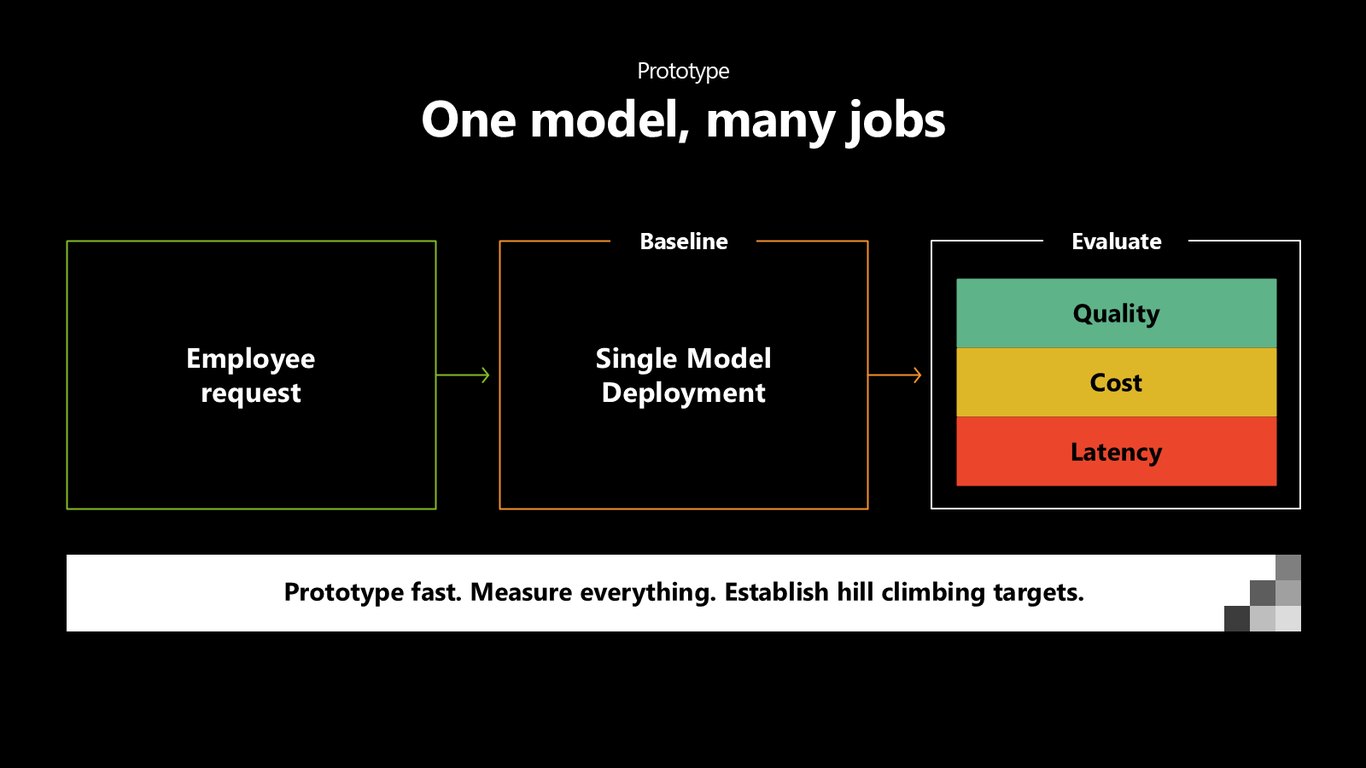
프로토타입: 한 모델이 모든 일을
먼저 프로토타입입니다. 모델 하나가 모든 작업을 다 처리하게 두고, 품질·비용·지연을 전부 측정합니다. 빠르게 만들고, 다 재고, hill climbing 목표를 잡는 거죠.

