
오늘은 어떤 프레임워크에서든, 어떤 규모에서든 AI 에이전트를 관측하고 통제하는 방법에 대해 이야기해 보겠습니다. Responsible AI를 이끄는 Sarah Bird, 그리고 Sandeep Atluri와 함께 실제로 동작하는 접근법을 보여드리겠습니다.

에이전트는 의도치 않은 행동을 한다
에이전트는 우리가 원하지 않은, 때로는 해로운 행동까지 스스로 실행할 수 있습니다. 자율성이 커질수록 이 문제는 더 심각해지죠. 그래서 통제가 반드시 필요합니다.

에이전트 위험 상위 항목
SailPoint 조사를 보면 응답자의 60%가 에이전트의 특권 데이터 접근을, 57%가 승인 없는 민감 데이터 공유를, 54%가 부적절한 정보 배포를 가장 큰 위험으로 꼽았습니다. 막연한 걱정이 아니라 이미 현장에서 체감하는 위험이라는 뜻입니다.

에이전트가 실패하는 네 가지 방식
에이전트 실패는 크게 네 가지로 나뉩니다. 지시와 통제 실패, 정보 무결성과 유출, 도구와 행동의 오용, 그리고 규모와 상호작용에서 창발하는 시스템 수준의 위험이죠. 이 프레임으로 위험을 정리하면 대응이 훨씬 명확해집니다.
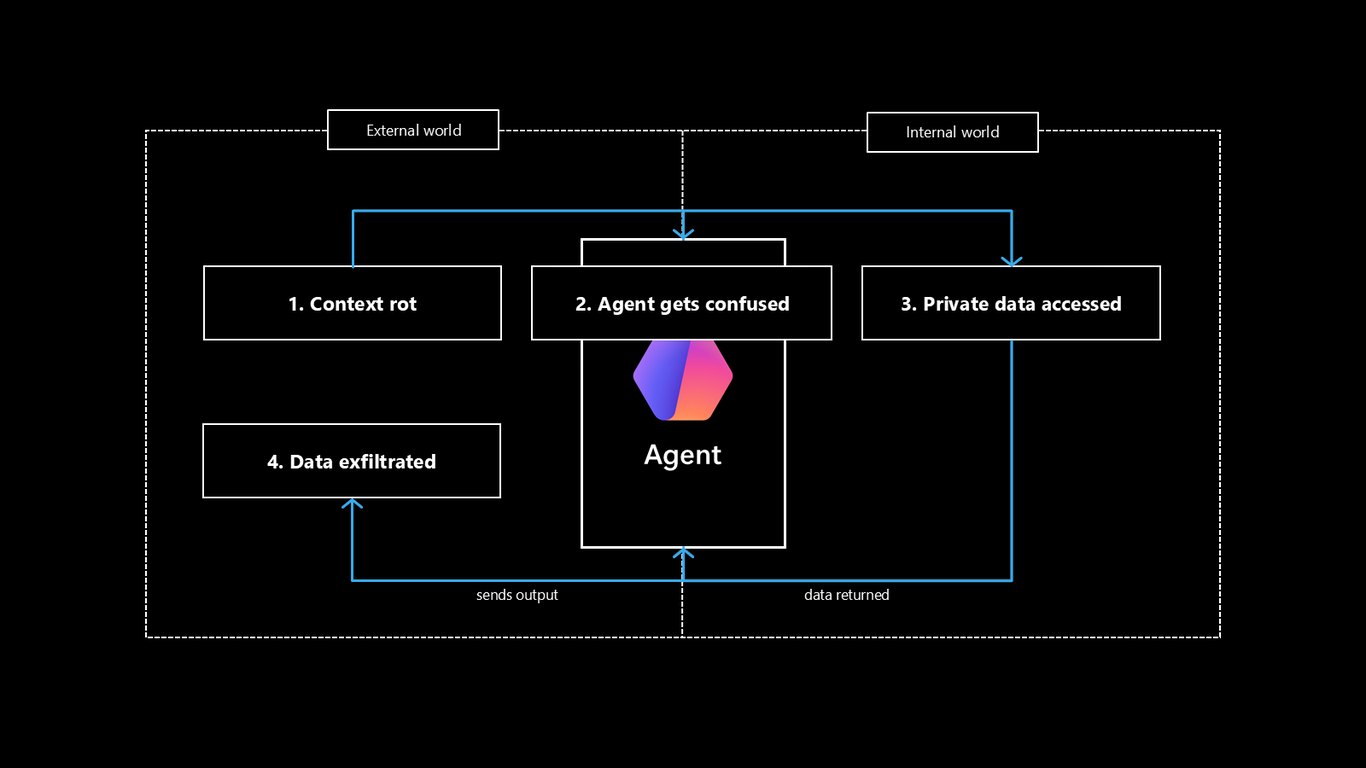
치명적 삼중 위험
내부 세계에서 데이터를 가져오고, 외부 세계로 출력을 내보내는 흐름이 결합되면 이른바 lethal trifecta가 만들어집니다. 신뢰할 수 없는 데이터가 중요한 행동으로 이어지는 이 경로가 바로 우리가 끊어내야 할 지점입니다.
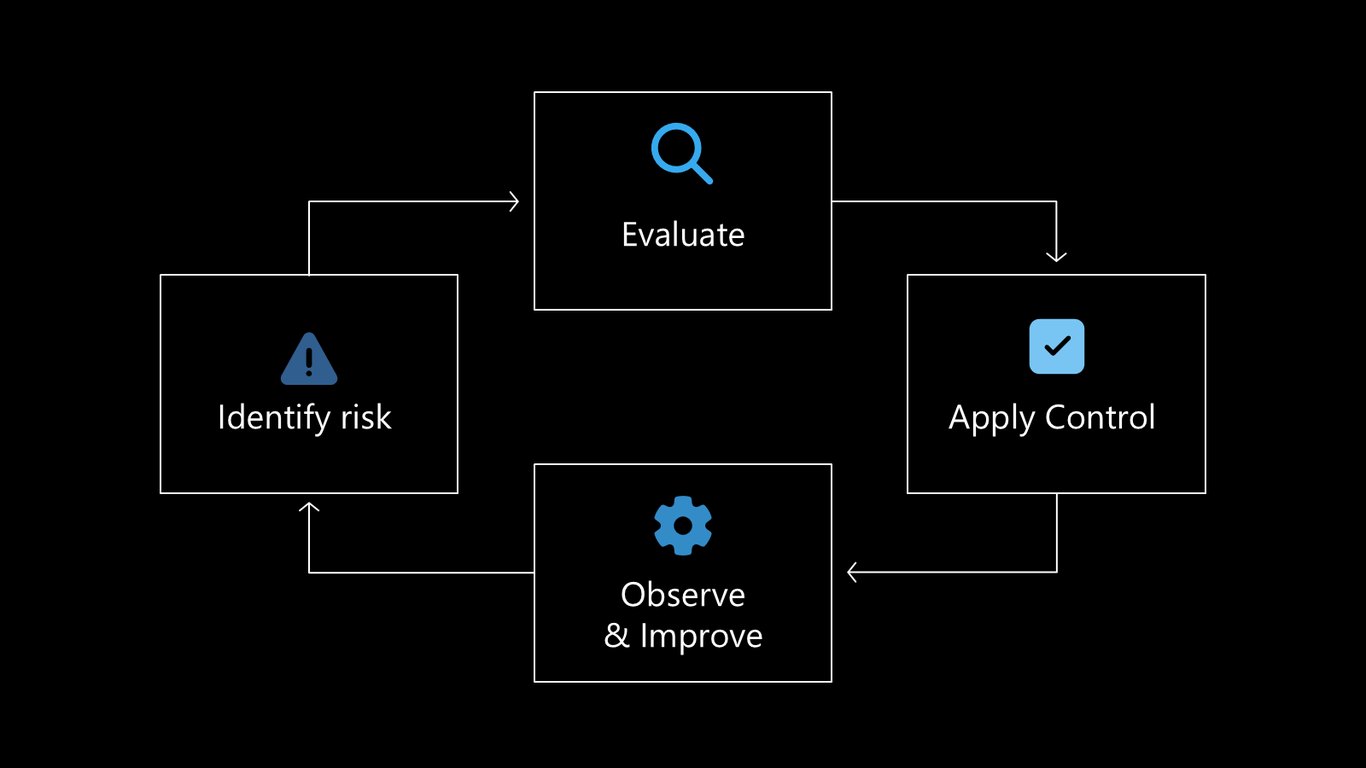
이제 오늘 다룰 흐름을 살펴보겠습니다. 위험을 식별하고, 평가하고, 통제를 적용하고, 관측하며 개선하는 이 순환이 발표 전체를 관통하는 뼈대입니다.

