
안녕하세요, 오늘은 프로덕션에 올라간 에이전트를 강화학습으로 어떻게 배포하고, 관찰하고, 계속 학습시킬 수 있는지 이야기해 보겠습니다. Microsoft의 Alicia Frame, Omkar More와 함께합니다.

오늘 다룰 내용
오늘은 에이전트가 왜 모델 경제성을 뒤흔드는지부터 시작해서, 파인튜닝과 강화학습이 어떻게 해답이 되는지, 그리고 여러분이 오늘 밤 당장 시작할 수 있는 방법까지 순서대로 짚어보겠습니다.
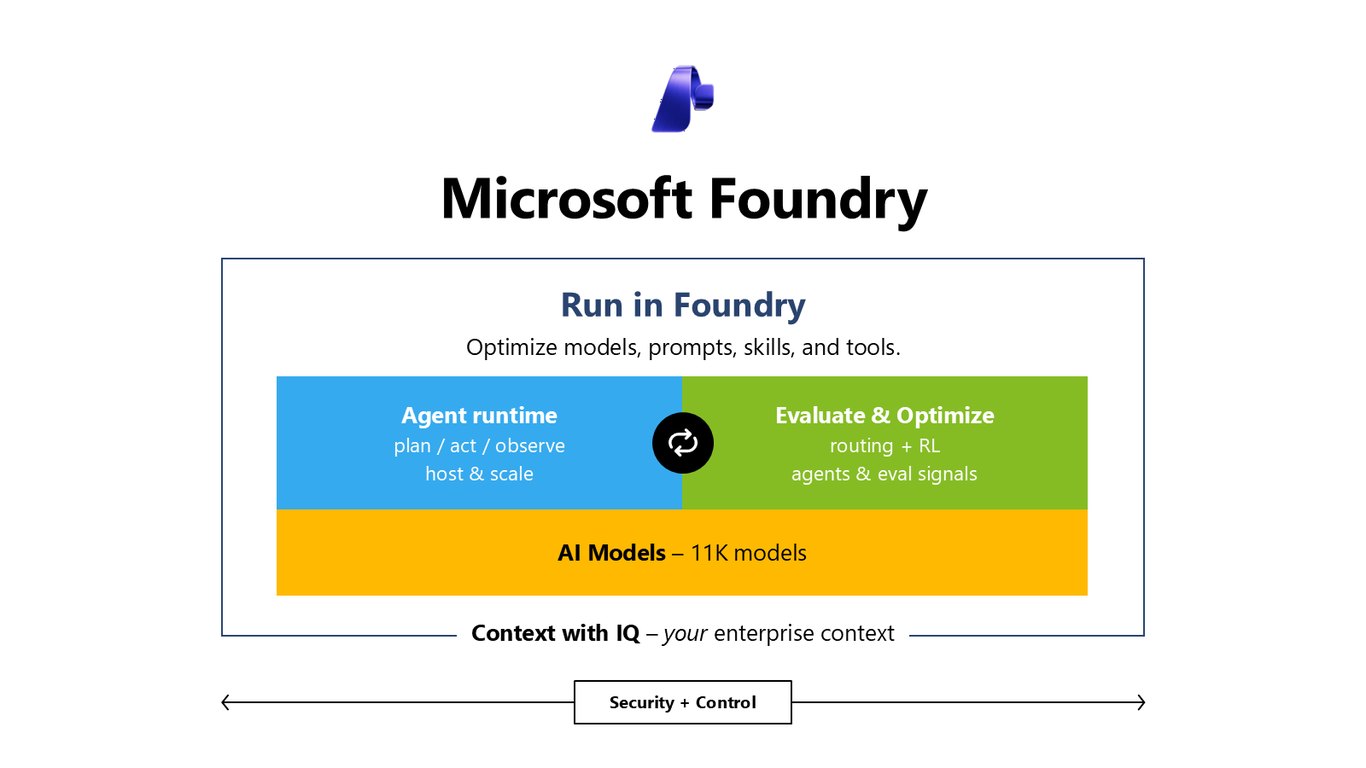
Microsoft Foundry 전체 그림
먼저 큰 그림부터 보겠습니다. Microsoft Foundry는 GitHub에서 빌드하고, Foundry에서 실행하며, M365 Copilot이나 Teams로 배포까지 이어지는 에이전트 팩토리입니다. 이 모든 흐름 위에 Security와 Control이 항상 함께 있다는 점이 핵심이죠.
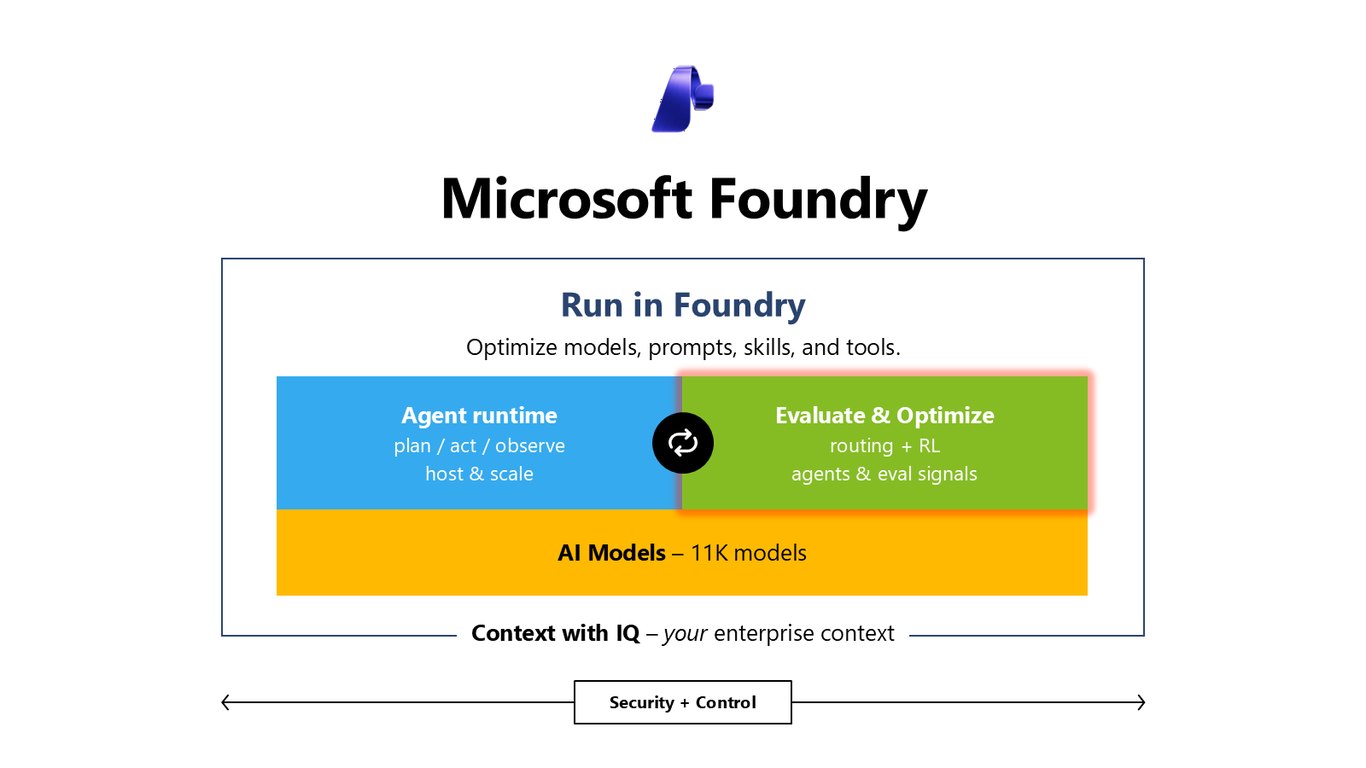
빌드부터 배포까지 하나의 루프
보시는 것처럼 모델, 프롬프트, 스킬, 툴을 최적화하고, 에이전트 런타임에서 plan·act·observe를 돌리며, 평가 신호로 다시 개선하는 순환 구조입니다. 오늘 이야기의 무대가 바로 이 Foundry 위에서 벌어집니다.