데모: 단일 모델 프로토타이핑
단일 모델로 프로토타입을 만드는 과정을 데모로 보시겠습니다. 코드는 aka.ms/build/BRK230에서 직접 받아 보실 수 있습니다.
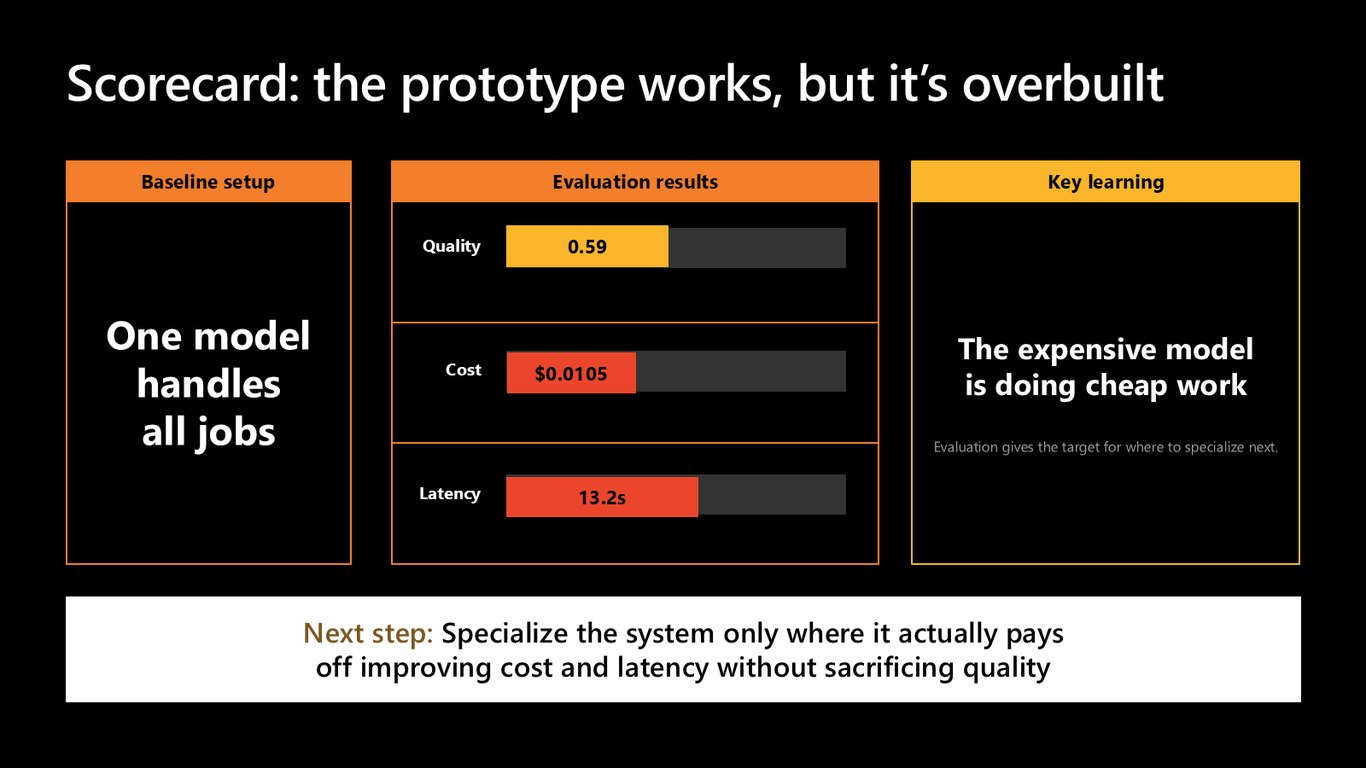
스코어카드: 되긴 하는데 과잉 설계
결과를 보면 품질 0.59, 비용 0.0105달러, 지연 13.2초. 동작은 합니다. 하지만 비싼 모델이 값싼 작업까지 다 하고 있어요. 평가가 어디를 특화해야 할지 알려 줍니다. 다음은 실제로 이득이 나는 곳만 골라 특화하는 겁니다.
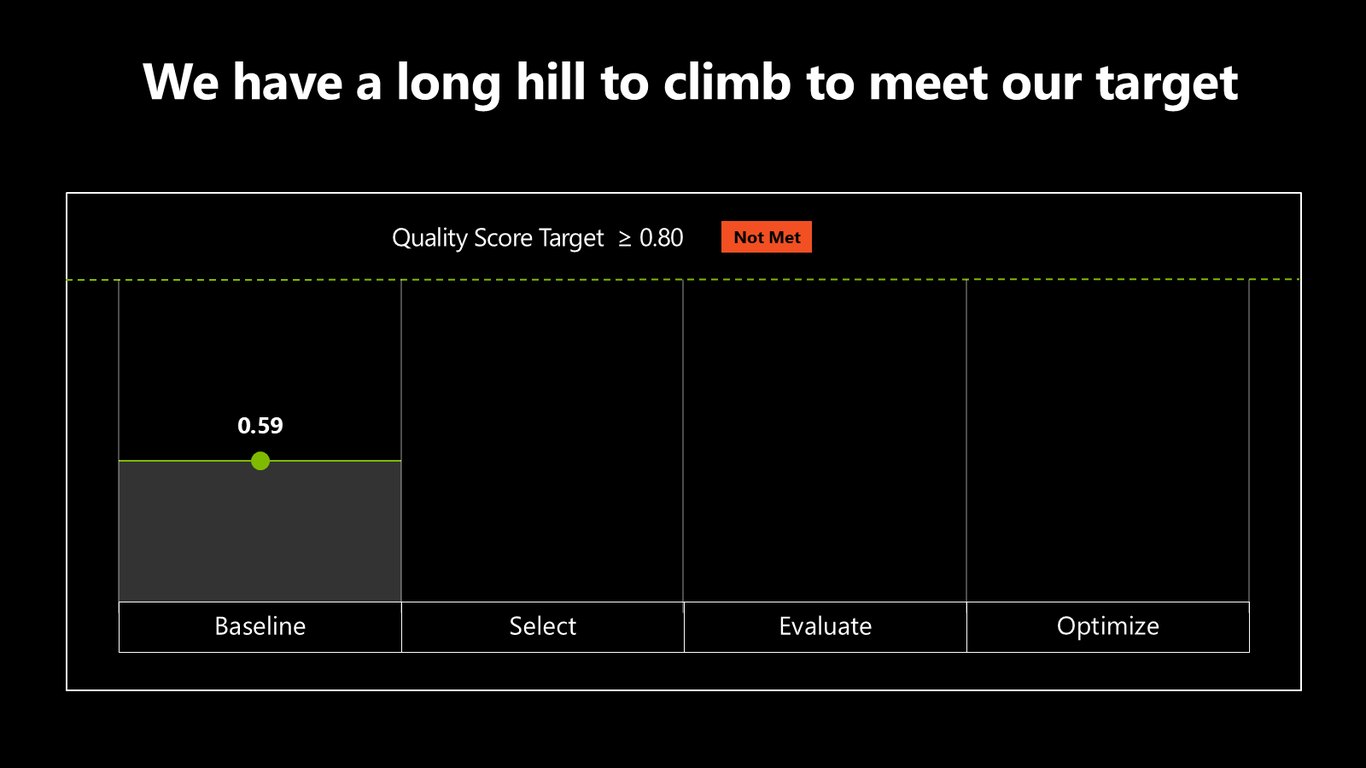
목표까지는 아직 갈 길이 멉니다
지금 0.59로는 목표 0.80에 한참 못 미칩니다. 오를 언덕이 아직 많이 남아 있는 거죠.
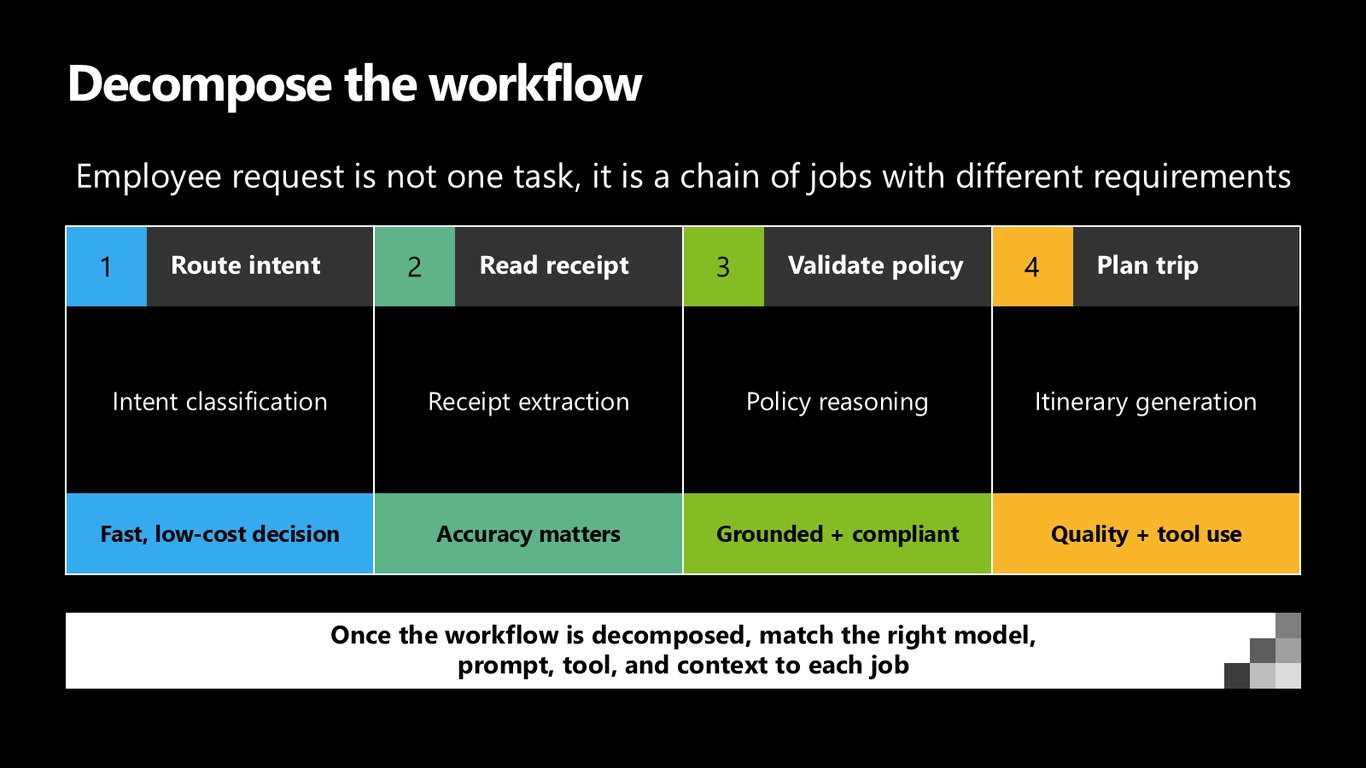
워크플로를 분해하기
직원의 요청은 사실 하나의 작업이 아닙니다. 의도 분류, 영수증 추출, 정책 추론, 일정 생성처럼 요구사항이 다 다른 작업들의 연쇄죠. 분해하고 나면 각 작업에 맞는 모델·프롬프트·도구·컨텍스트를 붙일 수 있습니다.