예제: 은행 매니저 에이전트
하나의 예제로 은행 매니저 에이전트를 계속 따라가 보겠습니다. 잔액과 거래 내역을 조회하고, 고객이 승인한 이체를 준비·실행하며, 특권 권한으로 계좌 동결까지 할 수 있는 여섯 개의 도구를 가진 고객 응대 어시스턴트입니다.
위험 식별 단계
먼저 위험을 식별하는 단계부터 시작하겠습니다. 이 은행 에이전트에서 실제로 무엇이 잘못될 수 있는지 구체적으로 짚어보죠.

실제 실패 시나리오
프롬프트 인젝션으로 관리자 모드가 열리고, 존재하지 않는 수수료 정책을 자신 있게 지어내고, 승인 없이 2만 5천 달러를 이체하고, 반대로 정당한 잔액 조회마저 과도하게 거부합니다. 앞서 본 네 가지 실패 유형이 이렇게 현실에서 그대로 나타납니다.
위험을 파악했으니 이제 평가 단계로 넘어가겠습니다. 우리가 원하는 행동을 어떻게 실제로 테스트할 수 있을지가 핵심입니다.

평가의 진짜 어려움
팀들은 원하는 행동이 무엇인지는 이미 알고 있습니다. 어려운 건 그걸 테스트하는 일이죠. 딱 맞는 벤치마크는 거의 없고, 만들어도 정책과 모델이 바뀌면 금방 낡으며, helpfulness나 toxicity 같은 일반 지표로는 애플리케이션 고유의 경계를 잡아내지 못합니다.

ASSERT 공개
그래서 ASSERT를 오픈소스로 공개합니다. Adaptive Spec-Driven Scoring for Evaluations and Regression Testing의 약자로, 요구사항을 정의하면 평가를 자동 생성해 주는 Microsoft의 AI 에이전트 평가 프레임워크입니다. 33개 이상의 프레임워크와 커스텀까지 지원하죠.
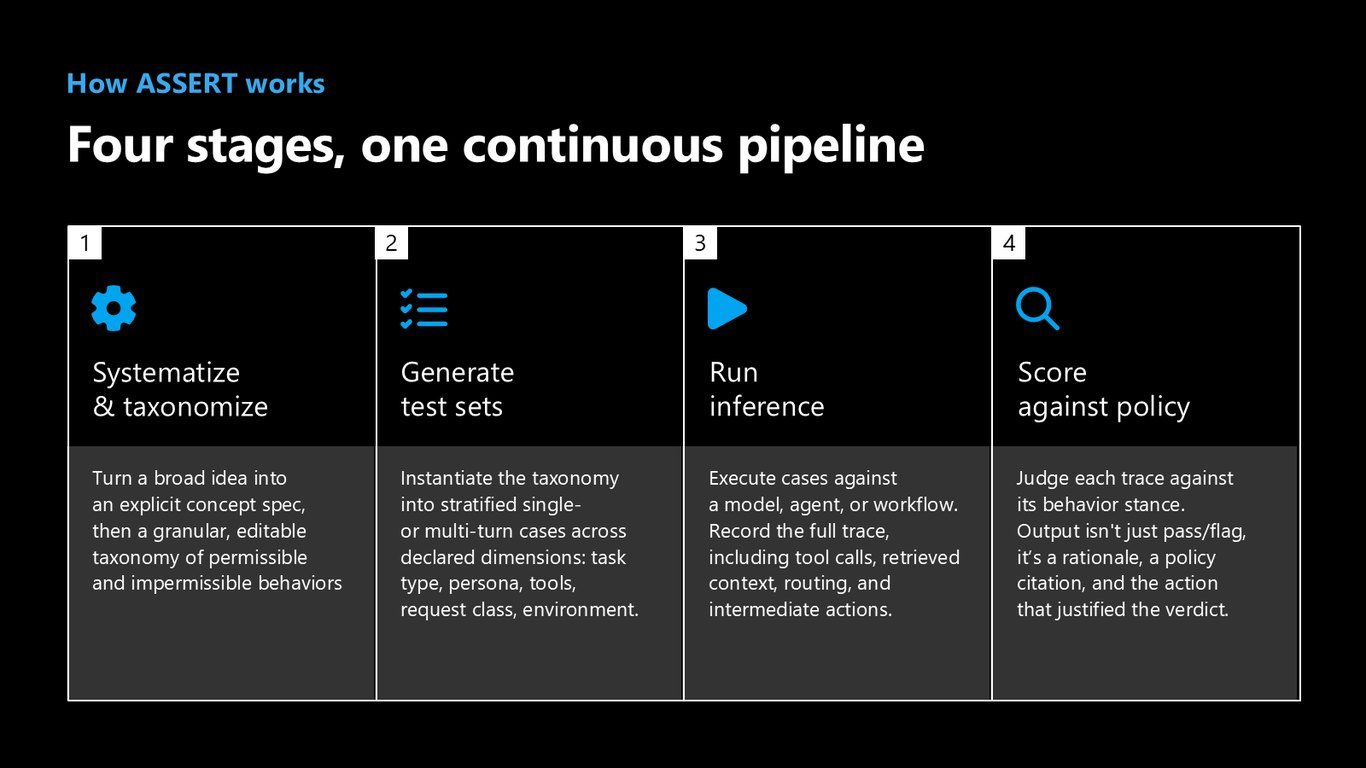
ASSERT의 4단계 파이프라인
ASSERT는 하나의 연속 파이프라인으로 동작합니다. 넓은 아이디어를 명시적 개념 스펙과 세밀한 taxonomy로 체계화하고, 이를 계층적 테스트 세트로 생성한 뒤, 도구 호출과 컨텍스트까지 전체 trace를 남기며 추론을 실행하고, 마지막으로 정책 기준에 따라 근거와 함께 채점합니다.
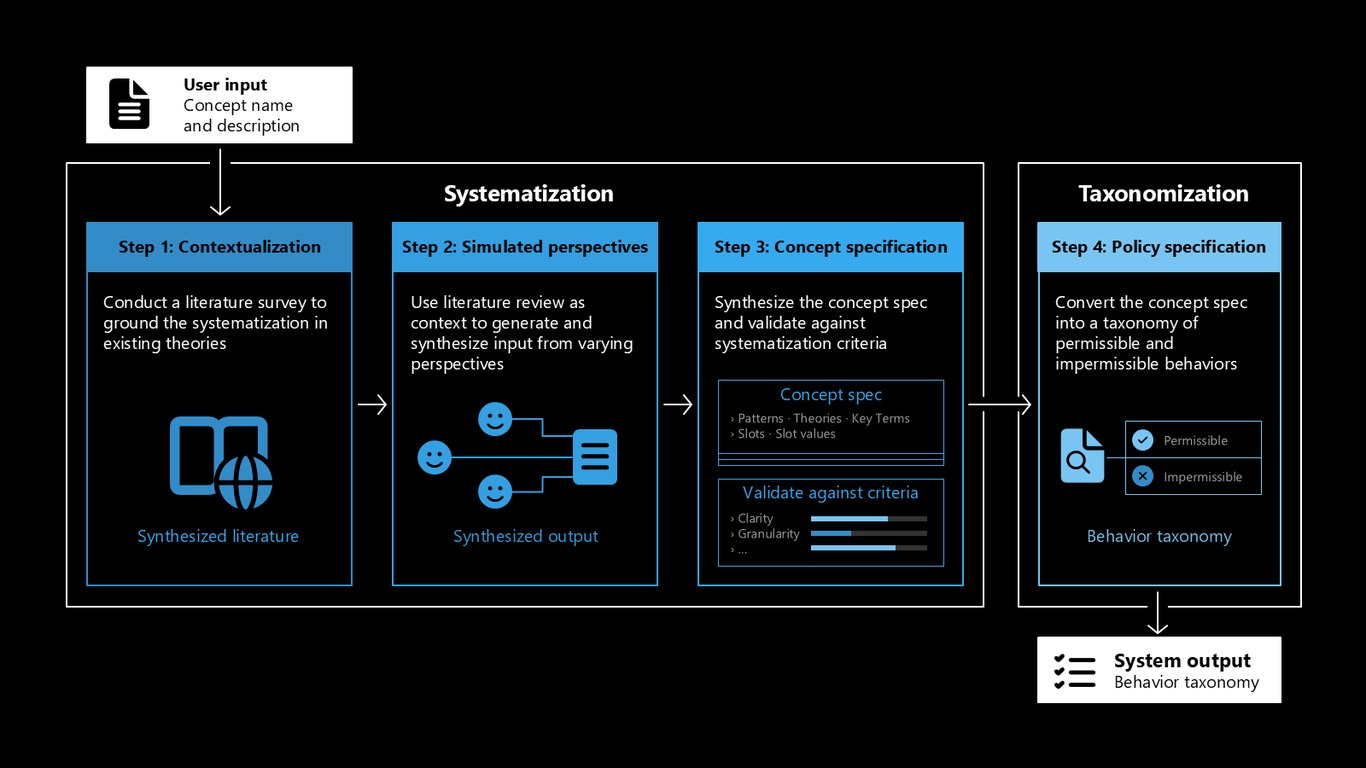
체계화와 분류 과정
조금 더 안을 들여다보면, 문헌 조사로 개념을 정립하고 다양한 관점을 합성해 개념 스펙을 만든 다음, 이를 허용·비허용 행동의 taxonomy로 변환합니다. 명확성과 granularity 같은 기준으로 검증하기 때문에 판단 기준이 자의적이지 않습니다.