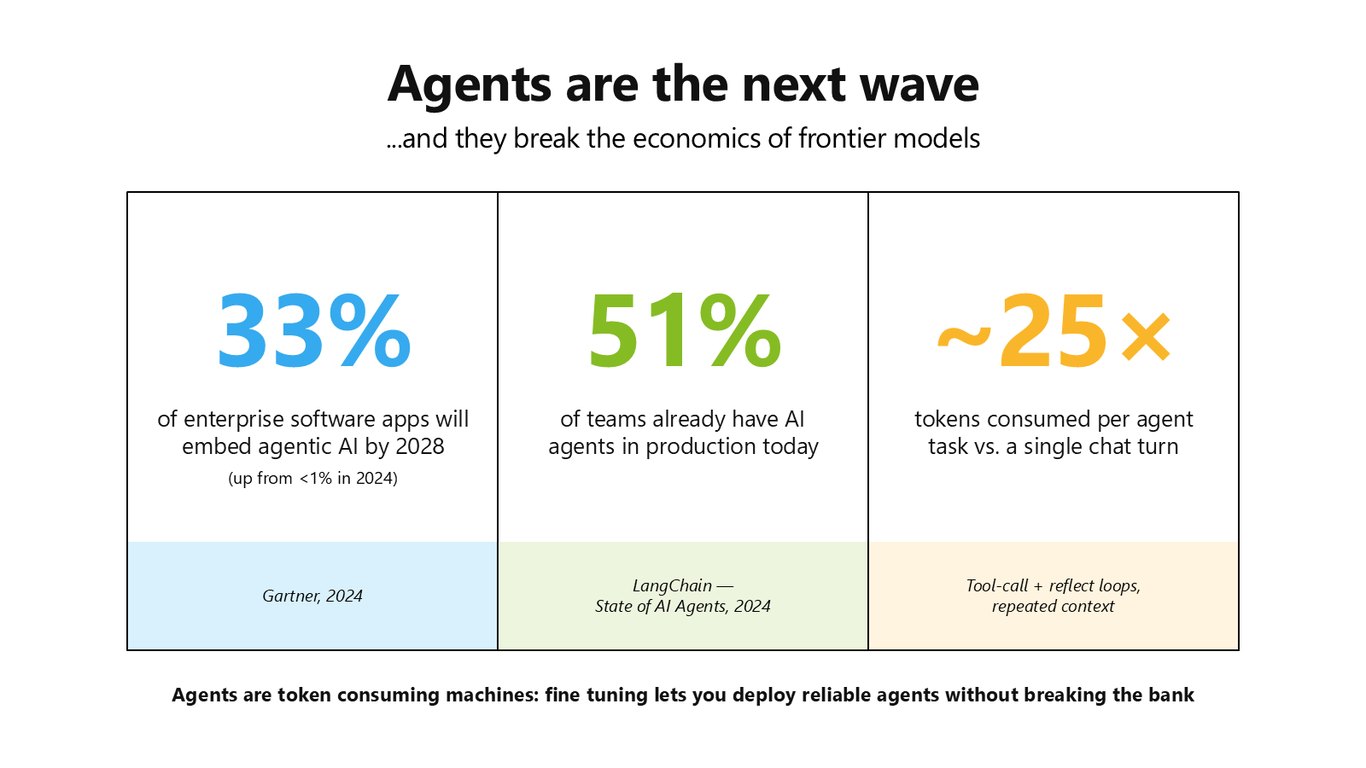
에이전트가 경제성을 깨뜨린다
에이전트는 다음 물결입니다. 2028년이면 엔터프라이즈 앱의 33%가 에이전트를 품게 되고, 이미 절반이 넘는 팀이 프로덕션에서 에이전트를 돌리고 있습니다. 그런데 에이전트 한 작업은 단일 챗 한 번보다 토큰을 약 25배나 먹습니다. 즉 에이전트는 토큰을 잡아먹는 기계라는 거죠. 파인튜닝이 있어야 예산을 깨뜨리지 않고 안정적인 에이전트를 배포할 수 있습니다.

더 싸고, 더 빠르고, 더 똑똑하게
모델 커스터마이징에는 세 가지 축이 있습니다. 품질을 끌어올려 적절한 툴을 적절한 순간에 부르게 하고, 작게 튜닝한 모델로 토큰당 비용을 10~30배 줄이며, 더 작은 모델로 3~10배 빠르게 스트리밍합니다. 프로덕션으로 가는 길은 이 세 축을 함께 잡는 데 있습니다.
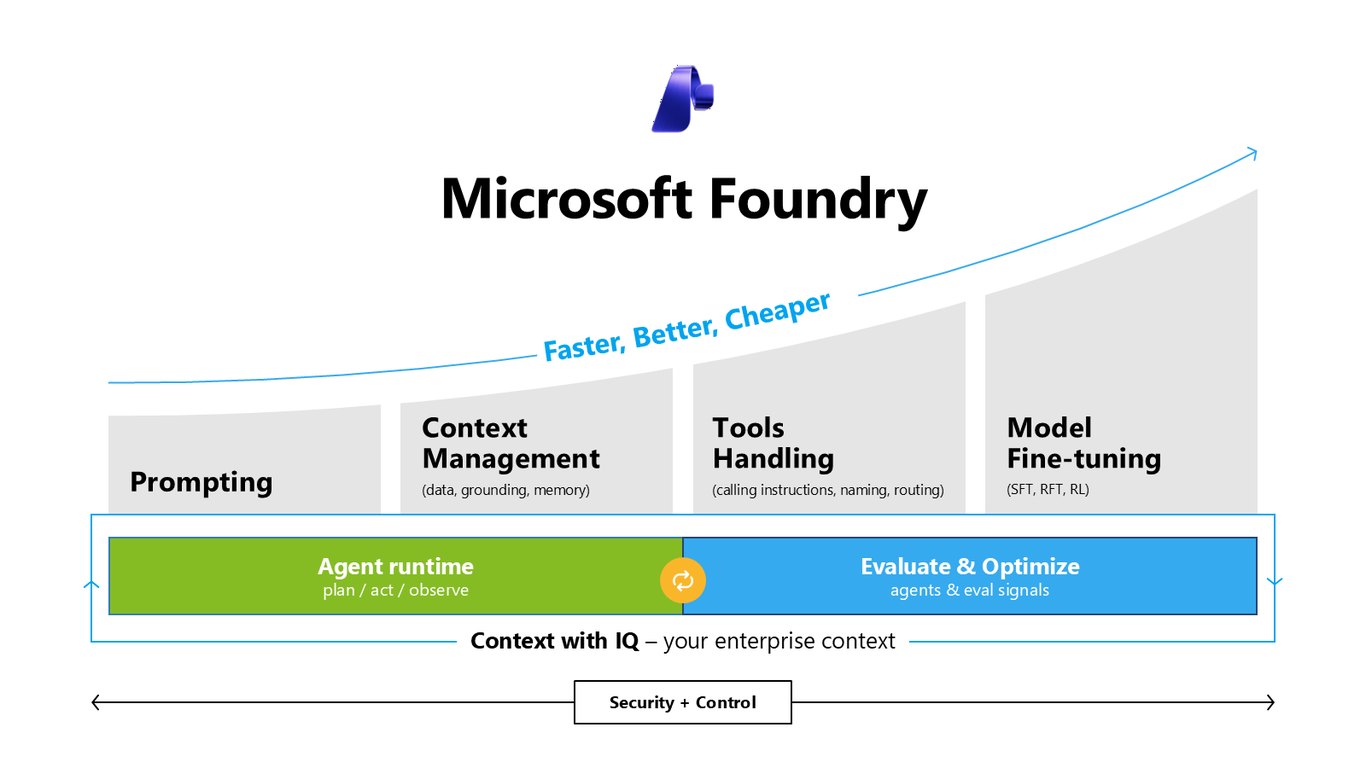
Faster, Better, Cheaper
결국 Foundry가 지향하는 방향은 하나입니다. 더 빠르고, 더 좋고, 더 저렴하게. 프롬프팅과 에이전트 런타임, 평가와 최적화를 하나로 묶어 여러분의 엔터프라이즈 컨텍스트 위에서 돌아가게 하는 거죠.