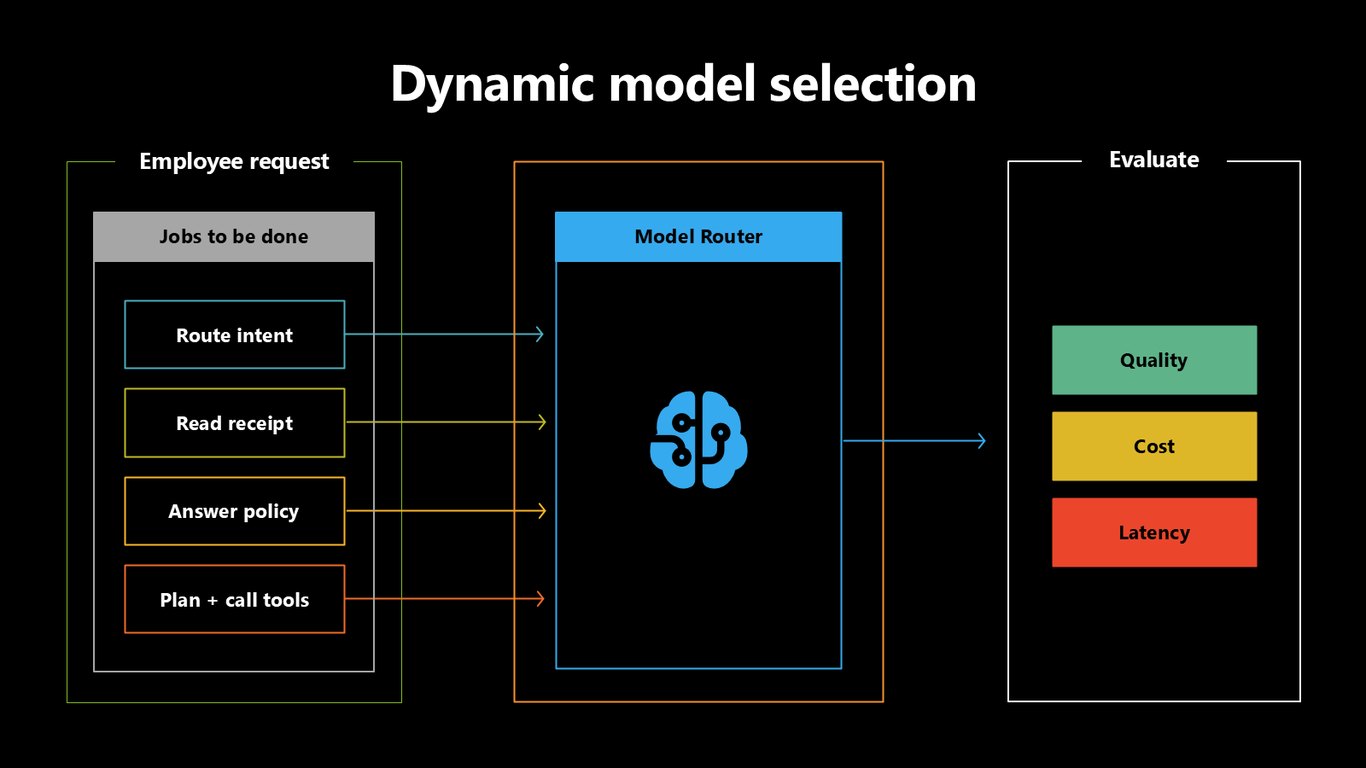
동적 모델 선택
그래서 Model Router를 씁니다. 의도 라우팅, 영수증 읽기, 정책 응답, 계획과 도구 호출, 각 작업마다 가장 알맞은 모델로 동적으로 보내면서 품질·비용·지연을 함께 봅니다.
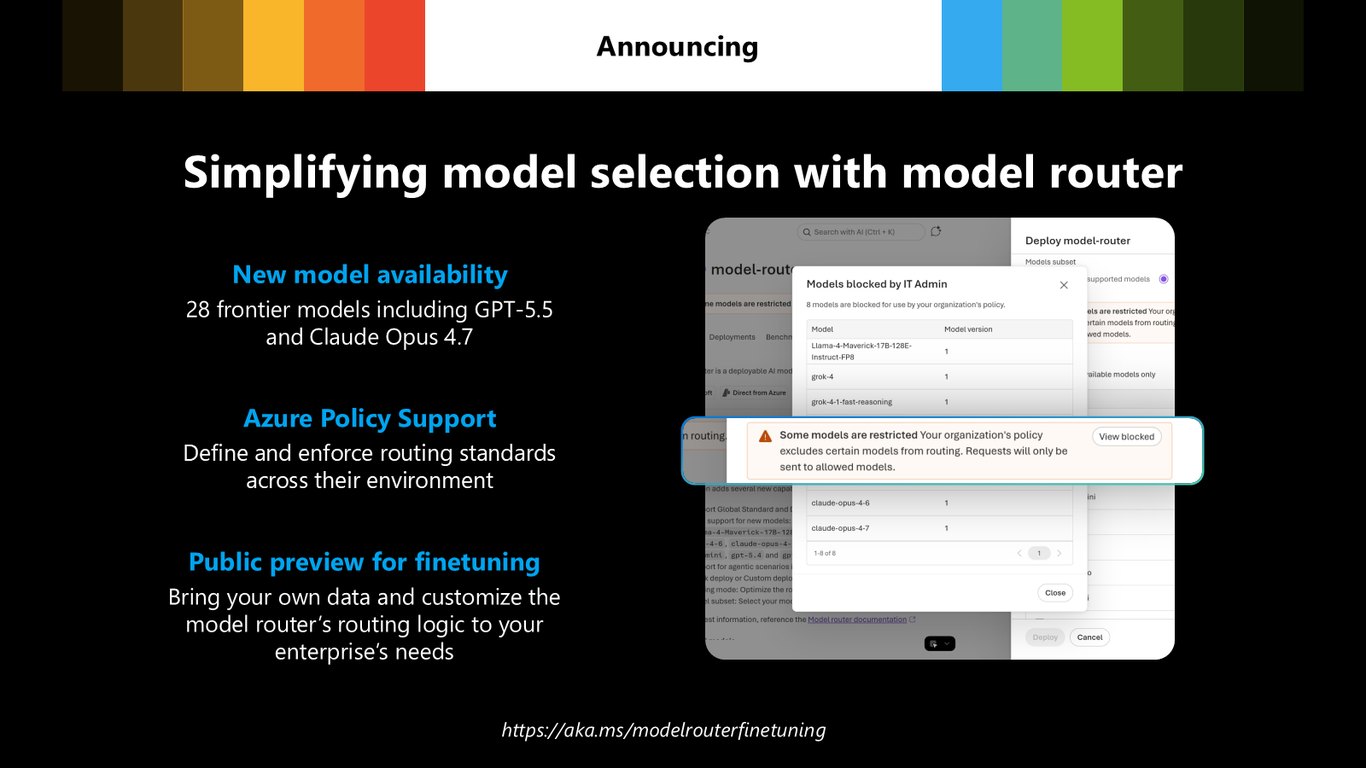
Model Router 신기능 공개
Model Router도 새로워집니다. GPT-5.5, Claude Opus 4.7 등 28개 프런티어 모델을 지원하고, Azure Policy로 라우팅 표준을 강제할 수 있으며, 라우팅 로직 파인튜닝이 퍼블릭 프리뷰로 열립니다.
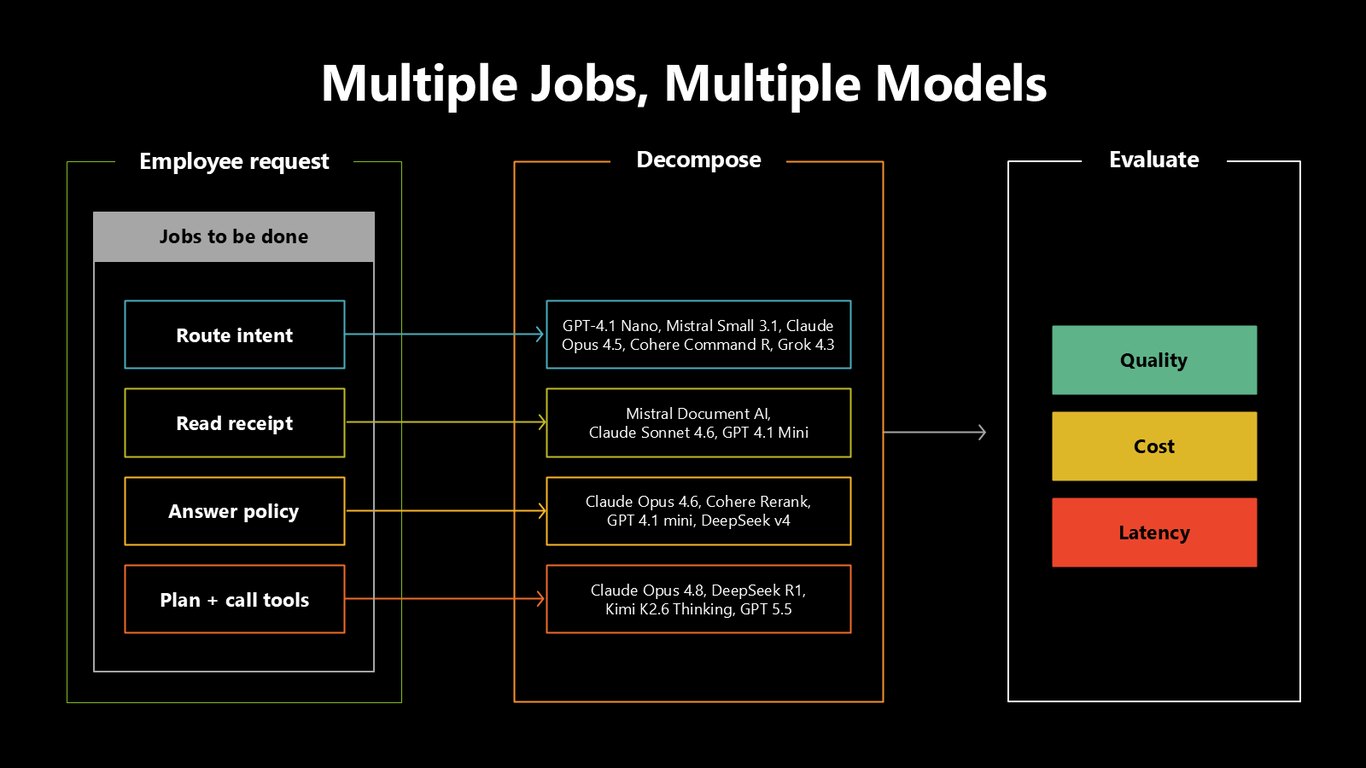
여러 작업, 여러 모델
이제 작업마다 서로 다른 모델이 붙습니다. 의도 라우팅엔 가볍고 빠른 모델을, 정책 추론엔 강한 모델을, 이런 식으로 각 작업의 성격에 맞게 배치하는 거죠.