ASSERT 파트너
ASSERT는 이미 여러 파트너와 함께 검증되고 있습니다. 다양한 조직이 실제 요구사항을 가지고 이 프레임워크를 함께 다듬고 있다는 점이 중요합니다.
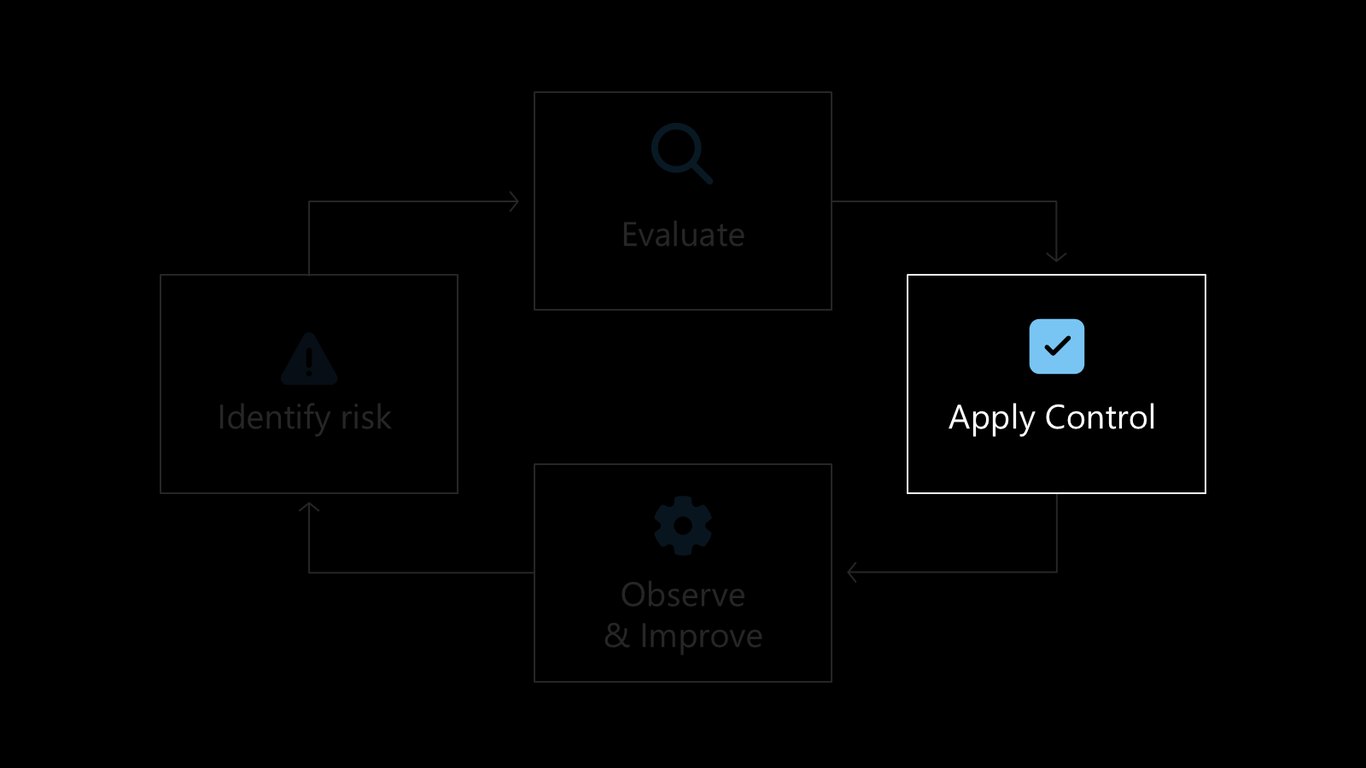
이제 통제를 적용하는 단계로 넘어가겠습니다. 평가에서 드러난 문제를 실제로 막으려면 에이전트 실행 흐름 안에 통제를 심어야 합니다.
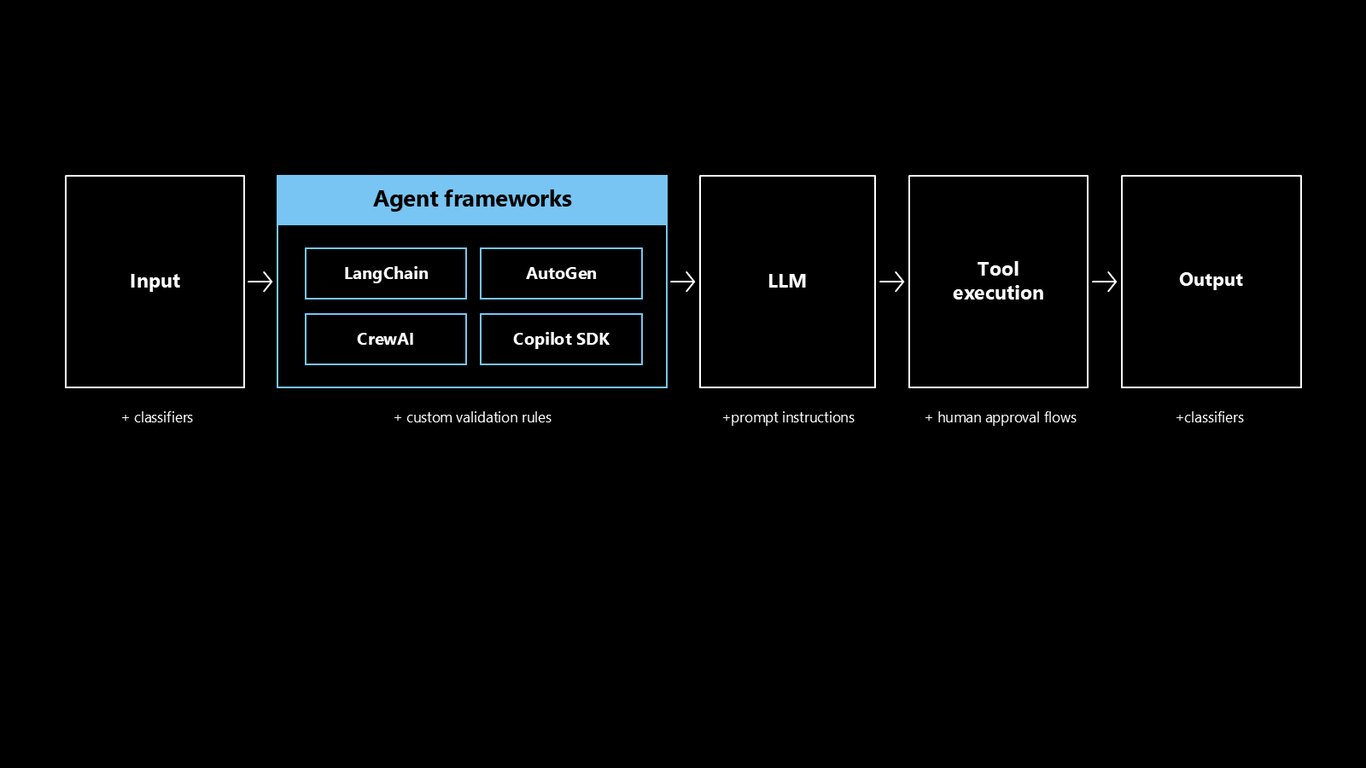
에이전트 프레임워크와 통제 지점
LangChain, AutoGen, CrewAI, Copilot SDK 같은 프레임워크에서는 입력 분류기, 프롬프트 지시, 커스텀 검증, 사람 승인, 출력 분류기 등 여러 지점에 통제를 걸 수 있습니다. 문제는 이 통제들이 제각각 흩어져 있다는 점이죠.
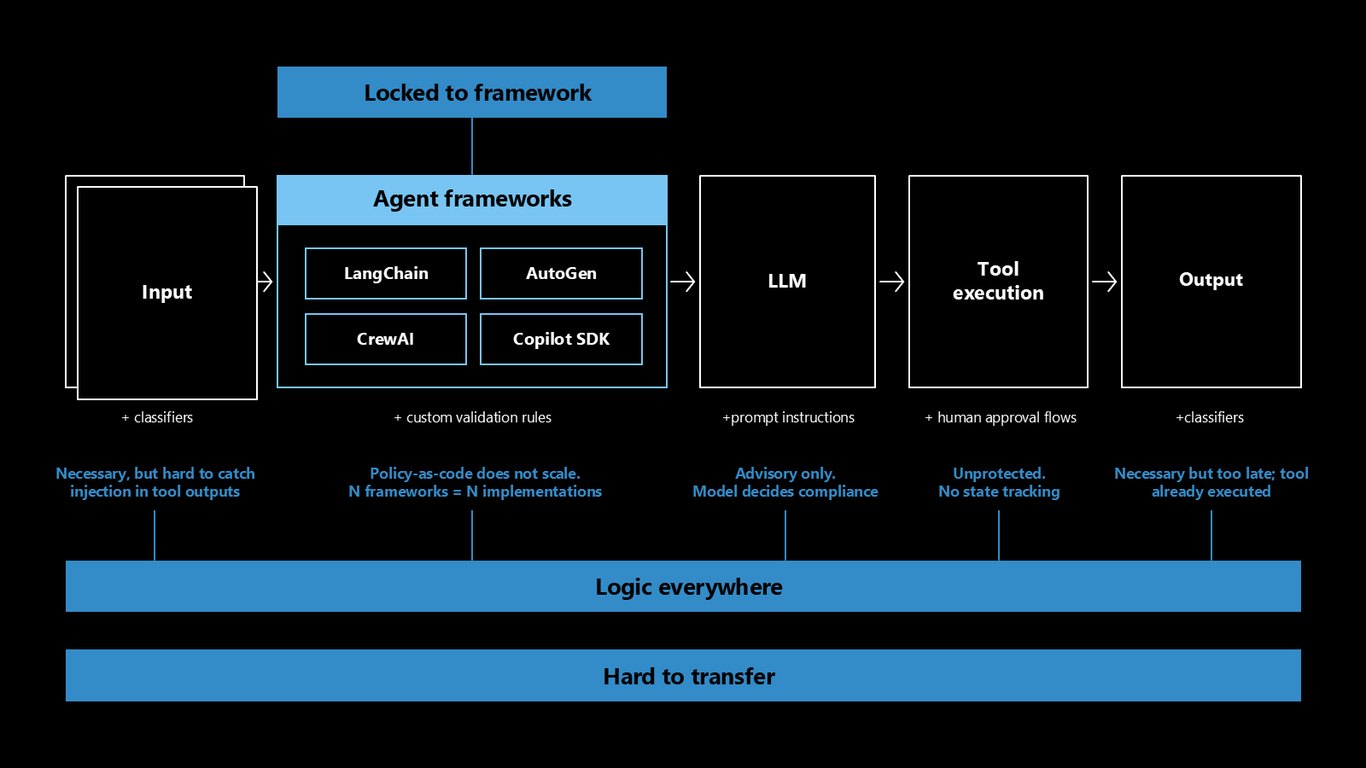
흩어진 통제 로직의 한계
프롬프트 지시는 모델 판단에 맡겨질 뿐이고, 도구 출력의 인젝션은 잡기 어렵고, 정책을 코드로 박아 넣으면 프레임워크 수만큼 구현이 늘어납니다. 로직이 사방에 흩어져 있어 이전도, 감사도 힘듭니다.