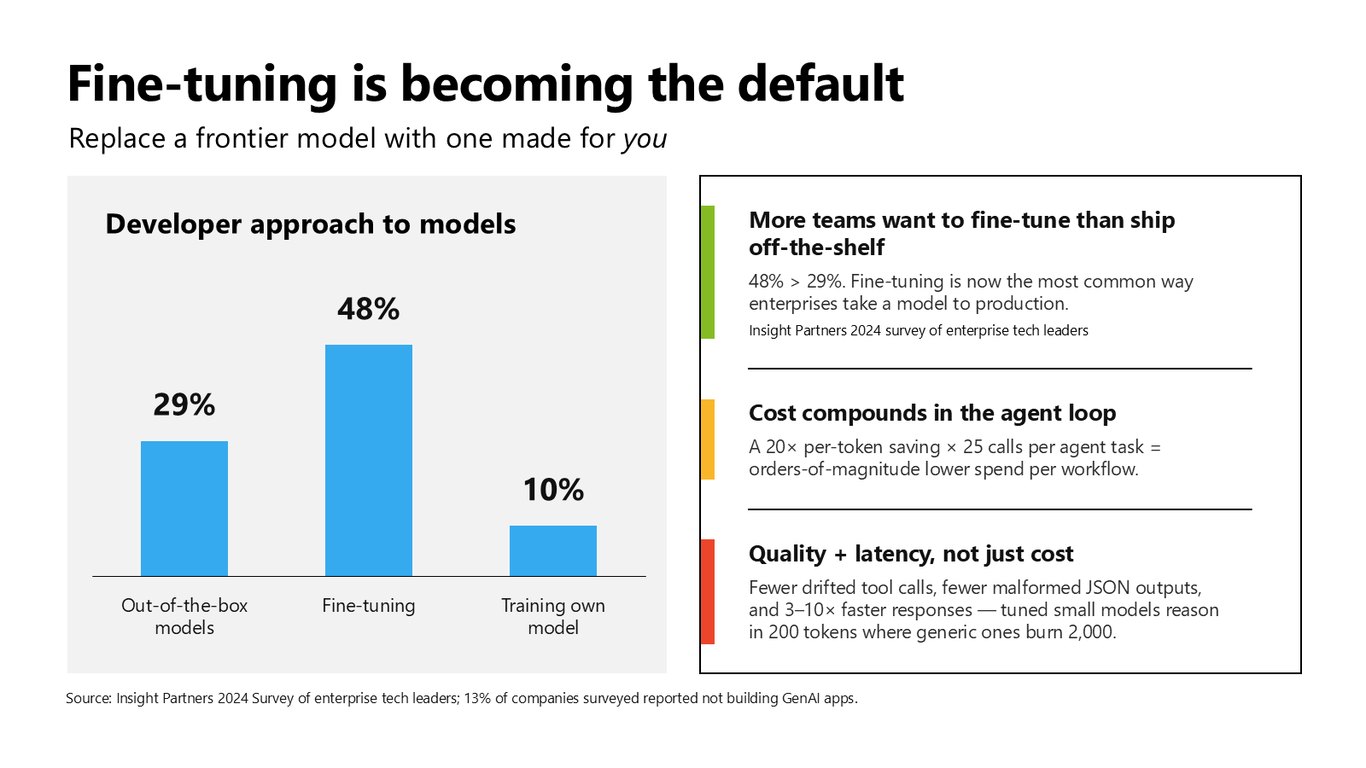
파인튜닝이 기본값이 되고 있다
이제 파인튜닝은 예외가 아니라 기본이 되어가고 있습니다. 설문을 보면 48%가 파인튜닝으로 프로덕션에 올린다고 답했는데, 이건 기성 모델을 그대로 쓰는 29%보다 많습니다. 에이전트 루프에서는 비용이 복리로 불어나기 때문에, 토큰당 20배 절감에 작업당 25번 호출이면 워크플로 비용이 자릿수 단위로 줄어듭니다. 비용뿐 아니라 품질과 지연시간까지 함께 잡히죠.
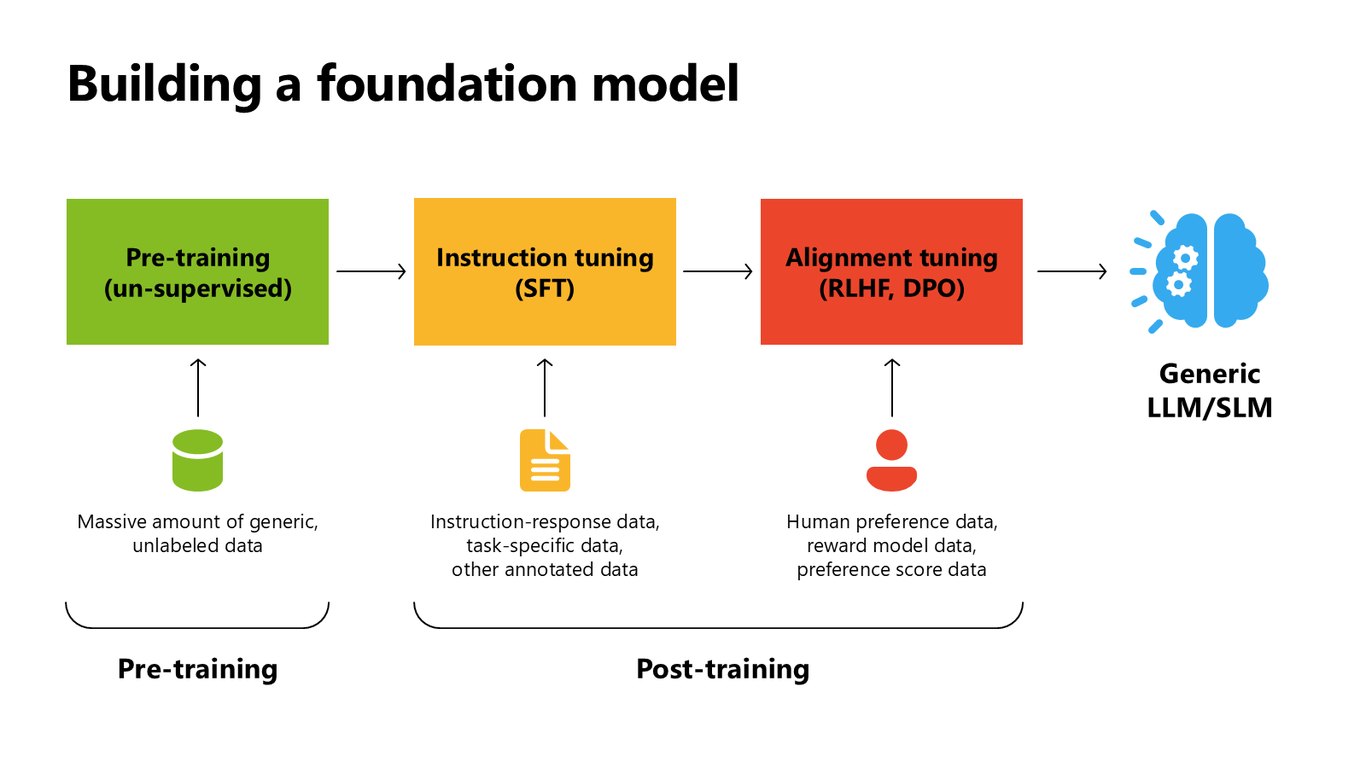
파운데이션 모델은 어떻게 만들어지나
파인튜닝을 제대로 이해하려면 모델이 어떻게 만들어지는지부터 봐야 합니다. 방대한 비지도 데이터로 사전학습을 하고, instruction tuning으로 지시를 따르게 하고, RLHF나 DPO로 사람 선호에 맞춰 정렬합니다. 이렇게 범용 LLM, SLM이 완성되는 거죠.