데모: 멀티 모델
여러 모델을 조합한 멀티 모델 시스템을 데모로 보겠습니다. 역시 코드는 aka.ms/build/BRK230에 있습니다.
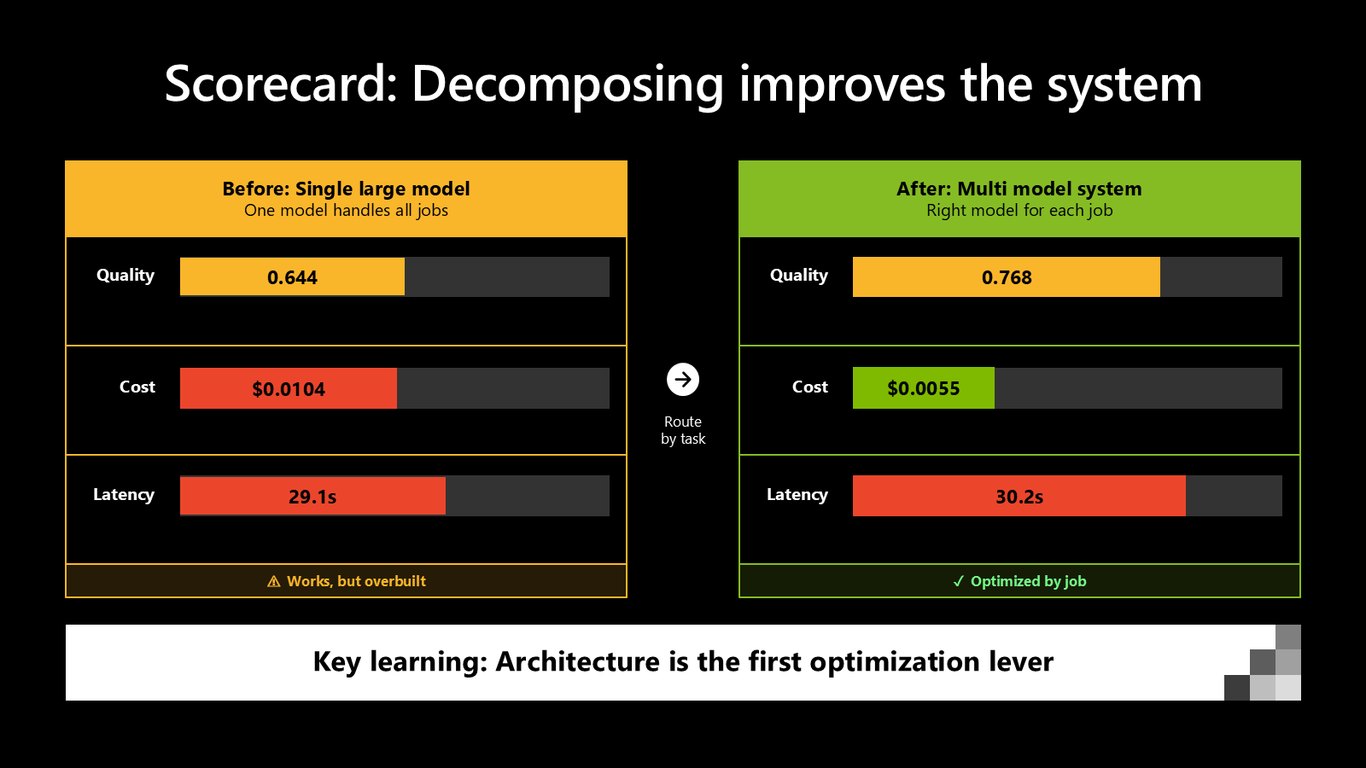
스코어카드: 분해가 시스템을 개선한다
결과가 확 좋아졌습니다. 품질은 0.644에서 0.768로, 비용은 0.0104달러에서 0.0055달러로 절반 가까이 줄었어요. 아키텍처, 즉 작업별로 나눠 배치하는 게 첫 번째 최적화 레버입니다.
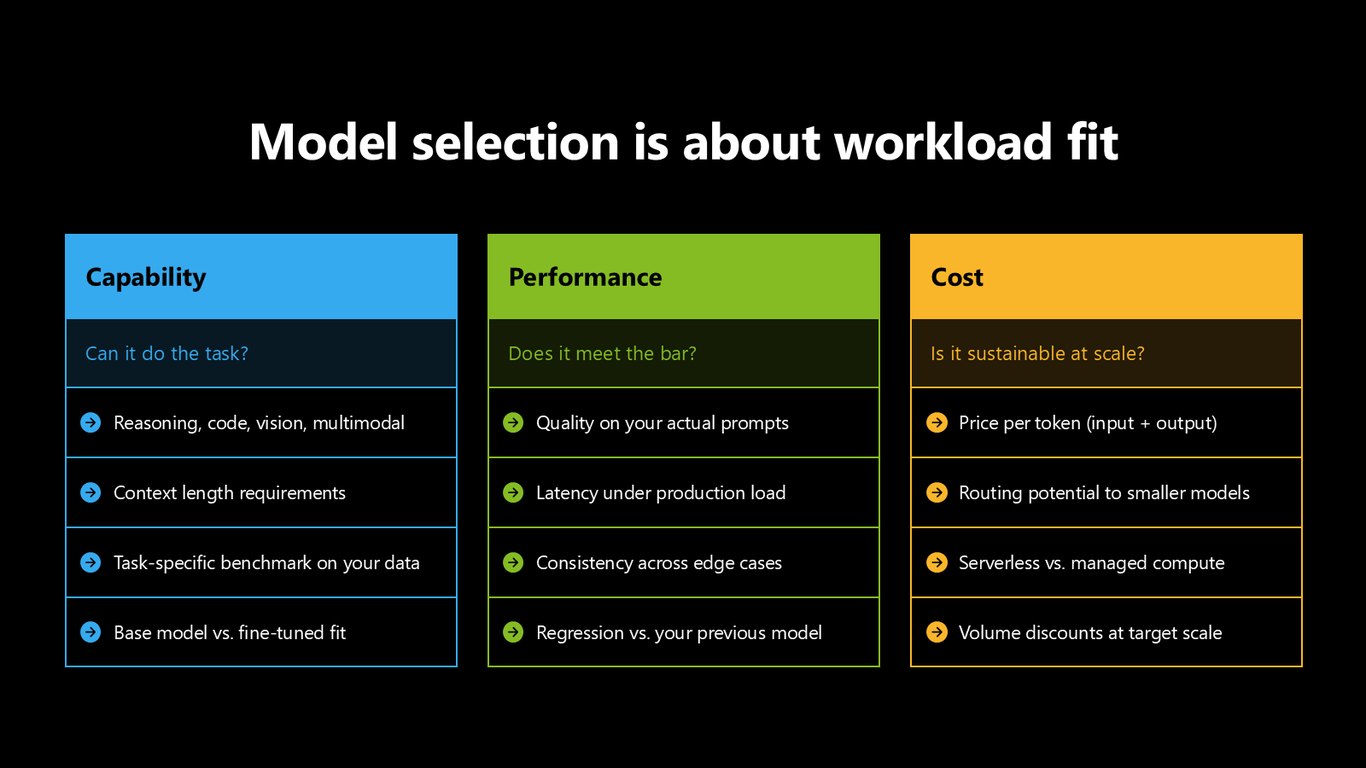
모델 선택은 워크로드 적합성
결국 모델 선택은 워크로드에 맞느냐의 문제입니다. 그 작업을 할 능력이 있는가, 우리 데이터에서 기준을 넘기는가, 그리고 스케일에서도 지속 가능한가. 이 세 축으로 판단합니다.

이제 두 번째 막, 평가로 넘어가겠습니다.