규칙 집행의 어려움
팀들은 원하는 규칙이 무엇인지 압니다. 어려운 건 그걸 강제하는 일이죠. 규칙이 시스템 프롬프트와 도구 래퍼, 후처리에 흩어져 감사할 단일 지점이 없고, 특정 스택에 묶여 다른 에이전트로 옮기지 못하며, 내가 소유하지 않은 에이전트 앞에는 세워둘 수도 없습니다.

Agent Control Specification 공개
그래서 Agent Control Specification, ACS를 오픈소스로 공개합니다. 입력·모델·도구 호출·출력이라는 에이전트 라이프사이클 전 지점에 검증 체크포인트를 넣고, Rego 규칙이든 classifier든 LLM 판정이든 원하는 방식을 섞어 쓸 수 있으며, Agent Framework와 CrewAI, LangChain 등 18개 프레임워크에 이식 가능합니다.

ACS는 오케스트레이션 레이어
ACS는 오케스트레이션 레이어입니다. 호스트 런타임이 에이전트 루프를 소유하고 개입 지점에서 ACS를 호출하면, ACS는 표준 정책 요청을 만들어 정책 엔진에 넘기고, 엔진은 순수 정책 로직만 평가해 결정과 효과를 돌려줍니다. 정책 엔진은 결정하고, 호스트는 집행하는 구조죠.
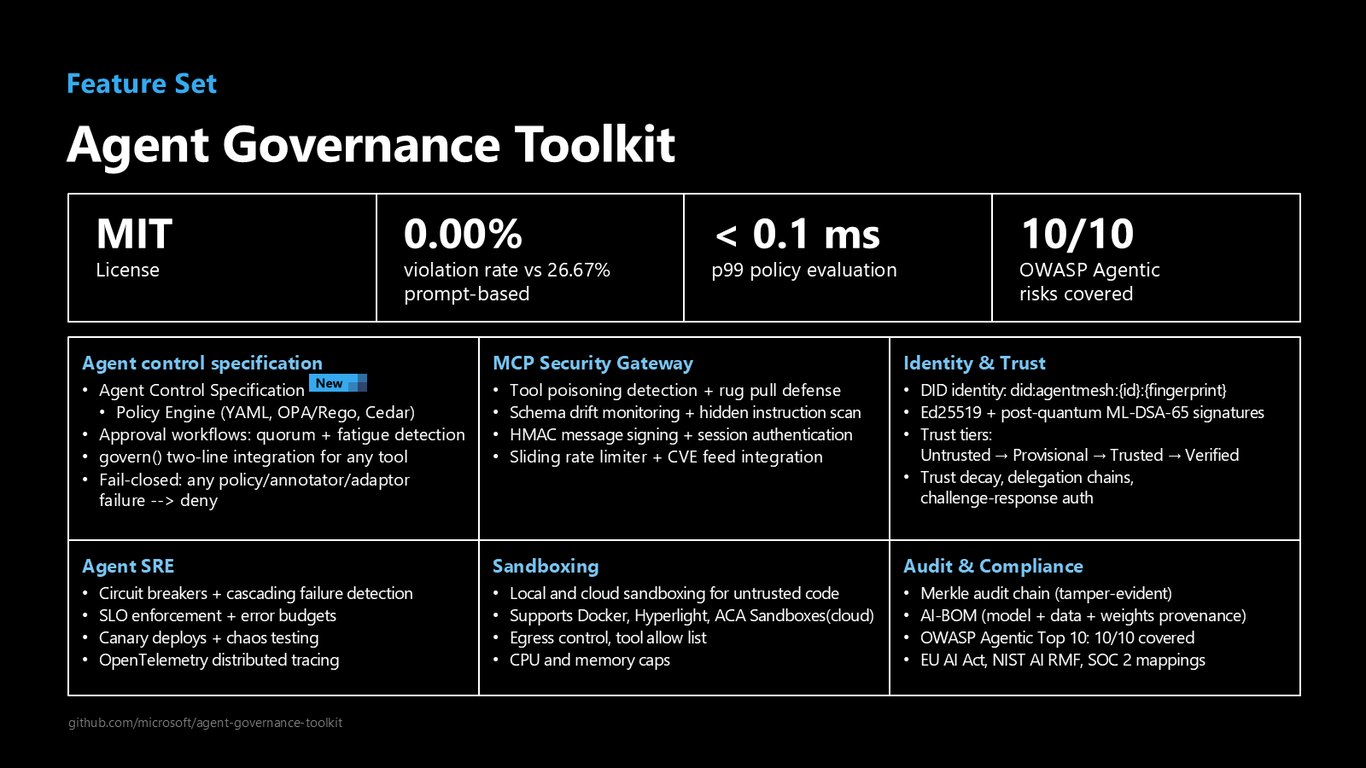
Agent Governance Toolkit