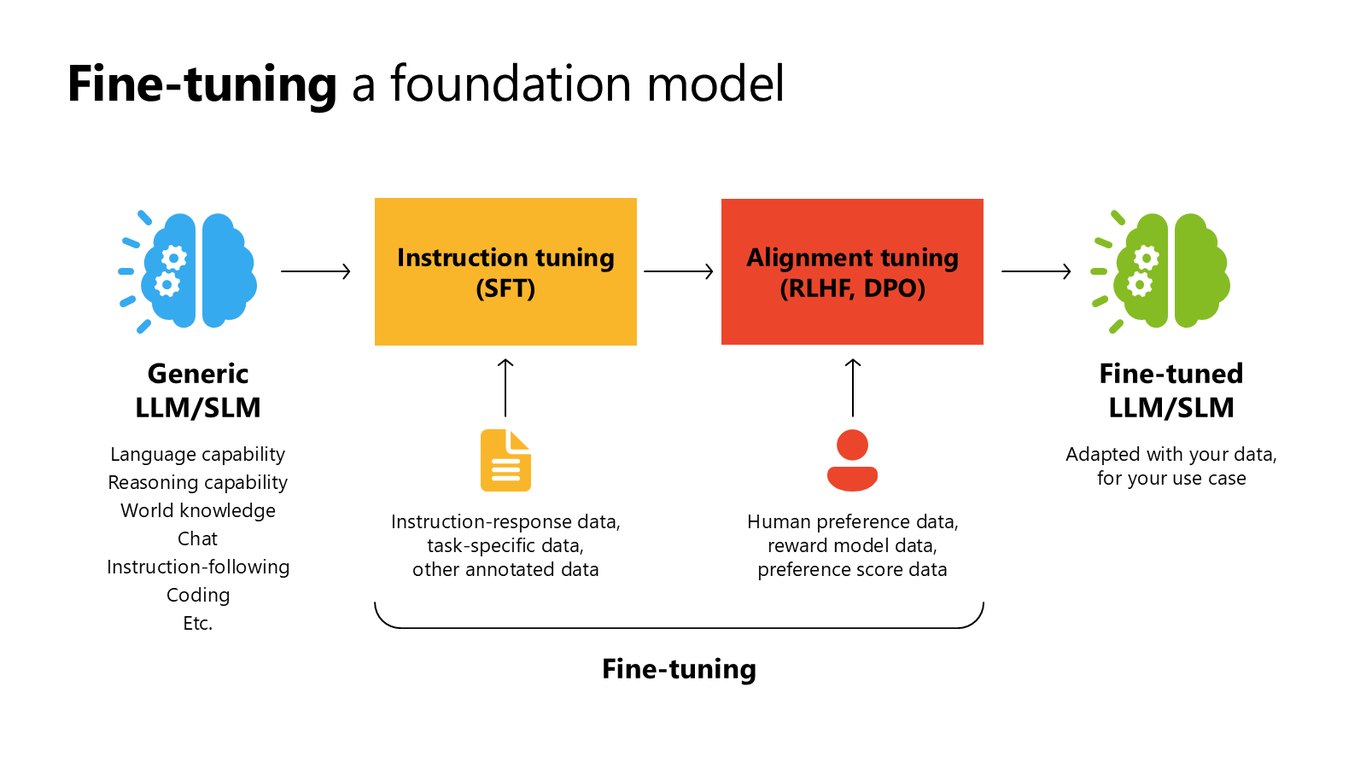
내 데이터로 다시 맞추는 파인튜닝
파인튜닝은 이렇게 만들어진 범용 모델을 여러분의 데이터와 유스케이스에 맞춰 다시 조정하는 과정입니다. 언어 능력과 추론, 세계 지식은 그대로 유지하면서 여러분의 과업에 특화된 모델로 바꿔주는 거죠.

이제 증류 이야기를 해보겠습니다. 프론티어 에이전트를 작게 튜닝한 모델로 옮겨 담으면, 같은 과업을 청구서의 일부 비용만으로 해낼 수 있습니다.
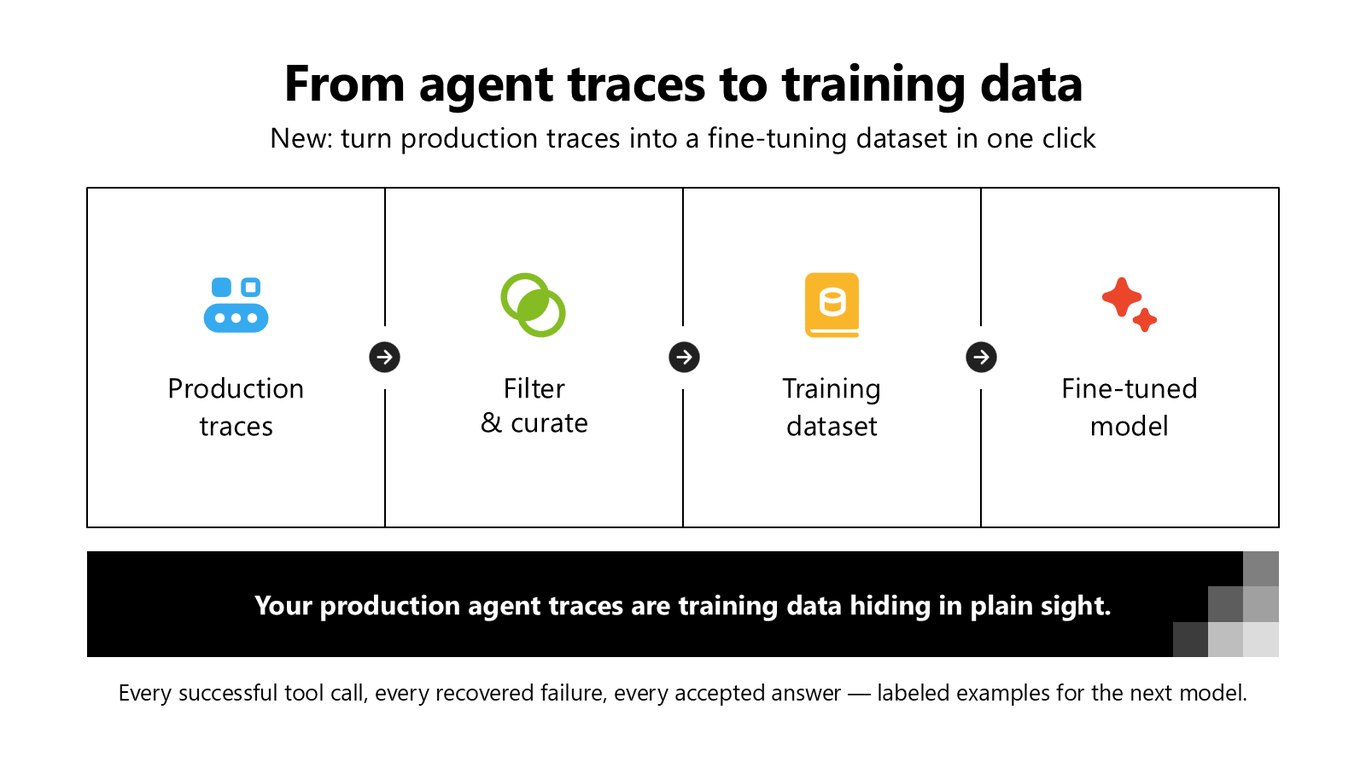
에이전트 트레이스가 곧 학습 데이터
여러분의 프로덕션 에이전트 트레이스는 사실 눈앞에 숨어 있는 학습 데이터입니다. 성공한 툴 호출, 복구된 실패, 승인된 답변 하나하나가 다음 모델을 위한 레이블 예시죠. 이제 이 트레이스를 필터링하고 큐레이션해서 클릭 한 번으로 파인튜닝 데이터셋으로 만들 수 있습니다.