평가는 곧 제품 스펙입니다
개선 루프에서 평가는 사실상 제품 스펙입니다. 무엇이 좋은 건지, 어떤 트레이드오프가 중요한지, 그리고 모든 변경을 어떻게 측정할지를 정의하죠. 정확성, 정책 준수, 도구 호출 유효성, 에스컬레이션 정확도, 안전과 프라이버시까지요.
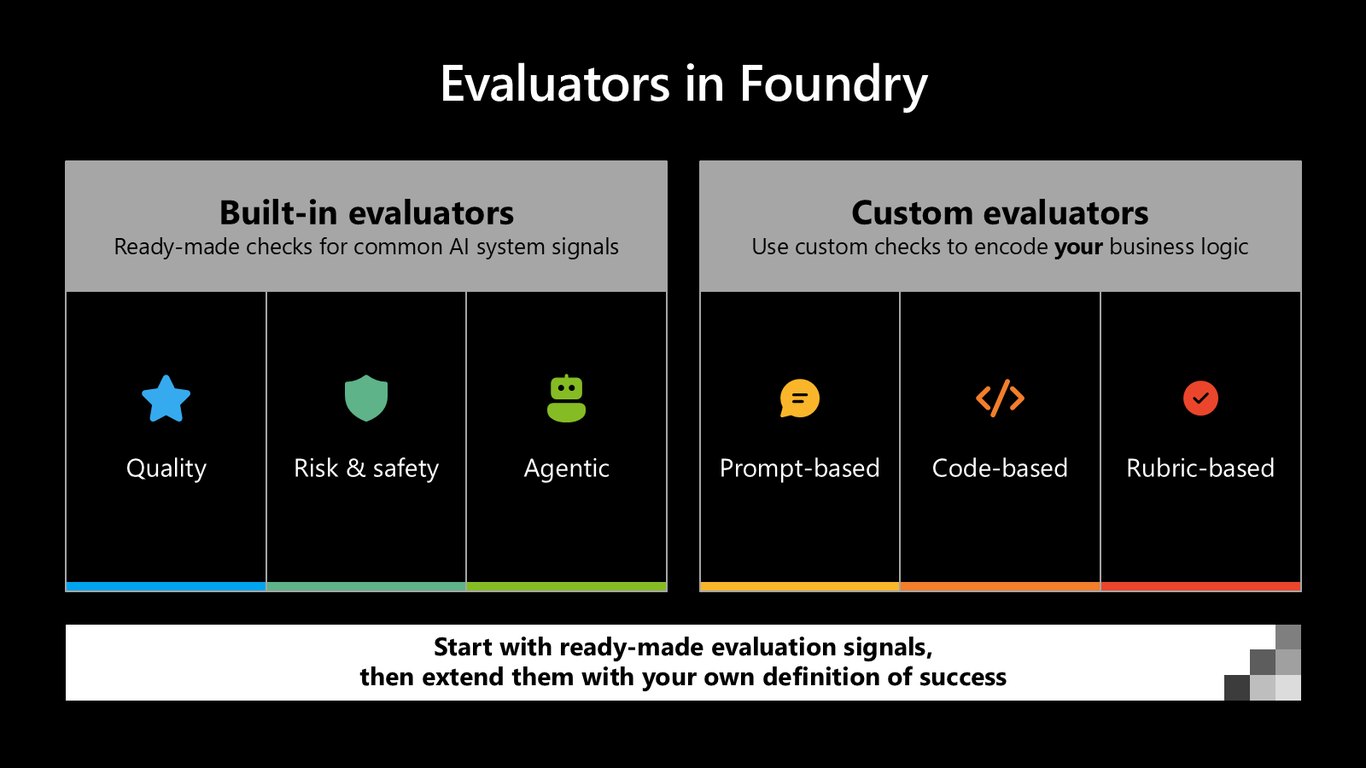
Foundry의 Evaluator
Foundry에는 품질, 위험·안전, 에이전틱 신호를 바로 확인하는 내장 evaluator가 있습니다. 그리고 프롬프트·코드·루브릭 기반의 커스텀 evaluator로 여러분의 비즈니스 로직을 직접 담을 수 있어요. 기성 신호로 시작해 자신만의 성공 정의로 확장하는 겁니다.

Rubric Evaluators 공개
새로 선보이는 Rubric Evaluators는 평가 기준을 자동으로 생성해 줍니다. 에이전트 정의에서 맞춤형 품질 기준을 만들고, 가중치를 둔 차원으로 총점을 매겨 품질을 더 섬세하게 볼 수 있습니다.

데모: 커스텀 Evaluator
커스텀 evaluator를 실제로 어떻게 만드는지 데모로 보겠습니다. 코드는 aka.ms/build/BRK230에 준비돼 있습니다.
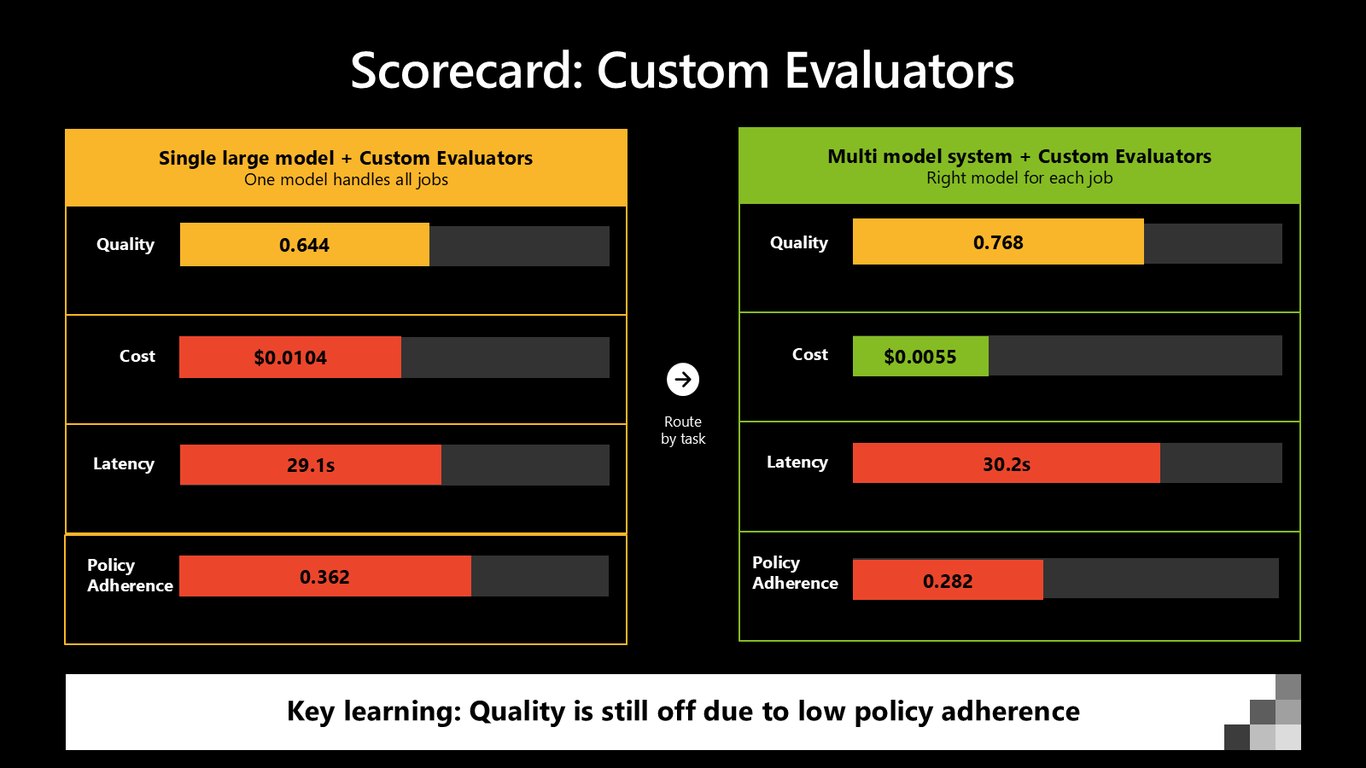
스코어카드: 커스텀 Evaluator
커스텀 evaluator를 붙여 보니 새로운 사실이 드러납니다. 품질은 괜찮은데 정책 준수 점수가 0.362, 0.282로 매우 낮아요. 품질이 아직 목표에 못 미치는 진짜 원인이 바로 이 낮은 정책 준수였던 겁니다.
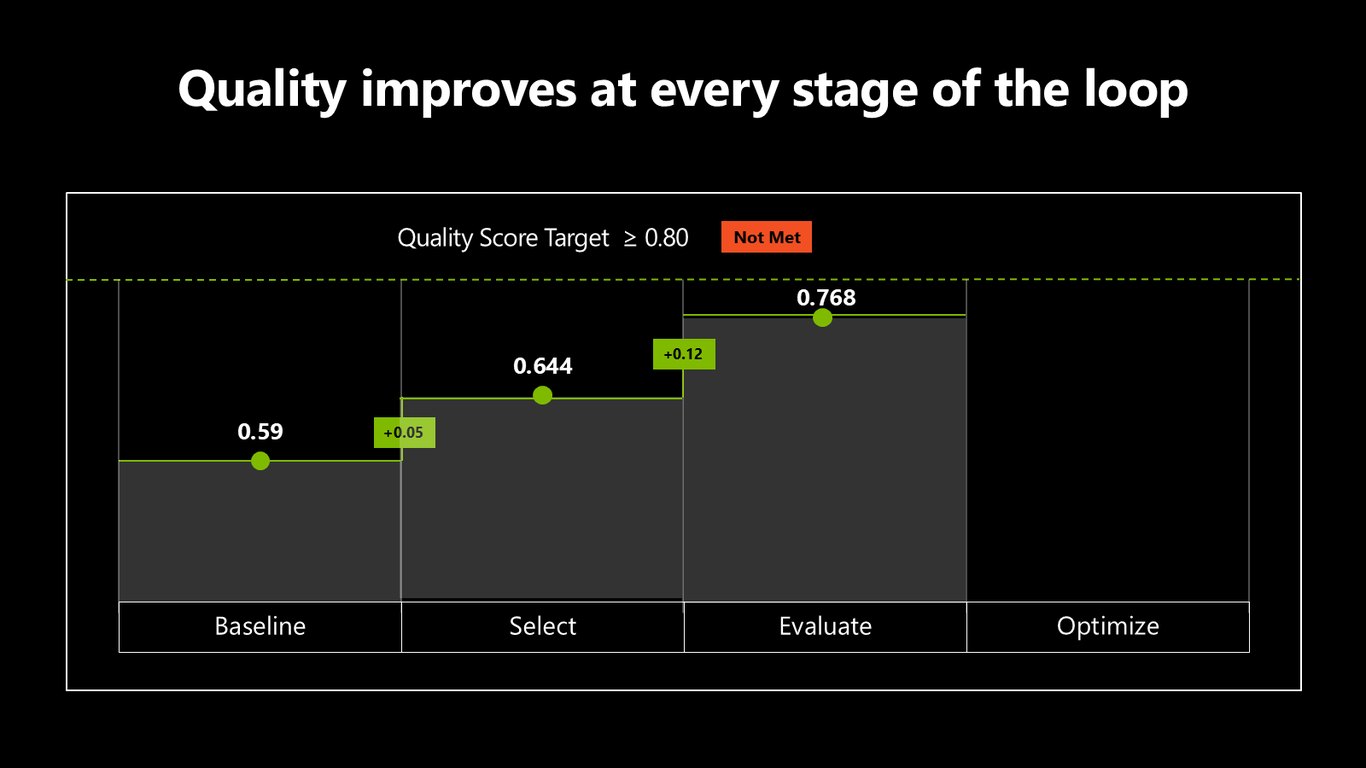
언덕 오르기: 아직 목표 미달
지금까지 0.59에서 0.644, 0.768까지 올라왔지만 목표 0.80에는 아직 못 닿았습니다. 정책 준수를 잡아야 다음 언덕을 넘을 수 있겠죠.