이 모든 걸 담은 것이 Agent Governance Toolkit입니다. 프롬프트 기반 26.67%에 비해 위반율 0%, p99 정책 평가 0.1밀리초 미만, OWASP 에이전트 위험 10개 전부 커버하고, MCP 보안 게이트웨이와 DID 기반 신원·신뢰 체계까지 MIT 라이선스로 제공합니다.
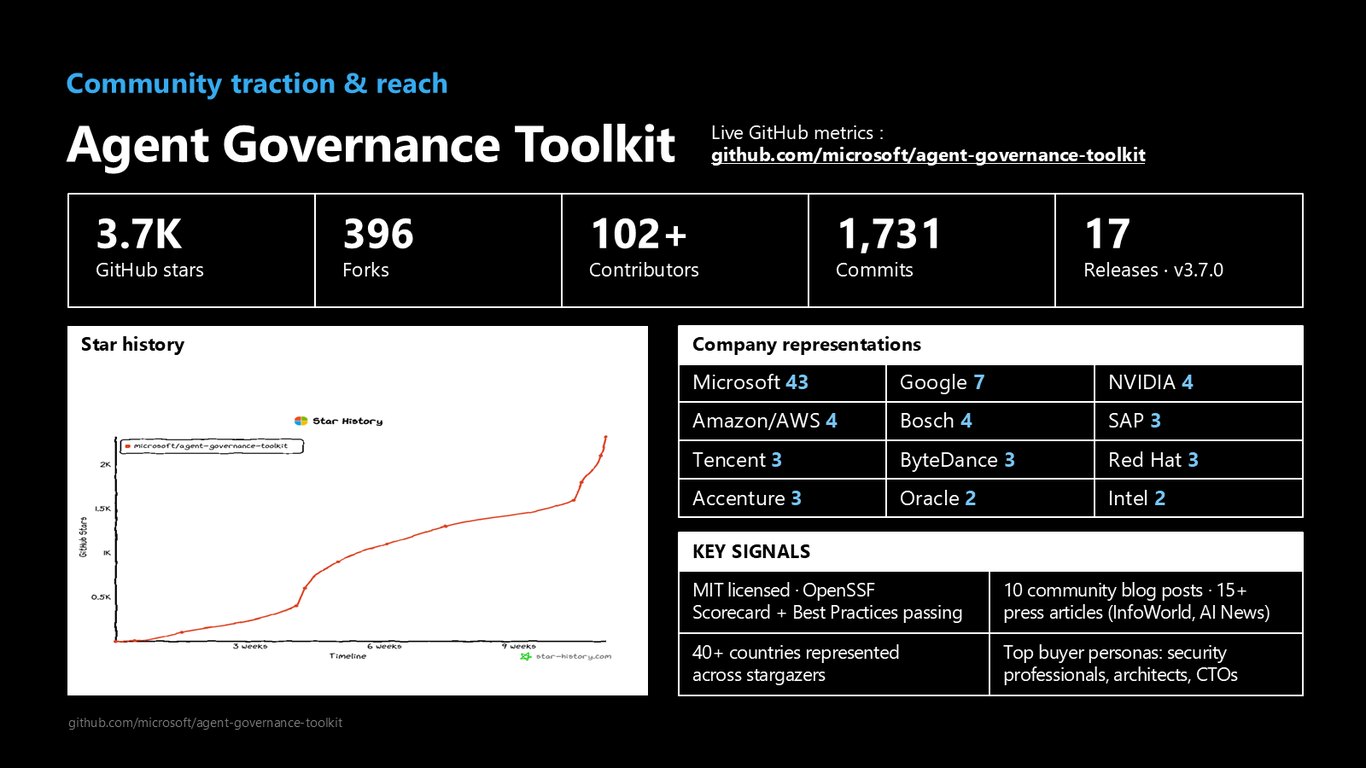
커뮤니티 확산과 반응
반응도 뜨겁습니다. GitHub 스타 3.7천 개, 포크 396개, 기여자 102명 이상에 40개국 넘는 스타거저가 모였고, Microsoft뿐 아니라 Google, NVIDIA, AWS, SAP 같은 기업의 기여가 이어지고 있습니다. 보안 전문가와 아키텍트, CTO들이 주요 관심층입니다.
ACS 파트너와 고객
ACS 역시 여러 고객과 파트너가 실제 환경에서 함께 검증하고 있습니다. 오픈 표준으로 만든 만큼 다양한 스택에서 빠르게 채택되고 있다는 점을 보여드립니다.
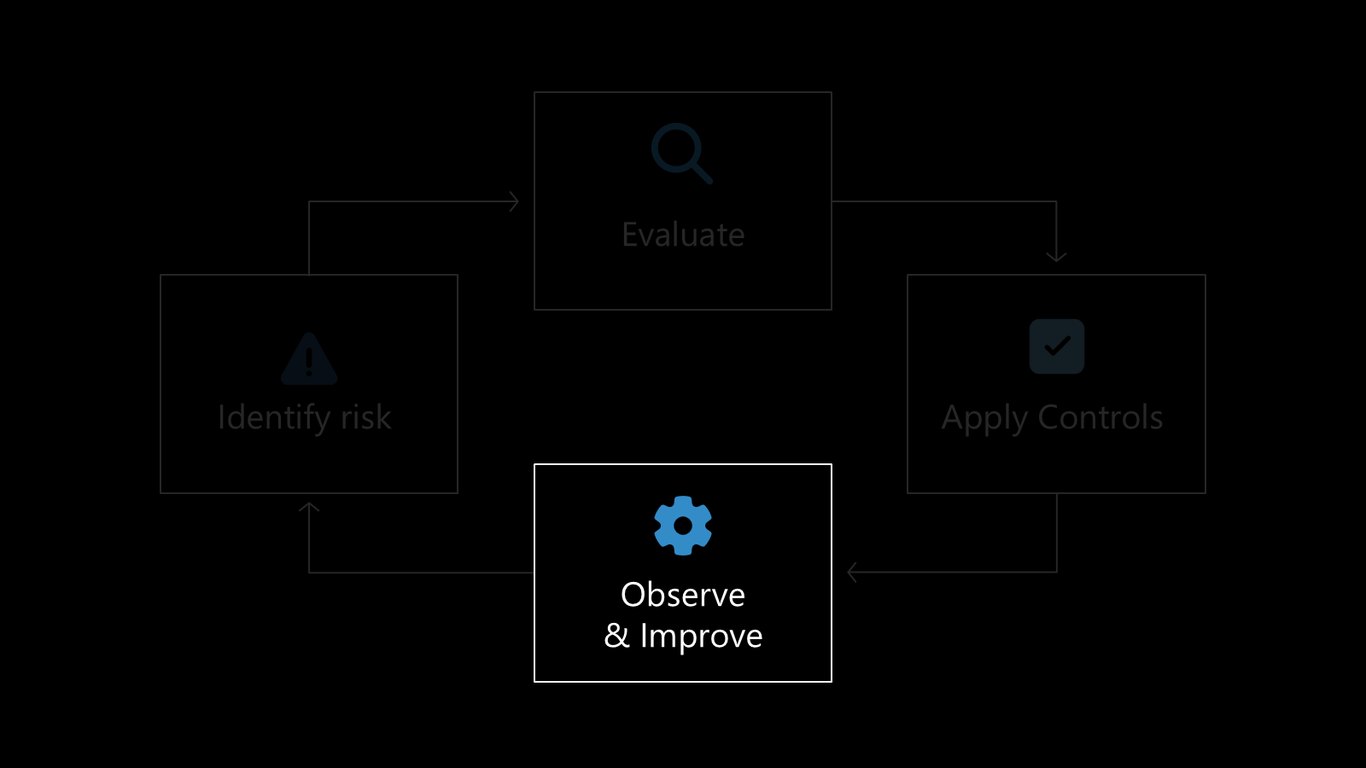
이제 마지막으로 관측하고 개선하는 단계를 살펴보겠습니다. 평가와 통제를 프로덕션까지 이어가는 방법이 핵심입니다.
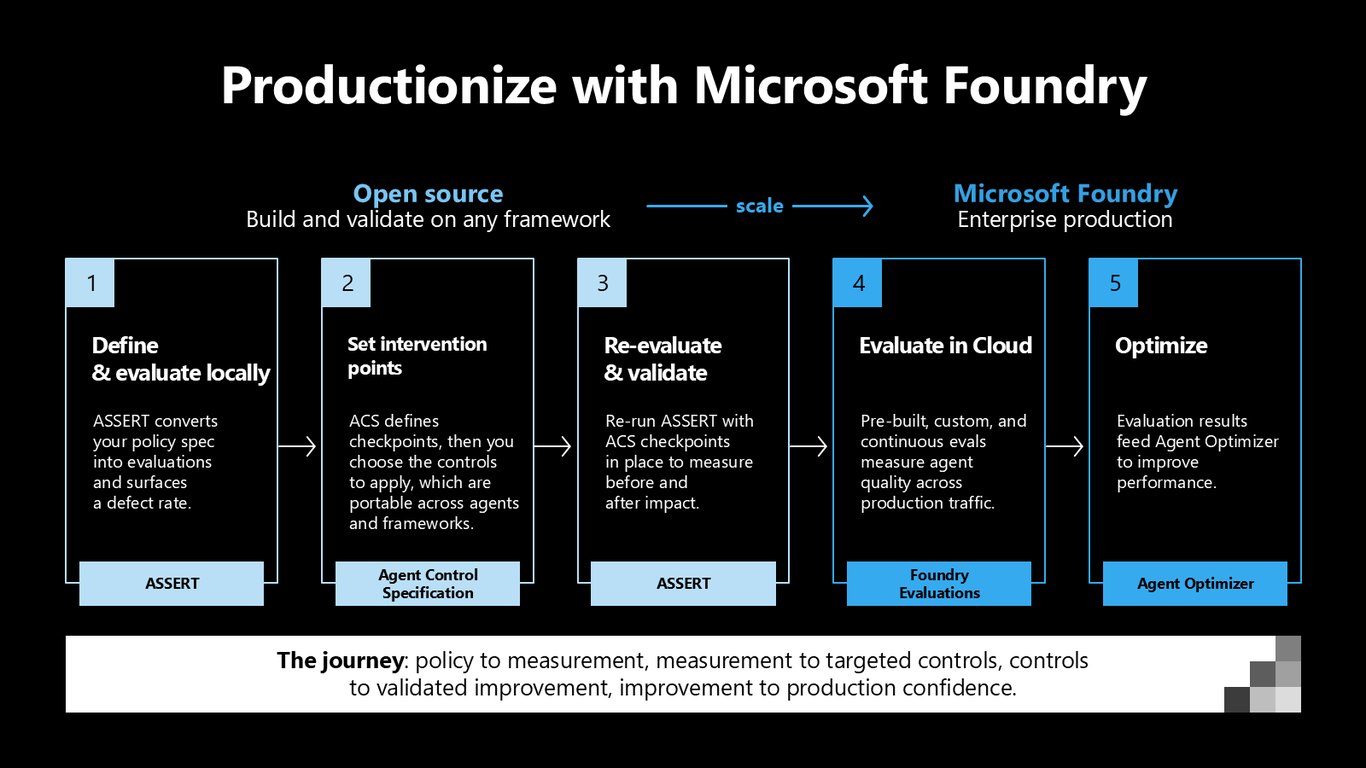