선생이 충분히 똑똑하지 않다면?
그런데 증류에는 천장이 있습니다. 학생이 선생을 베끼는 구조라서 선생의 실력을 넘어설 수 없죠. 강화 파인튜닝은 다릅니다. 모델이 스스로의 rollout에서 배우고, 목표는 선생이 아니라 보상이 정의합니다. 그래서 데이터를 만든 모델보다 더 잘할 수 있고, 정답을 검증할 수 있는 과업에 딱 맞습니다.

이제 강화학습으로 넘어가겠습니다. 핵심은 간단합니다. 답을 그냥 써 내려가는 게 아니라, 답이 맞았는지 검증할 수 있는 과업에서 모델이 자기 실수로부터 배우게 하는 겁니다.
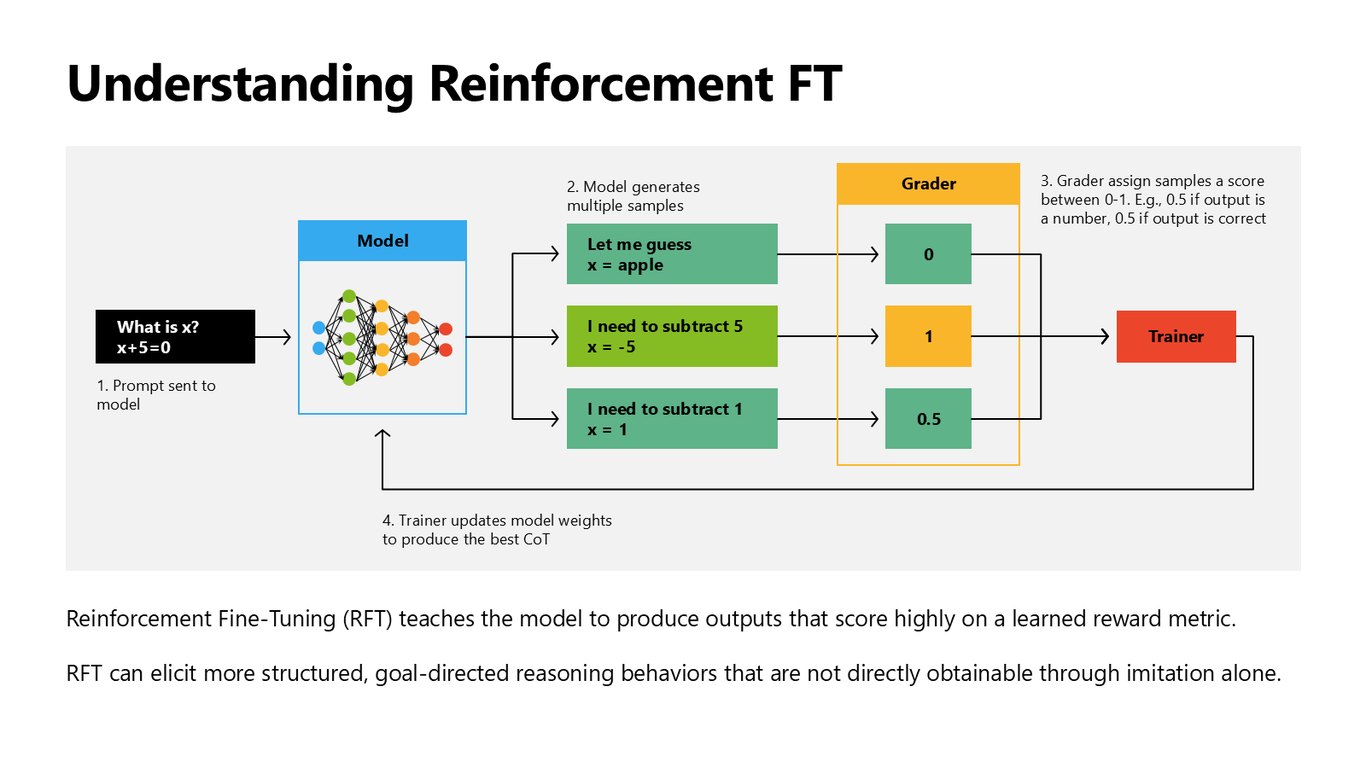
강화 파인튜닝은 이렇게 동작한다
동작 방식을 보겠습니다. 프롬프트를 모델에 주면 여러 샘플을 생성하고, grader가 각 샘플에 0에서 1 사이 점수를 매깁니다. 예를 들어 숫자면 0.5, 정답이면 0.5를 더하는 식이죠. 그러면 trainer가 높은 점수를 내는 사고 과정을 만들도록 가중치를 업데이트합니다. 이렇게 하면 단순 모방으로는 얻을 수 없는, 더 구조적이고 목표 지향적인 추론이 나옵니다.
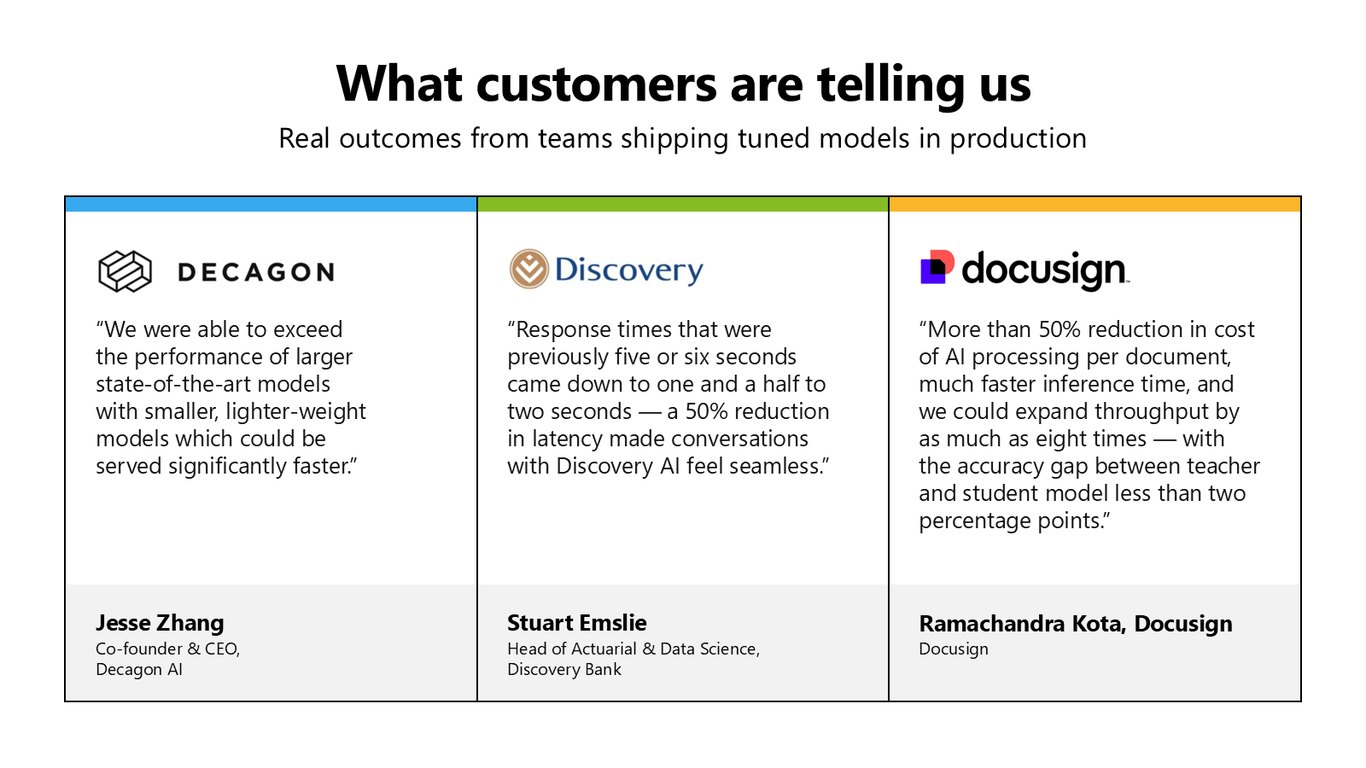
고객들이 전하는 실제 성과
실제로 프로덕션에서 튜닝 모델을 쓰는 팀들의 이야기를 들어보죠. Decagon AI는 더 가벼운 모델로 더 큰 최신 모델의 성능을 넘어섰고, Discovery Bank는 응답 시간을 5~6초에서 1.5~2초로 절반 넘게 줄였습니다. Docusign은 문서당 처리 비용을 50% 이상 줄이면서 처리량을 8배까지 늘렸는데, 정확도 차이는 2%포인트 미만이었습니다.

