
오늘은 Kubernetes 위에서 Agentic AI를 실제로 운영하는 이야기를, 마케팅 톤이 아니라 실무자의 솔직한 시선으로 풀어 보겠습니다. 저는 Cloud Native Ecosystem을 담당하는 Lachie Evenson입니다.

오늘의 아젠다
크게 세 가지를 다뤄 보겠습니다. 먼저 왜 대규모 AI가 Kubernetes 위에서 더 잘 돌아가는지, 다음으로 실제로 무엇이 필요한지, 마지막으로 그게 현장에서 어떤 모습인지까지 순서대로 보겠습니다.

이제 첫 번째 질문, 왜 규모가 커질수록 AI가 Kubernetes 위에서 더 잘 돌아가는지부터 살펴보겠습니다.

관리형 AI vs 조립 가능한 기반
선택지는 크게 둘입니다. Microsoft Foundry 같은 관리형 플랫폼은 배포까지 가장 빠른 길이고, AKS와 Kubernetes는 스택 깊숙이 들어가 직접 튜닝하는 길이죠. 극한의 규모와 비용, 주권이 걸리면 조립 가능한 쪽이 답이 됩니다.
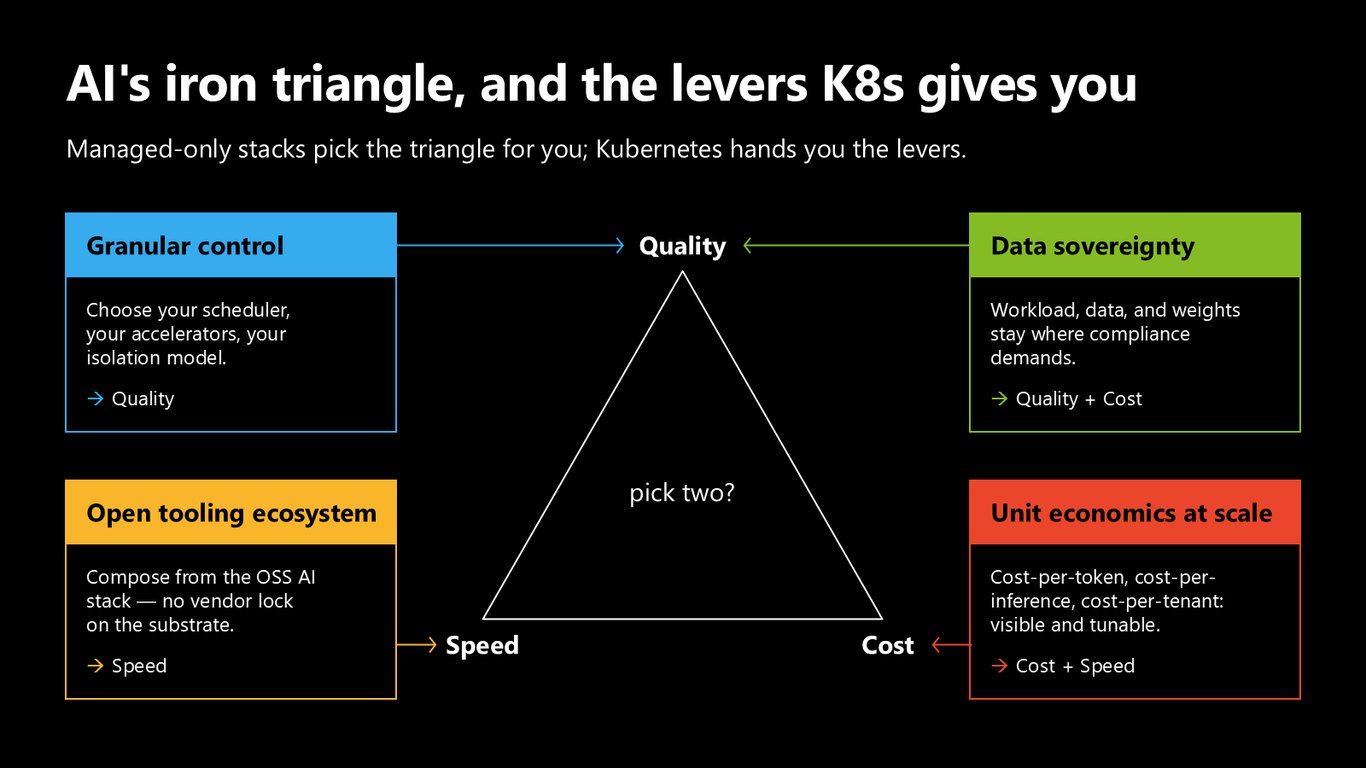
AI의 철의 삼각형, K8s가 쥐여주는 레버
속도, 품질, 비용 — 흔히 셋 중 둘만 고르라고 하죠. 관리형 스택은 이 삼각형을 대신 정해 버리지만, Kubernetes는 스케줄러와 가속기, 격리 모델을 직접 고를 수 있는 레버를 여러분 손에 쥐여줍니다.