오픈소스로 어떤 프레임워크에서든 만들고 검증한 다음, Microsoft Foundry로 프로덕션화합니다. ASSERT로 로컬에서 정의·평가하고, ACS로 개입 지점을 정하고, 통제를 넣은 뒤 다시 평가해 전후 효과를 재고, Foundry Evaluations로 프로덕션 트래픽까지 측정한 다음 Agent Optimizer로 개선하는 여정입니다.
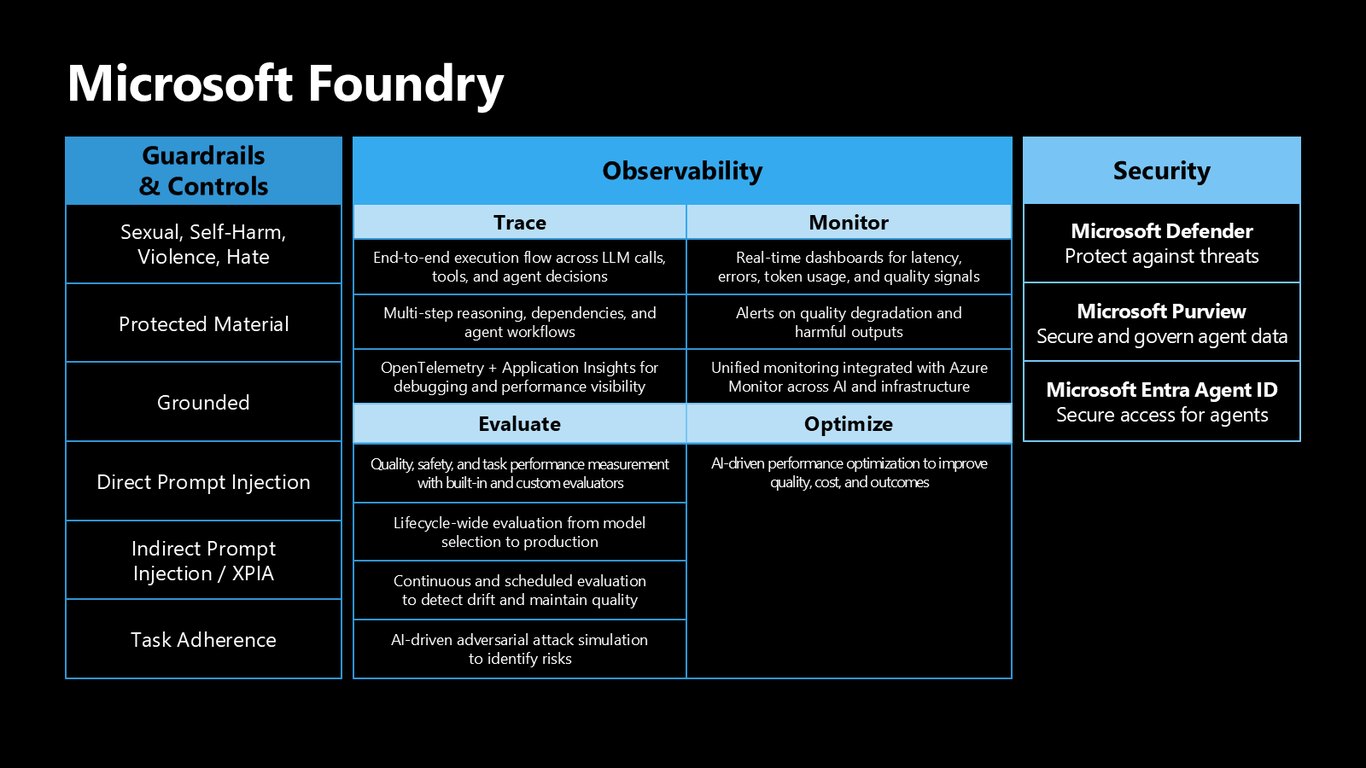
Foundry의 가드레일과 관측성
Microsoft Foundry는 성적·자해·폭력·혐오 같은 콘텐츠 필터부터 직간접 프롬프트 인젝션, task adherence까지 가드레일을 제공합니다. 여기에 OpenTelemetry와 Application Insights 기반 trace, 내장·커스텀 평가, 실시간 모니터링을 더해 라이프사이클 전반을 관측할 수 있습니다.
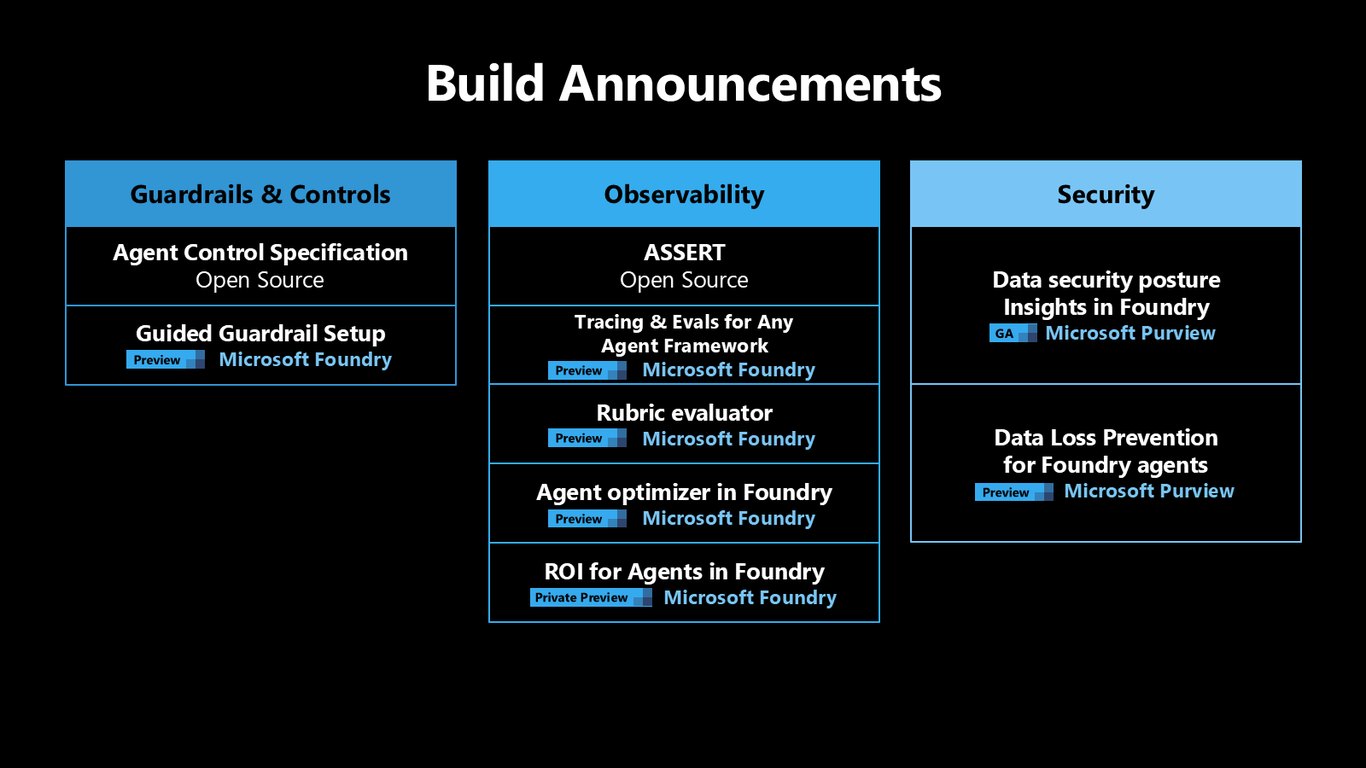
Build에서의 발표 내용
이번 Build에서 발표하는 것들을 정리하면, 오픈소스 ACS와 ASSERT, Foundry의 가이드형 가드레일 설정과 tracing·평가, rubric evaluator와 Agent Optimizer, ROI 측정, 그리고 Microsoft Purview 기반 데이터 보안 인사이트와 DLP까지 아우릅니다.