더 많은 제어가 필요하다면
기본 파이프라인만으로 부족할 때를 위해 제어 장치도 열어두었습니다. 여러분만의 심사 기준으로 rollout에 점수를 매기는 custom reward, 시뮬레이터와 툴 서버를 붙이는 custom rollout 환경, 직접 스크립팅하는 데이터 큐레이션, 그리고 reasoning effort부터 배치 크기, 학습률까지 하이퍼파라미터를 완전히 제어할 수 있습니다.

그 중심에 Interactive Training API가 있습니다. 여러분은 환경과 보상만 가져오세요. rollout과 채점, 학습은 저희가 다 처리해 드립니다.
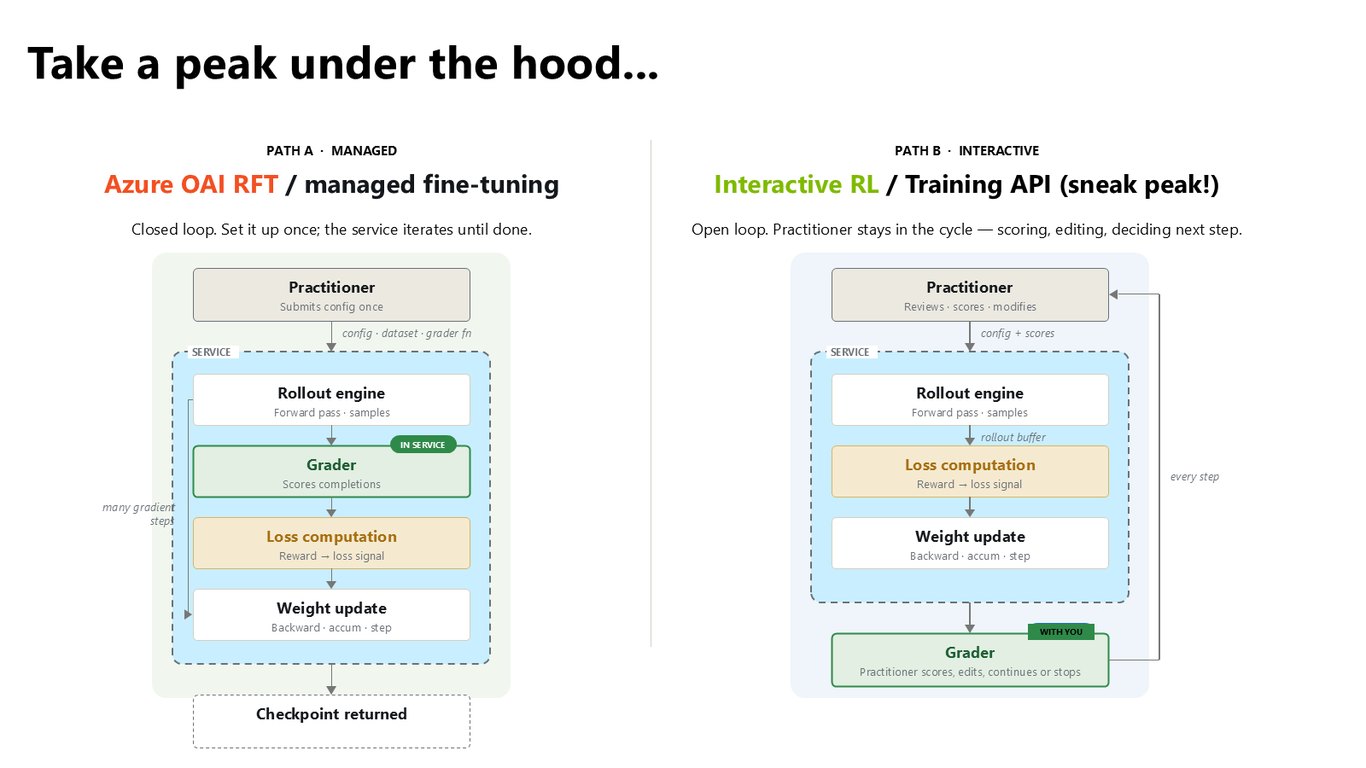
내부를 들여다보자
자, 그러면 이 API가 후드 아래에서 실제로 어떻게 돌아가는지 잠깐 들여다보겠습니다.