세 번째 막, 최적화로 가겠습니다.
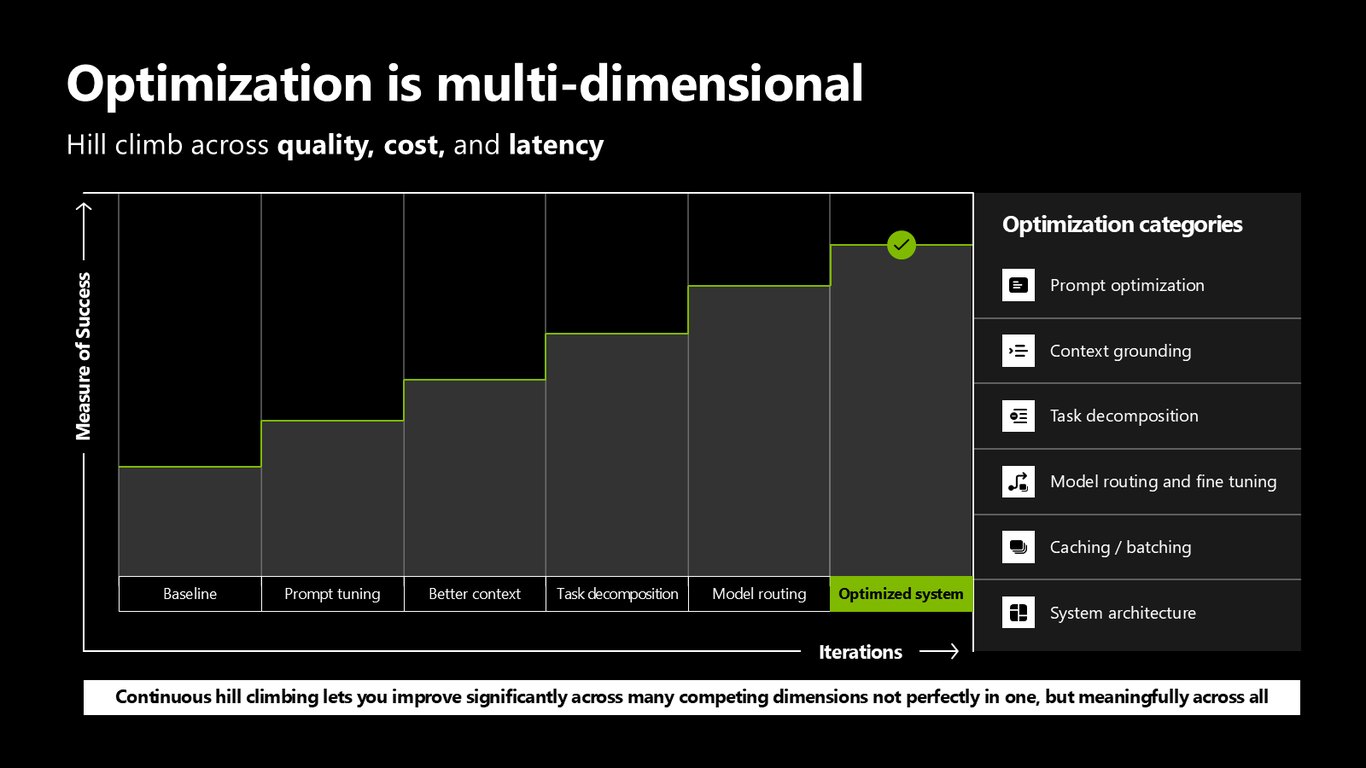
최적화는 다차원입니다
최적화는 한 방향이 아니라 여러 차원을 동시에 오르는 일입니다. 프롬프트 튜닝, 더 나은 컨텍스트, 작업 분해, 모델 라우팅. 어느 하나만 완벽하게가 아니라 경쟁하는 여러 지표를 의미 있게 함께 끌어올리는 거죠.
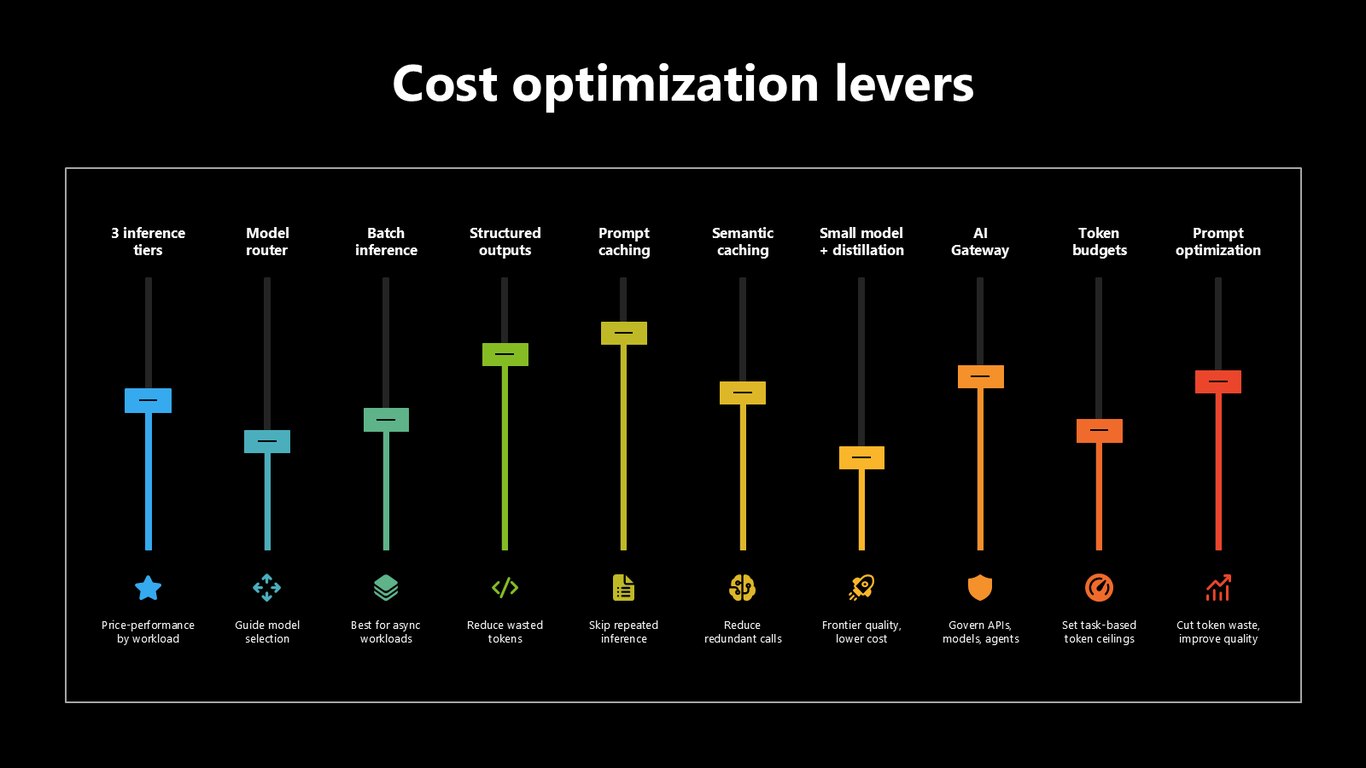
비용 최적화 레버
먼저 비용입니다. 3단계 추론 티어, model router, 배치 추론, 구조화된 출력, 프롬프트·시맨틱 캐싱, 소형 모델과 distillation, AI Gateway, 토큰 예산까지. 워크로드에 맞는 레버를 골라 쓰면 됩니다.
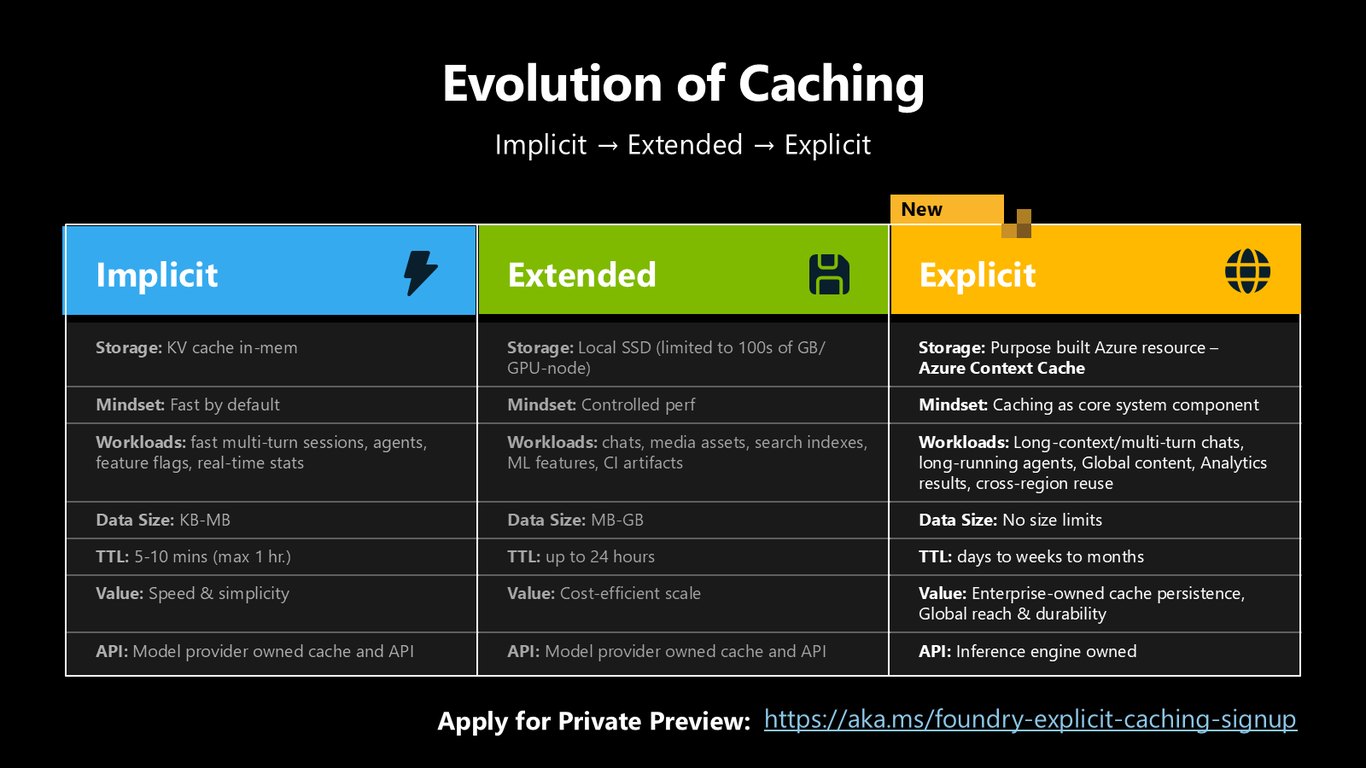
캐싱의 진화: Implicit에서 Explicit로
캐싱도 진화합니다. 기본으로 빠른 Implicit, 로컬 SSD로 비용 효율을 높인 Extended, 그리고 전용 Azure Context Cache로 캐싱 자체를 핵심 구성요소로 삼는 Explicit까지요. Explicit 캐싱은 프라이빗 프리뷰 신청을 받고 있습니다.
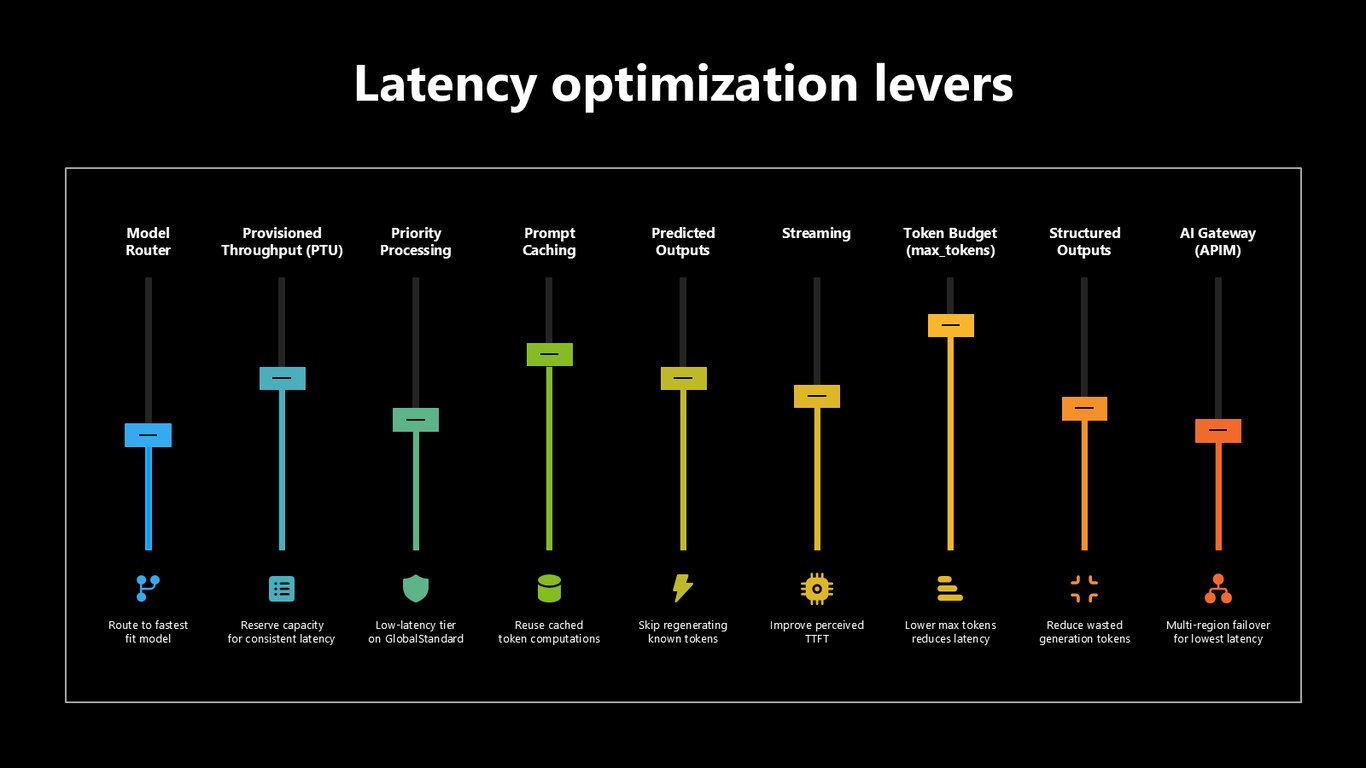
지연 최적화 레버
지연 시간도 레버가 많습니다. Model Router로 가장 빠른 모델로 보내고, PTU로 일관된 지연을 확보하고, Priority Processing, 프롬프트 캐싱, 예측 출력, 스트리밍, 그리고 AI Gateway의 멀티 리전 페일오버까지 활용합니다.
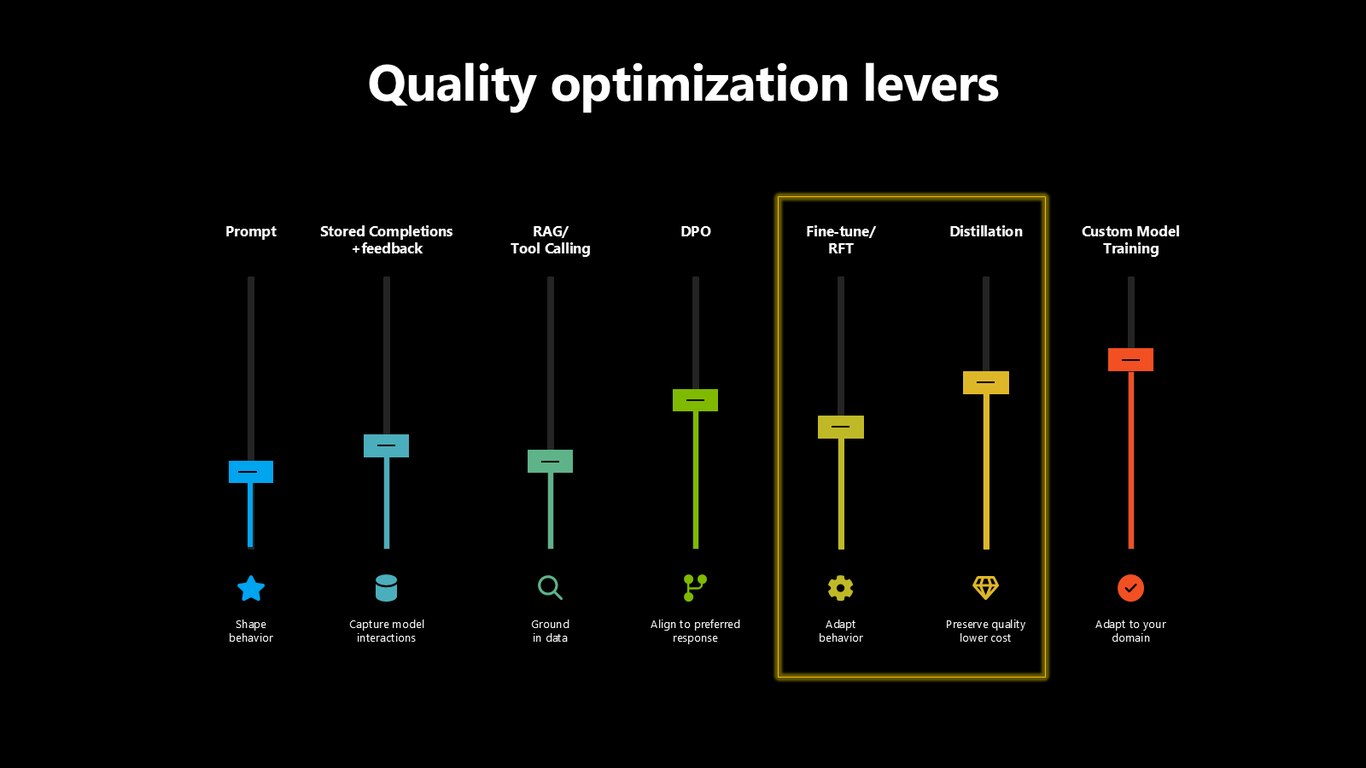
품질 최적화 레버
품질 쪽은 프롬프트로 행동을 잡고, RAG와 도구 호출로 데이터에 근거를 두고, DPO로 선호 응답에 맞추고, 파인튜닝·RFT·distillation으로 도메인에 적응시킵니다.