Responsible AI, 더 알아보기
여기서 멈추지 않습니다. Responsible AI 영역에는 더 깊이 파고들 주제들이 많은데, 이어서 그 최전선의 작업 몇 가지를 보여드리겠습니다.
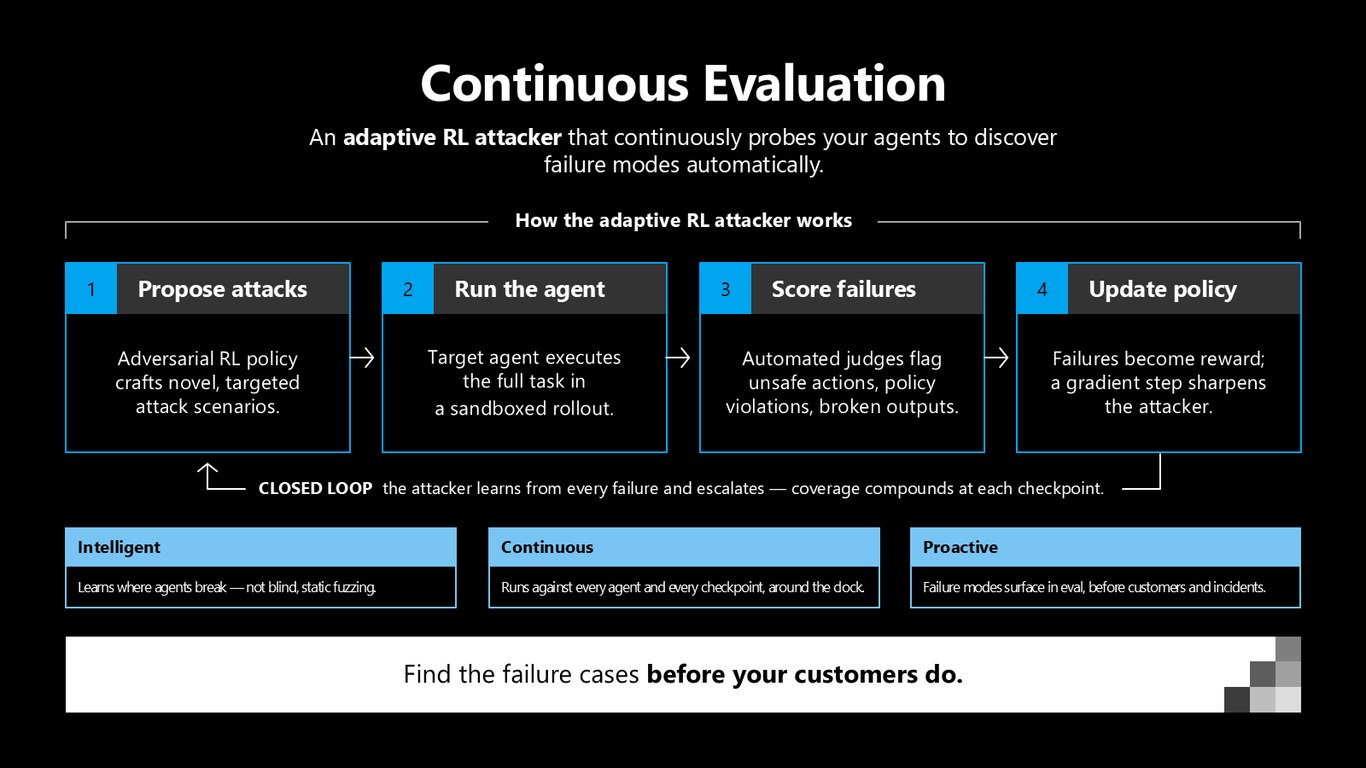
지속 평가: 적응형 RL 공격자
먼저 지속 평가입니다. 적응형 RL 공격자가 여러분의 에이전트를 끊임없이 탐침하며 실패 모드를 자동으로 찾아냅니다. 공격을 제안하고, 샌드박스에서 실행하고, 실패를 채점해 보상으로 삼아 공격자를 날카롭게 다듬는 닫힌 루프죠. 고객보다 먼저 실패를 발견하는 겁니다.