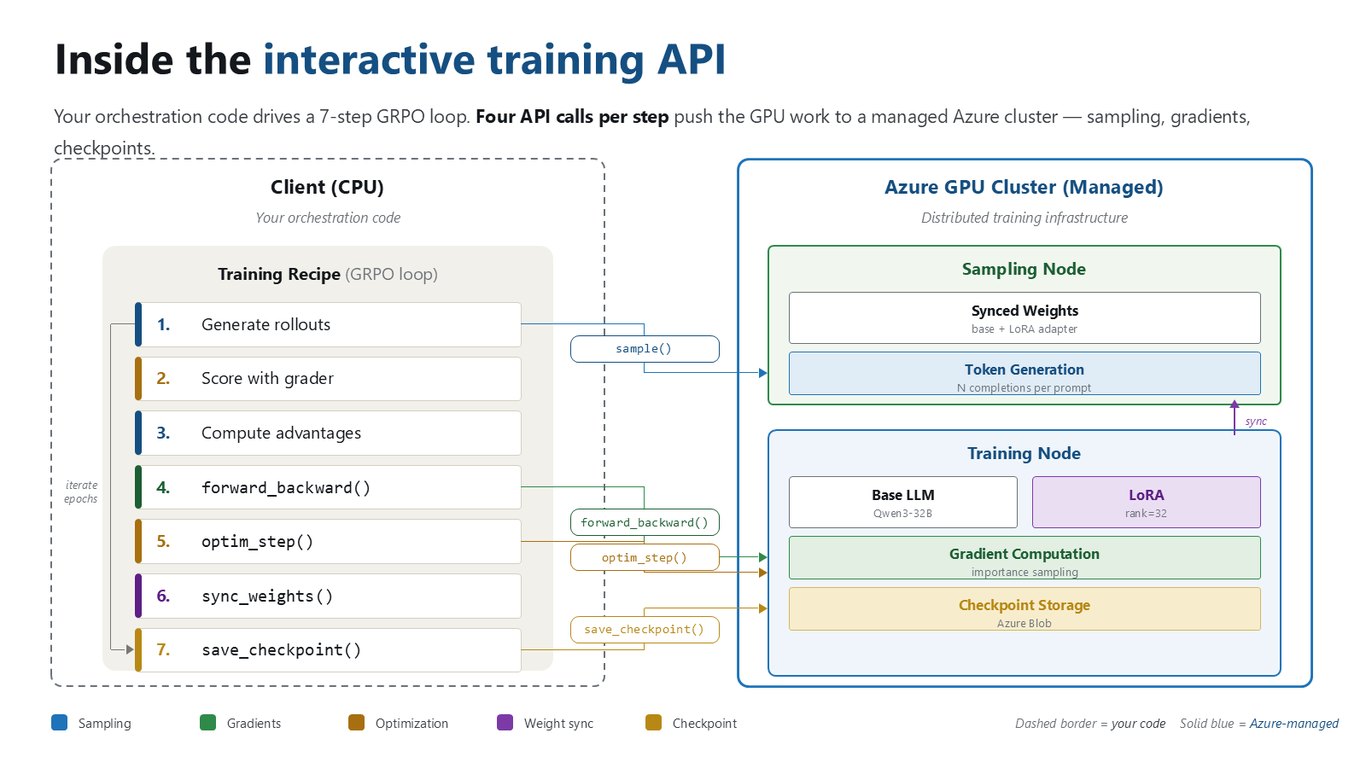
Interactive Training API의 내부 구조
여러분의 오케스트레이션 코드가 7단계 GRPO 루프를 돌립니다. rollout 생성, grader 채점, advantage 계산부터 forward_backward, optim_step, weight sync, checkpoint 저장까지죠. 단계마다 네 번의 API 호출이 GPU 작업을 관리형 Azure 클러스터로 넘깁니다. 샘플링 노드와 학습 노드가 Qwen3-32B 기반에 LoRA 어댑터로 무거운 연산을 대신 처리해 줍니다. 점선은 여러분의 코드, 파란 실선은 Azure가 관리하는 부분입니다.

슬슬 걱정되시나요?
여기까지 들으면 파인튜닝이 어렵게 느껴질 수 있습니다. "데이터 사이언티스트도 아닌데 어디서 시작하죠", "학습시킬 데이터도 없고 만들 시간도 없어요", "한번 해봤는데 오히려 모델이 더 나빠졌어요" 같은 목소리를 많이 듣습니다. 사실 파인튜닝을 하겠다던 팀 대부분이 결국 튜닝 모델을 출시하지 못합니다. 그래서 저희가 도와드리려고 나왔습니다.

그래서 준비한 게 파인튜닝 스킬입니다. 얼마나 쉽냐면 PM도 할 수 있을 정도예요. 아이디어에서 실험으로, 실험에서 프로덕션까지 한 번에 이어집니다.
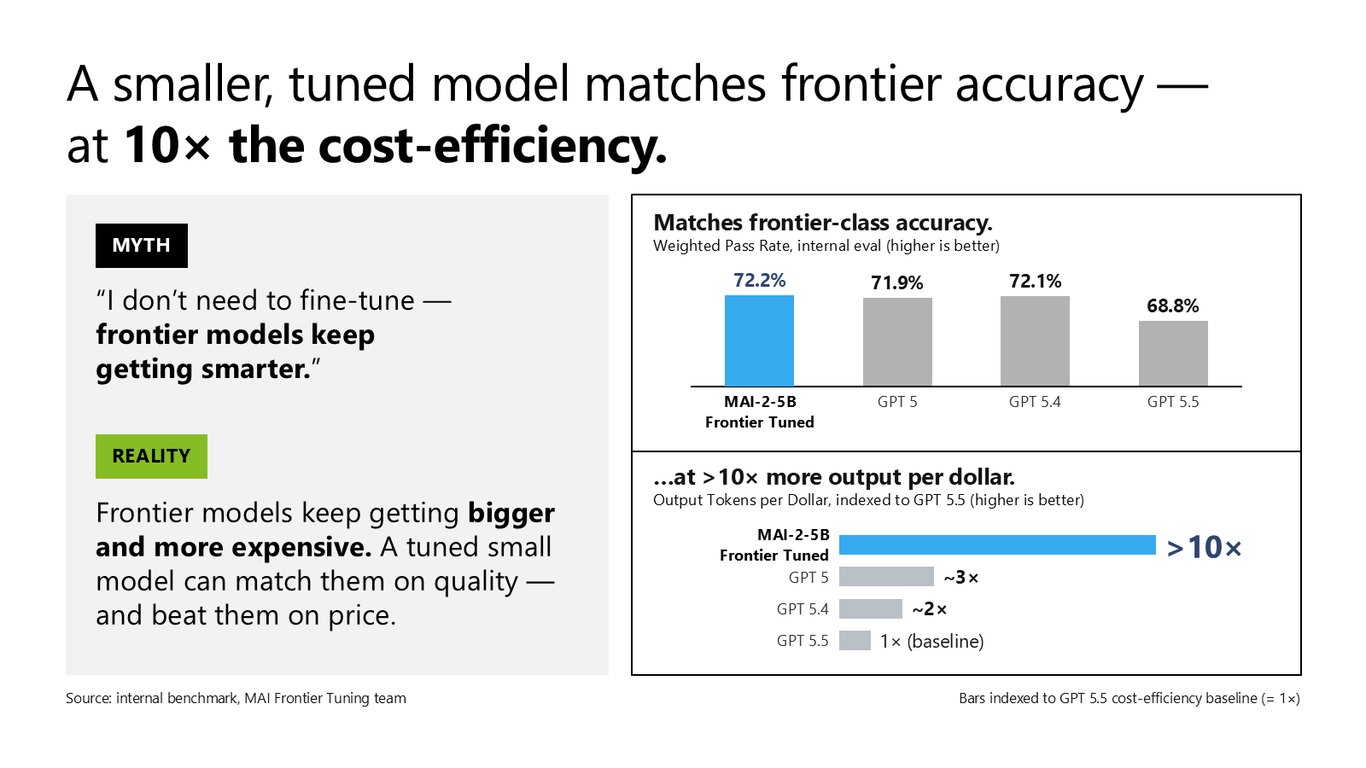
통념 1: 프론티어면 충분하다?
첫 번째 통념부터 깨보죠. "프론티어 모델이 점점 똑똑해지니 파인튜닝은 필요 없다"고들 하는데, 현실은 프론티어 모델은 점점 커지고 비싸집니다. 저희 내부 평가에서 튜닝한 MAI-2-5B는 72.2%로 GPT 5, 5.4와 어깨를 나란히 하면서, 달러당 출력 토큰은 10배 이상 뽑아냈습니다. 품질은 맞추고 가격에서 이기는 거죠.