정책 준수를 위한 Distillation + 파인튜닝
낮았던 정책 준수를 잡아 보겠습니다. mini 모델은 일반 케이스엔 충분했지만 엣지 케이스가 문제였죠. travel-policy.md를 소스로 GPT-4.1이 근거 있는 Q&A 84쌍을 만들고, 그걸로 GPT-4.1 mini를 파인튜닝해 학생 모델이 반복되는 정책 질문을 효율적으로 처리하게 합니다.

데모: Distillation + 파인튜닝
distillation과 파인튜닝 과정을 데모로 직접 보여드리겠습니다. 코드는 aka.ms/build/BRK230에 있습니다.

스코어카드: 정책 최적화
결과가 인상적입니다. 파인튜닝한 학생 모델로 품질은 0.828, 비용은 0.0052달러, 지연은 11.2초, 그리고 정책 준수가 0.282에서 0.818로 뛰었어요. 최적화는 이렇게 쌓이면 복리로 효과가 납니다.
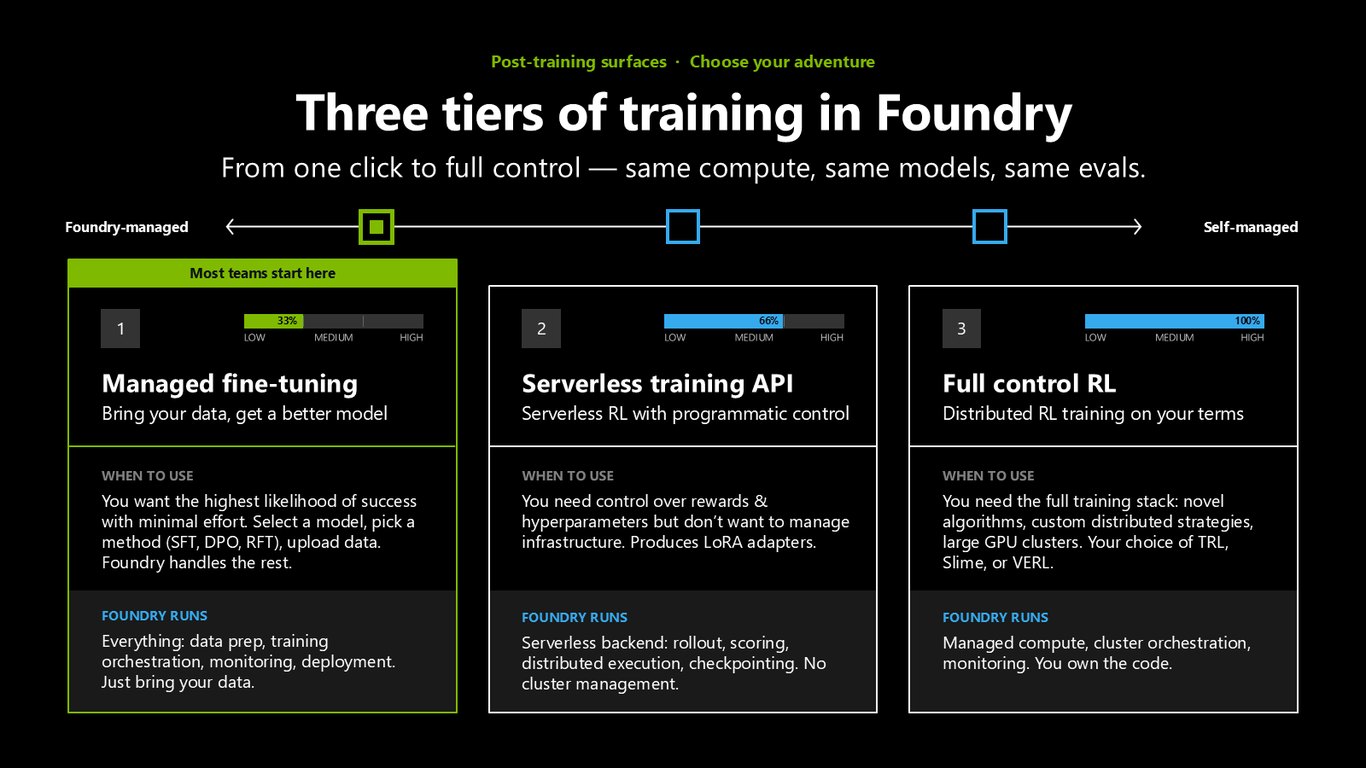
포스트 트레이닝: 세 가지 선택지
Foundry에는 학습 방식이 세 티어로 있습니다. 데이터만 올리면 되는 Foundry 관리형 파인튜닝, 보상과 하이퍼파라미터를 제어하는 서버리스 트레이닝 API, 그리고 알고리즘과 클러스터까지 직접 다루는 풀 컨트롤 RL. 같은 컴퓨트, 같은 모델, 같은 평가를 씁니다.
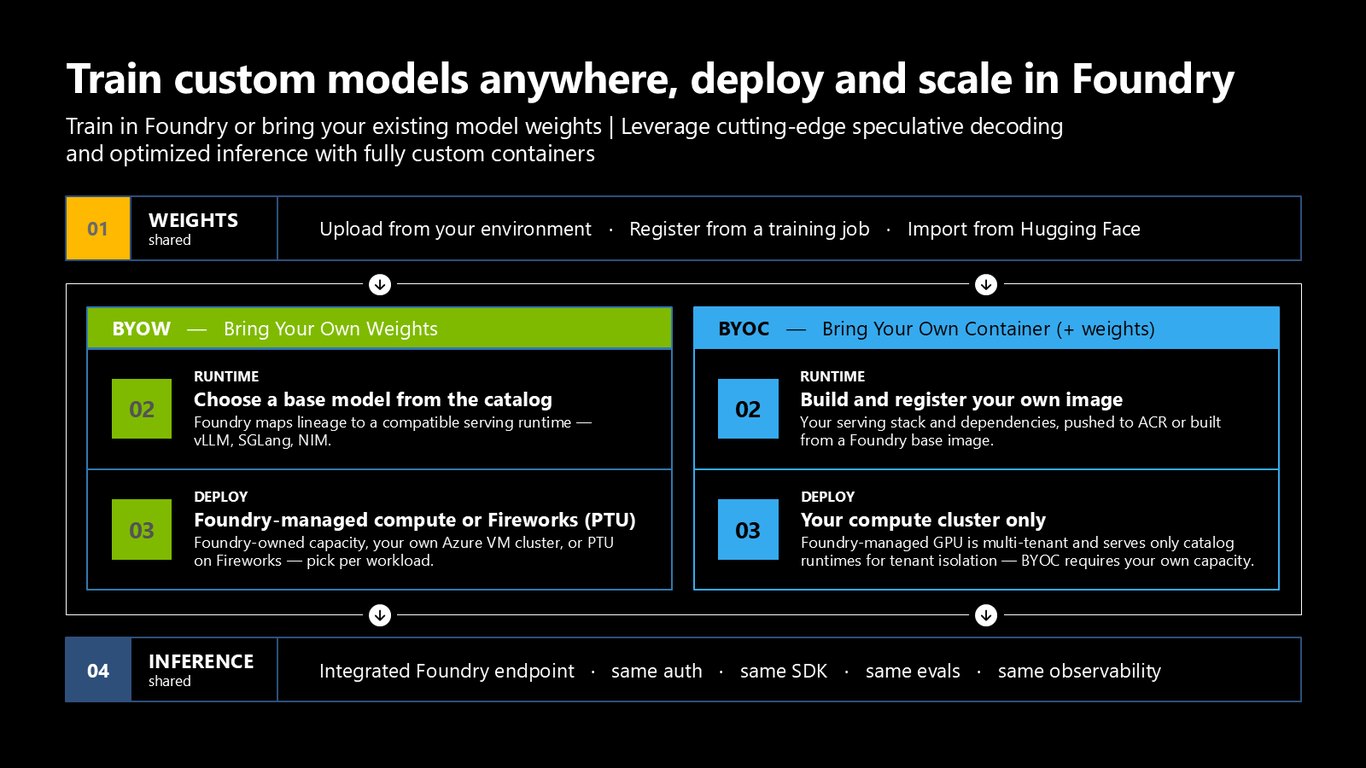
어디서든 학습, Foundry에서 배포
커스텀 모델은 어디서 학습하든 Foundry에서 배포하고 확장할 수 있습니다. 가중치를 직접 가져오는 BYOW, 컨테이너를 직접 가져오는 BYOC를 지원하고, vLLM·SGLang·NIM 런타임에 매핑해 통합 엔드포인트로 서빙합니다.

Fireworks AI on Foundry 공개
Fireworks AI가 Foundry에 들어옵니다. 프로덕션급 오픈 모델 추론을 Azure에 내장한 것으로, 프런티어 오픈 모델에 데이제로로 접근하고 최고 수준의 추론 성능을 네이티브 Azure 기반에서 누릴 수 있습니다.

Managed Compute in Foundry 공개
Managed Compute도 공개합니다. 오픈 모델을 위한 새로운 실행 경로로, Hugging Face·NVIDIA·Microsoft Research의 수천 개 모델을 Foundry 관리형 가속기나 여러분의 Azure VM에서, 최적화된 런타임으로 돌릴 수 있습니다.

네 번째 막, 운영으로 넘어가겠습니다.
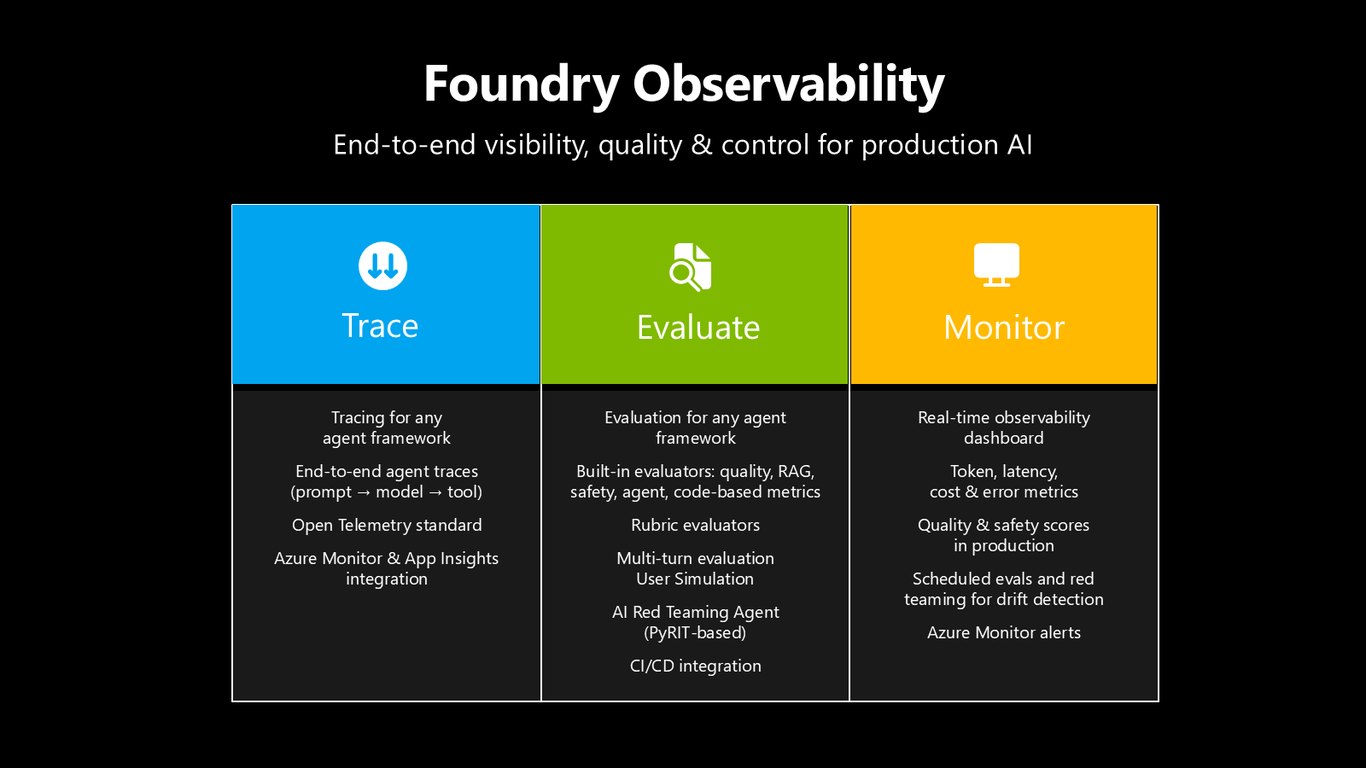
Foundry Observability
프로덕션 AI에는 끝단까지의 가시성이 필요합니다. Foundry Observability는 어떤 에이전트 프레임워크든 Trace로 추적하고, 다양한 evaluator로 Evaluate하고, 토큰·지연·비용·오류와 품질·안전 점수를 실시간 대시보드로 Monitor합니다.

데모: Observability
실제 운영 화면에서 Observability가 어떻게 보이는지 데모로 확인해 보겠습니다.
Observability 실사용 모습
이렇게 트레이스와 지표, 품질 점수가 한자리에서 흐르는 걸 보실 수 있습니다. 프로덕션에서 드리프트가 생기면 예약 평가와 red teaming으로 바로 잡아냅니다.