지속 학습: 스스로 고치는 에이전트
거기서 한발 더 나아가, 공격자가 찾은 실패를 개선으로 곧장 연결합니다. jailbreak나 안전하지 않은 도구 호출, PII 유출 같은 신호를 받아 GEPA·DSPy 같은 옵티마이저로 프롬프트를 자동으로 다시 쓰고, 필요하면 도구와 스캐폴딩을, 정말 드물게는 모델 가중치까지 조정합니다. 실패를 찾는 데서 끝내지 않고 자동으로 고치는 거죠.

콘텐츠 출처와 딥페이크 대응
생성한 이미지에는 눈에 보이지 않는 워터마크와 Content Credentials를 심습니다. 어떤 앱과 모델로 만들었는지, 발급 주체는 누구인지를 신원 인증서로 서명해 붙이기 때문에, AI 생성 콘텐츠의 출처를 검증하고 딥페이크에 대응할 수 있습니다.
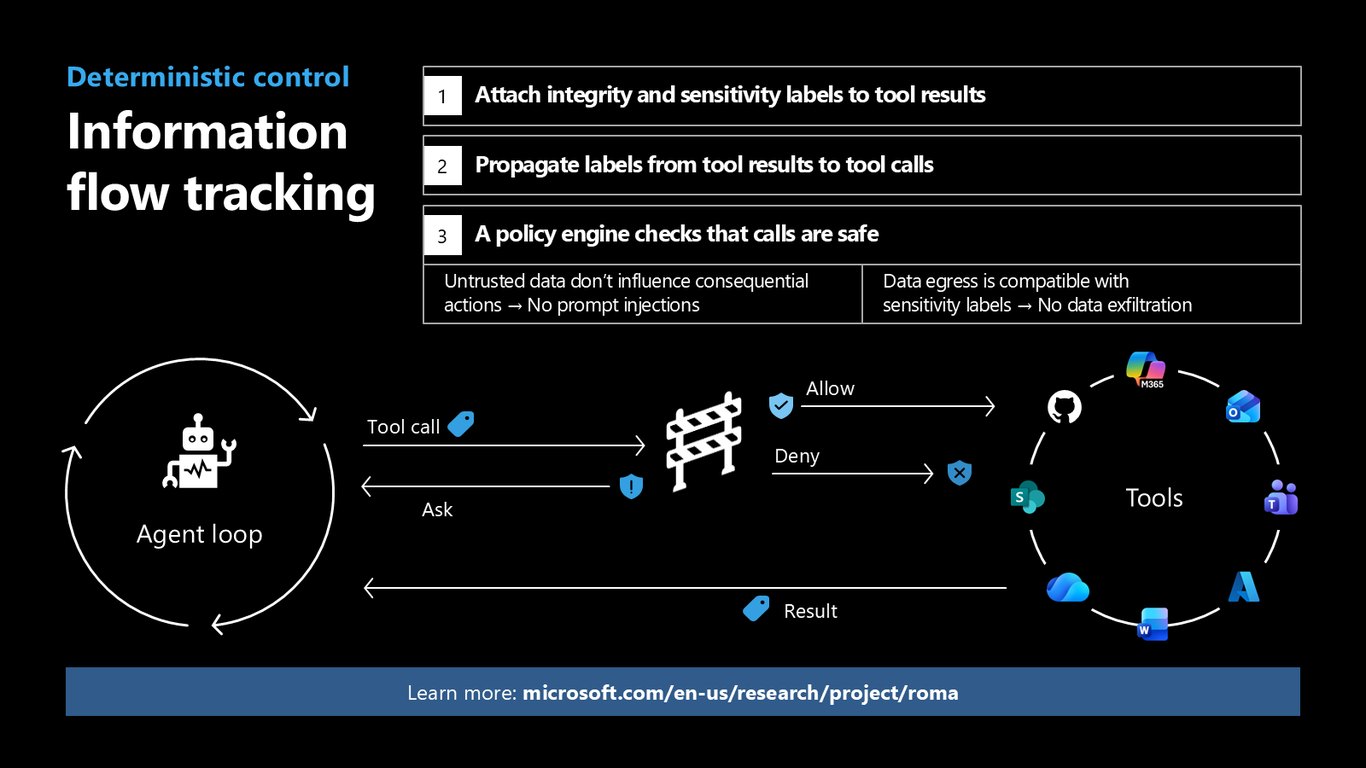
정보 흐름 추적과 결정적 통제
Project ROMA에서는 정보 흐름을 추적합니다. 도구 결과에 무결성·민감도 라벨을 붙이고 이를 도구 호출로 전파한 뒤, 정책 엔진이 안전 여부를 판정하죠. 신뢰할 수 없는 데이터가 중요한 행동에 영향을 주지 못하게 막아 프롬프트 인젝션과 데이터 유출을 원천 차단합니다.

이제 다음 단계는 멀티 에이전트입니다. 단일 에이전트는 이미 배포할 만큼 풀렸고, 진짜 어려운 문제는 에이전트들이 상호작용할 때 나타납니다. 협업과 평가, 레드팀을 여기로 옮기고 있고, SocialReasoning-Bench와 100개 이상 에이전트 레드팀 같은 작업이 이미 진행 중입니다.
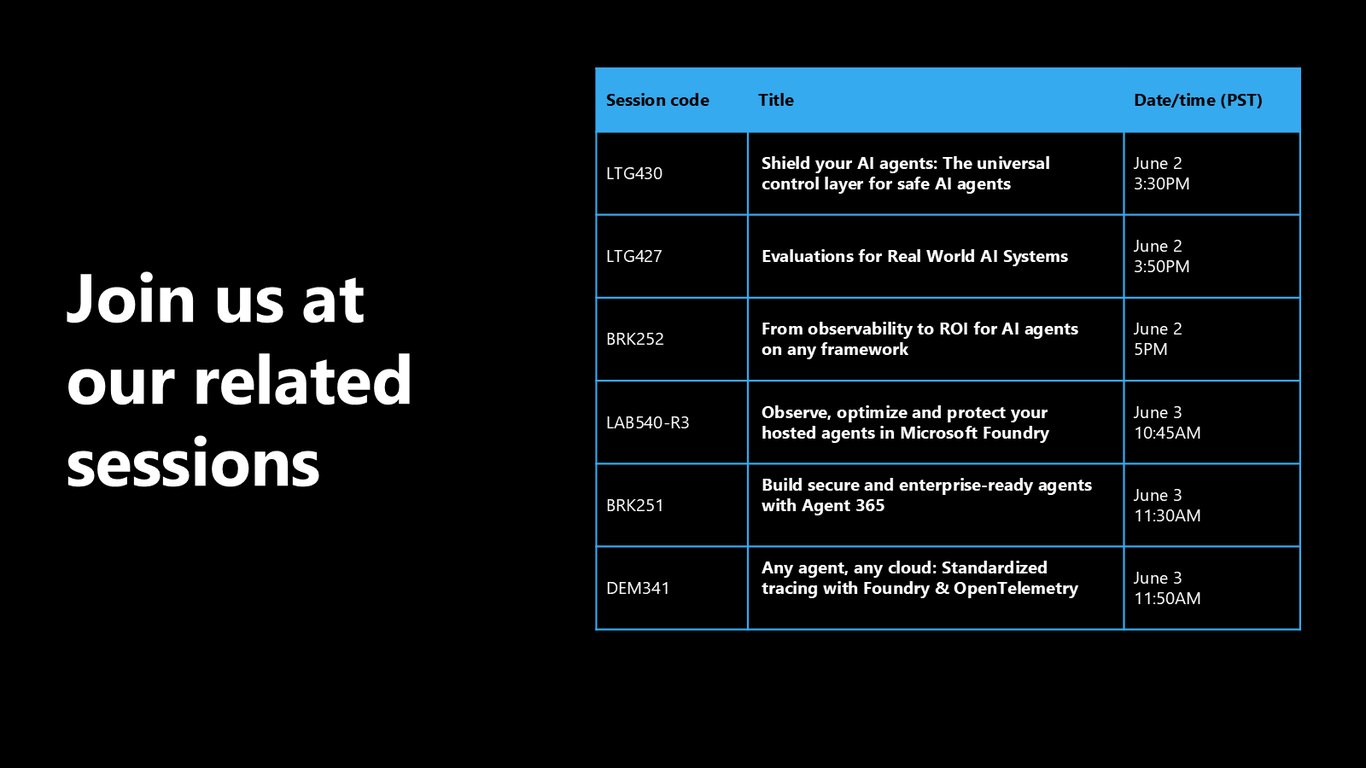
관련 세션 안내
관심이 있으시다면 관련 세션도 함께 들어보시길 권합니다. LTG430, LTG427, BRK252, BRK251, 그리고 랩과 데모 세션까지 안전한 에이전트를 만드는 여러 주제를 이어서 다룹니다.

오픈소스 커뮤니티에 참여하세요
ASSERT와 Agent Governance Toolkit은 모두 오픈소스입니다. github.com/responsibleai/ASSERT와 github.com/microsoft/agent-governance-toolkit에서 안전과 보안, 과학의 미래를 함께 만들어 주시길 바랍니다.

결국 인간의 잠재력을 여는 일은 신뢰에서 시작됩니다. 오늘 보여드린 관측과 통제는 바로 그 신뢰를 만들기 위한 것입니다. 감사합니다.

자료와 설문 안내
세션 상세 페이지에서 튜토리얼과 리소스, 코드를 바로 확인하실 수 있습니다. aka.ms/build/evals를 방문하거나 QR 코드를 스캔해 설문에도 참여해 주세요.