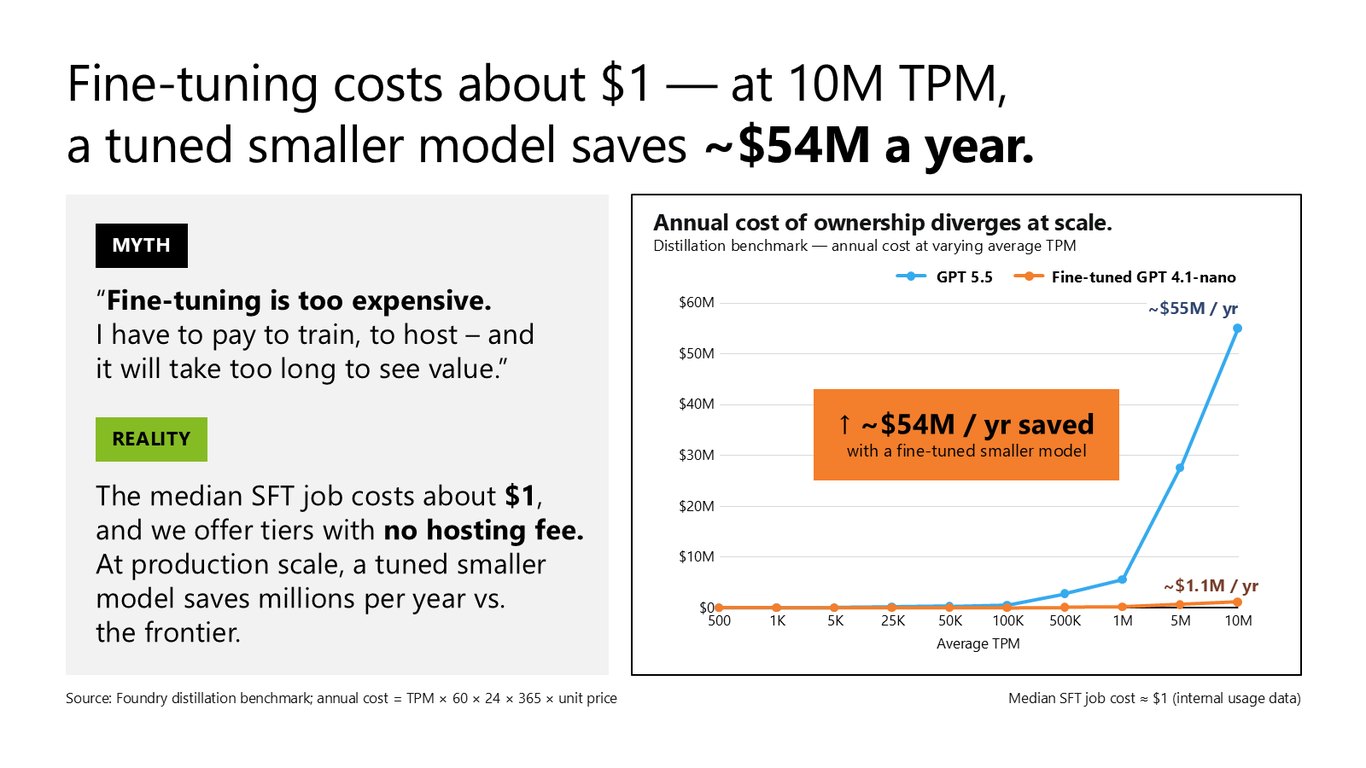
통념 2: 파인튜닝은 너무 비싸다?
두 번째 통념, "파인튜닝은 너무 비싸다"도 마찬가지입니다. 중간값 기준 SFT 작업 비용은 약 1달러이고, 호스팅 비용이 없는 티어도 제공합니다. 프로덕션 규모로 가면 격차가 벌어지는데, 분당 1천만 토큰 수준에서 튜닝한 작은 모델은 프론티어 대비 연간 약 5,400만 달러를 아껴줍니다.
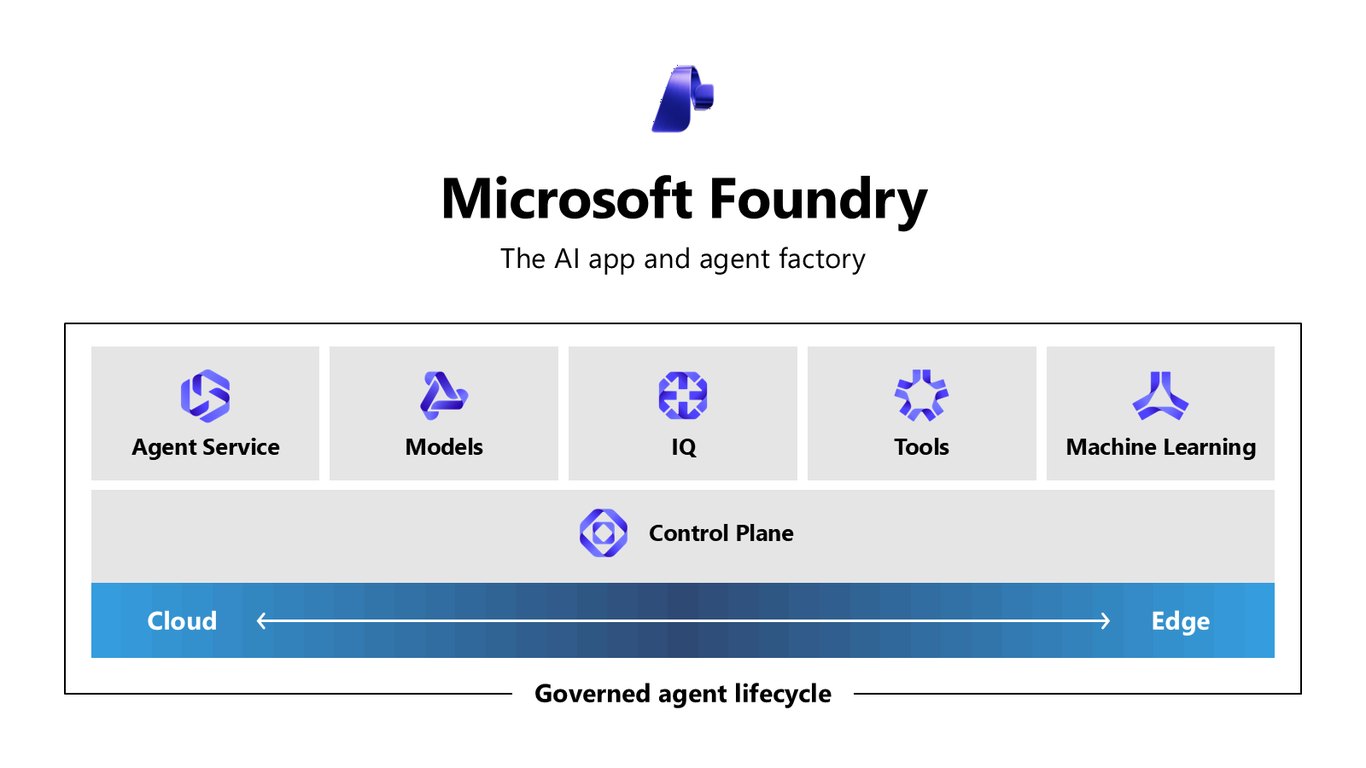
AI 앱과 에이전트 팩토리
정리하면 Microsoft Foundry는 AI 앱과 에이전트를 찍어내는 팩토리입니다. Agent Service, Models, IQ, Tools, Machine Learning이 하나의 관리형 컨트롤 플레인 위에서 클라우드와 엣지를 아우르며, 에이전트의 라이프사이클 전체를 거버넌스 아래 관리합니다.

오늘 배운 걸로 여러분의 에이전트 튜닝을 오늘 밤 당장 시작해 보시길 바랍니다. 감사합니다.

모든 단계에서 함께합니다
시작은 혼자가 아닙니다. ai.azure.com에서 Microsoft Foundry로 빌드를 시작하고, aka.ms/build26-BRK231에서 이번 세션 코드를 받아가시고, aka.ms/ai/discord 커뮤니티에도 꼭 들러 주세요.

더 배우고 싶다면
이 주제를 더 파고들고 싶다면 이어지는 세션들도 추천드립니다. 에이전트 트레이스로 RL을 돌리는 LAB521, 커스텀 OSS 추론 모델을 다루는 BRK232, 더 똑똑한 학습 패턴의 LTG418, 그리고 증류를 다루는 DEM322까지 온디맨드로도 보실 수 있습니다.

세션 리소스와 설문
마지막으로, 세션 상세 페이지에서 튜토리얼과 코드를 바로 실행해 보실 수 있습니다. aka.ms/build/evals에 방문하거나 QR 코드를 스캔해서 설문에도 꼭 참여해 주세요. 감사합니다.