마지막 막입니다. 지금까지의 여정을 하나의 플레이북으로 정리하겠습니다.
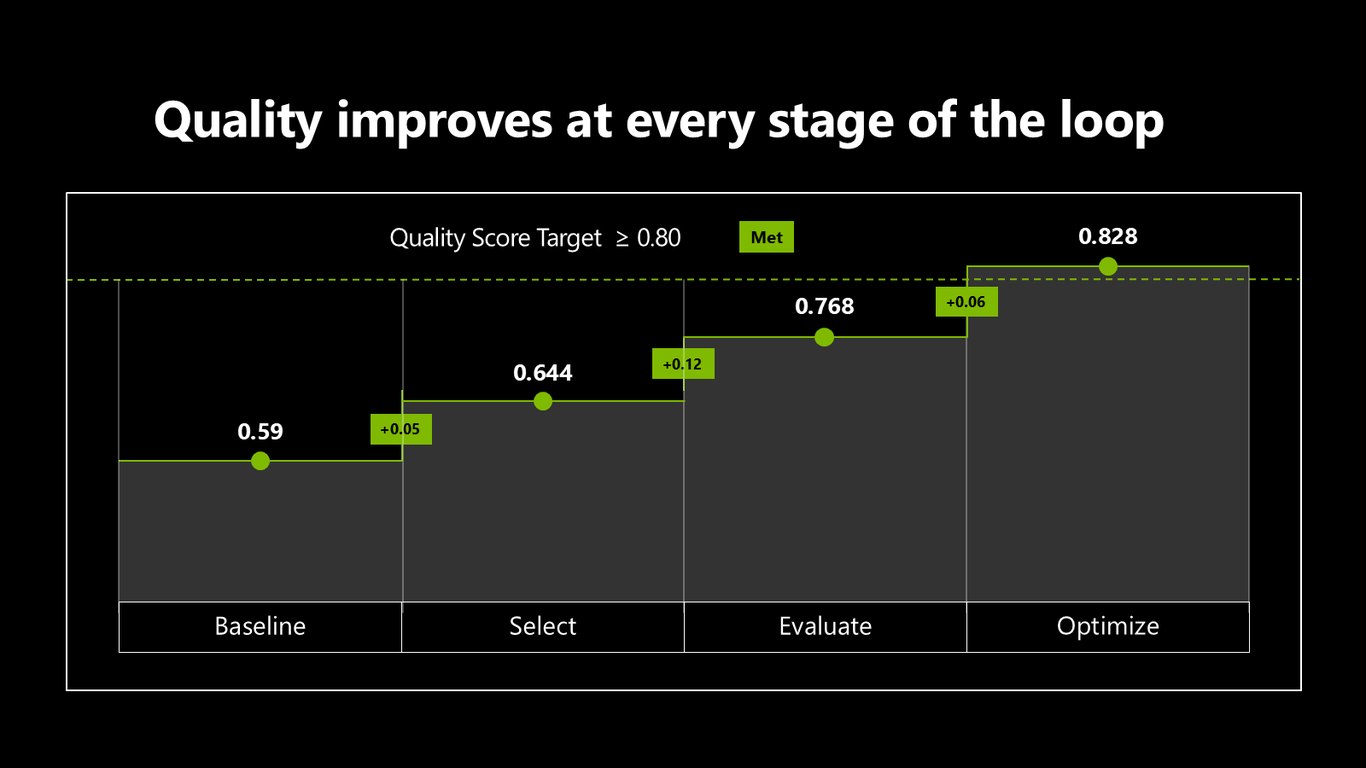
언덕 오르기: 목표 달성
다시 전체 그림을 보면, 0.59에서 시작해 Select, Evaluate, Optimize를 거치며 0.828에 도달했습니다. 목표 0.80을 넘겼죠. 단계마다 쌓인 개선이 결국 목표를 달성하게 만든 겁니다.

프롬프트가 아니라 시스템을 만드세요
핵심 교훈은 이겁니다. 프롬프트가 아니라 시스템을 만드세요. 워크로드에 맞는 모델을 고르고, 여러분의 데이터로 평가하고, 시스템을 최적화하고, 통제 아래 운영하고, 계속 개선하는 겁니다.
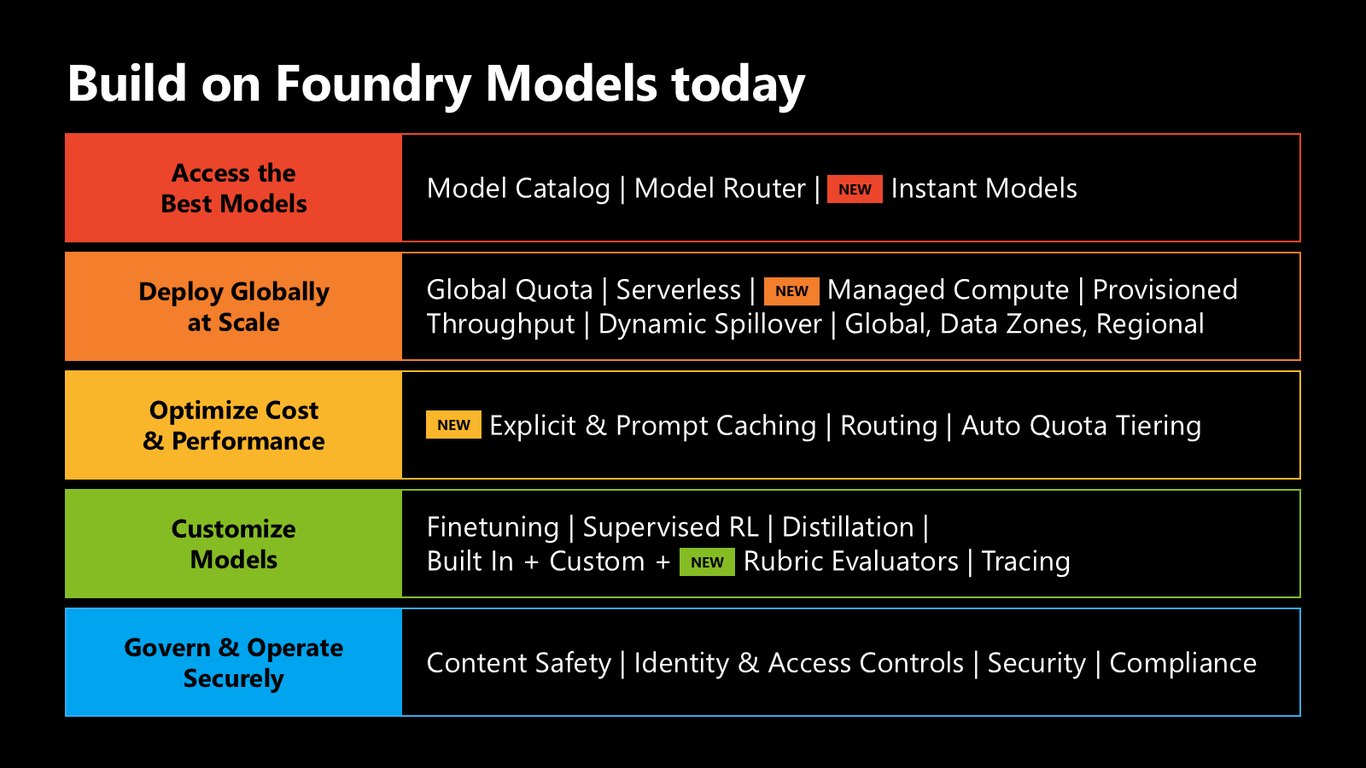
오늘 바로 Foundry Models로
이 모든 걸 오늘 바로 시작하실 수 있습니다. 최고의 모델 접근, 전 세계 확장 배포, 비용·성능 최적화, 모델 커스터마이즈, 그리고 안전한 거버넌스와 운영까지 Foundry Models 안에 다 있습니다.
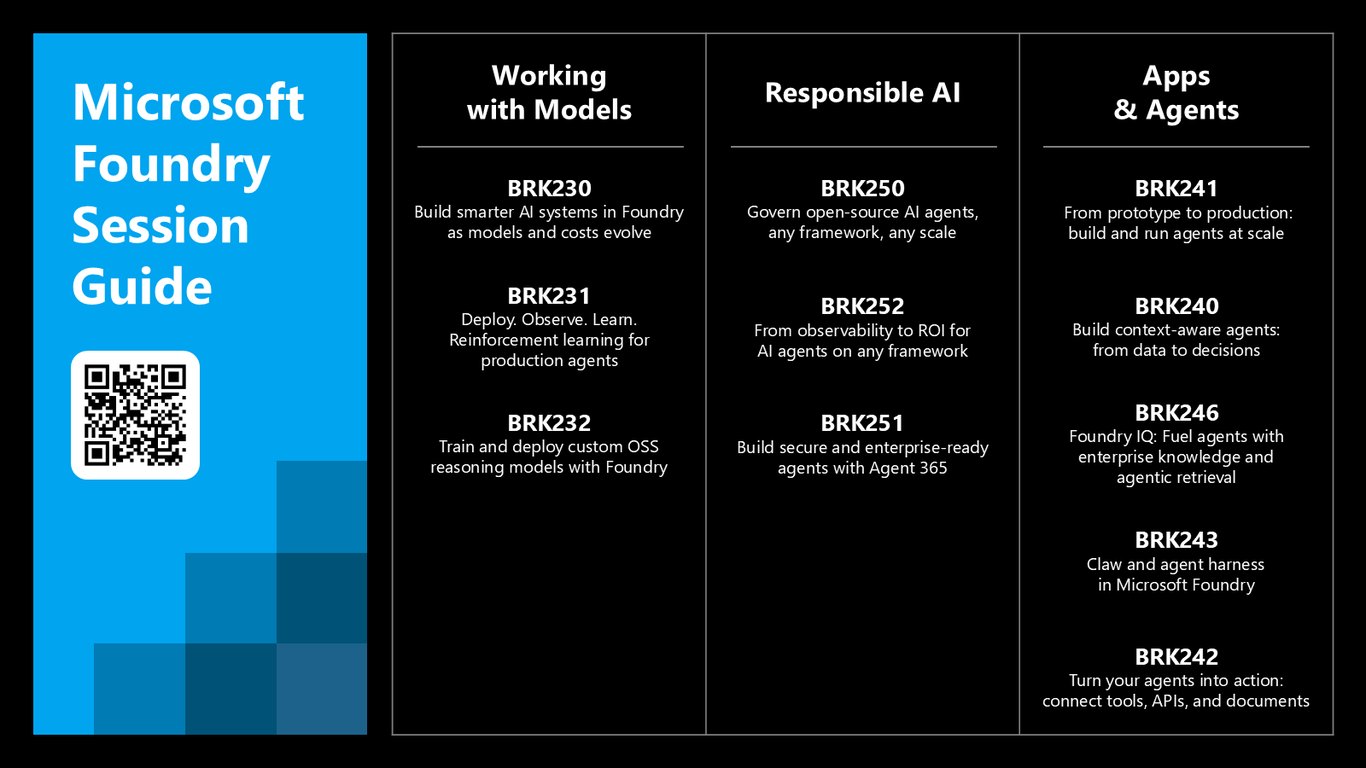
Microsoft Foundry 세션 가이드
더 깊이 파고들고 싶으시면 관련 세션들을 참고하세요. 모델 다루기, 책임 있는 AI, 앱과 에이전트 주제로 BRK231, BRK232, BRK246 같은 세션들이 준비돼 있습니다.

여정의 모든 단계를 함께합니다
여러분의 여정 내내 저희가 함께하겠습니다. ai.azure.com에서 Foundry로 빌드를 시작하고, aka.ms/build26-BRK230에서 이 세션 코드를 받고, Discord 커뮤니티에도 합류해 주세요.

세션 페이지와 설문
세션 상세 페이지에서 튜토리얼과 리소스, 코드로 바로 실행해 보실 수 있습니다. aka.ms/build/evals나 QR 코드로 설문도 꼭 남겨 주세요.

감사합니다
감사합니다.