조립 가능성이 선택이 아닌 순간
규모나 비용, 민감도가 관리형만으로 감당이 안 되는 팀, 여러 클라우드와 온프레미스에 걸쳐 배포하는 ISV라면 조립 가능성은 옵션이 아닙니다. 선언적 자원 관리, 이기종 스케줄링, 네임스페이스 격리 같은 기본기가 바로 그 일을 해냅니다.

같은 기반, 완전히 다른 세 워크로드
같은 GPU를 쓰더라도 학습은 처리량, 추론은 지연시간, 에이전트 시스템은 상태와 조율에 묶여 있습니다. GPU는 공유해도 운영 전제는 전혀 공유하지 않는다는 점, 이게 핵심입니다.

K8s는 토대, AI 시대는 그 위를 요구한다
Kubernetes는 파드를 하나씩 스케줄하지만, AI 워크로드는 수십, 수백 개 파드가 한꺼번에 떠야 하죠. GPU 토폴로지 인식, 토큰과 큐 깊이 기반 스케일링, 그리고 학습과 멀티턴 세션을 견디는 지속 상태 — 이 위에 무엇을 얹느냐가 오늘의 나머지 이야기입니다.

이제 두 번째 파트, Kubernetes 위에서 AI를 돌리는 데 실제로 무엇이 필요한지 하나씩 짚어 보겠습니다.

AI를 위해 설계된 기반 위에 스택을 조립하다
그림으로 보면 이렇습니다. 맨 아래 Kubernetes와 AKS 기반 위에 KAITO와 AI Runway로 추론을 얹고, Ray와 Anyscale on Azure로 학습을 올리고, 그 위에 Skills와 MCP 같은 에이전트 오케스트레이션을 조립하는 구조입니다.

추론과 서빙 계층부터
그럼 이 스택을 아래에서부터 차근차근 쌓아 올려 보죠. 가장 먼저 추론과 서빙 계층부터 시작하겠습니다.

AI Runway와 KAITO, 모델 서빙의 두 축
AI Runway는 YAML 없이 웹 UI로 HuggingFace 카탈로그를 훑고 GPU 적합성을 확인해 원클릭으로 배포하는 플랫폼입니다. 그 아래 KAITO는 Workspace CRD로 GPU 타입과 모델 ID만 주면 엔드포인트를 만들어 주는 오퍼레이터죠. AI Runway가 플랫폼, KAITO는 그 프로바이더 중 하나입니다.

모델 탐색에서 프로덕션 서빙까지
흐름은 세 단계입니다. AI Runway UI에서 모델을 골라 배포하면 ModelDeployment가 생기고, KAITO Workspace가 GPU를 산정해 Karpenter로 노드를 띄우고 vLLM을 시작하죠. 그다음엔 KEDA 오토스케일과 Gateway API로 확장하고, 표준 롤아웃으로 카나리와 롤백까지 갑니다.

AI Runway 데모 영상
말로만 하면 감이 잘 안 오시죠. 실제 AI Runway 화면을 영상으로 함께 보겠습니다. 모델 카탈로그부터 GPU 적합성 확인, 배포와 오토스케일링까지 한 번에 흐르는 모습을 눈으로 확인해 보시죠.

다시 스택으로 — 이번엔 학습 계층
서빙을 봤으니 한 층 위로 올라가 보겠습니다. 이번엔 학습과 파인튜닝 계층을 어떻게 조립하는지 살펴보죠.

AKS는 클러스터를, Ray는 워크로드를
AKS는 파드를 스케줄하고 노드 수명주기와 네트워킹, 스토리지를 책임지는 프로덕션급 기반을 줍니다. 하지만 프로덕션 AI엔 CPU와 GPU를 아우르는 분산 컴퓨팅, 멀티노드 학습, 그리고 데이터 준비부터 서빙까지 하나의 Python API가 더 필요하죠. 그걸 Ray가 채웁니다.

Anyscale on Azure, 이제 퍼블릭 프리뷰
그 Ray를 관리형으로 제공하는 게 Anyscale on Azure입니다. Anyscale Runtime이 여러분의 AKS 환경 안에서 돌고, Azure 컨트롤 플레인과 통합되며, 여러분 구독 안에서 실행되고 Azure 계약으로 청구됩니다. 오늘부터 Azure에서 바로 쓰실 수 있습니다.
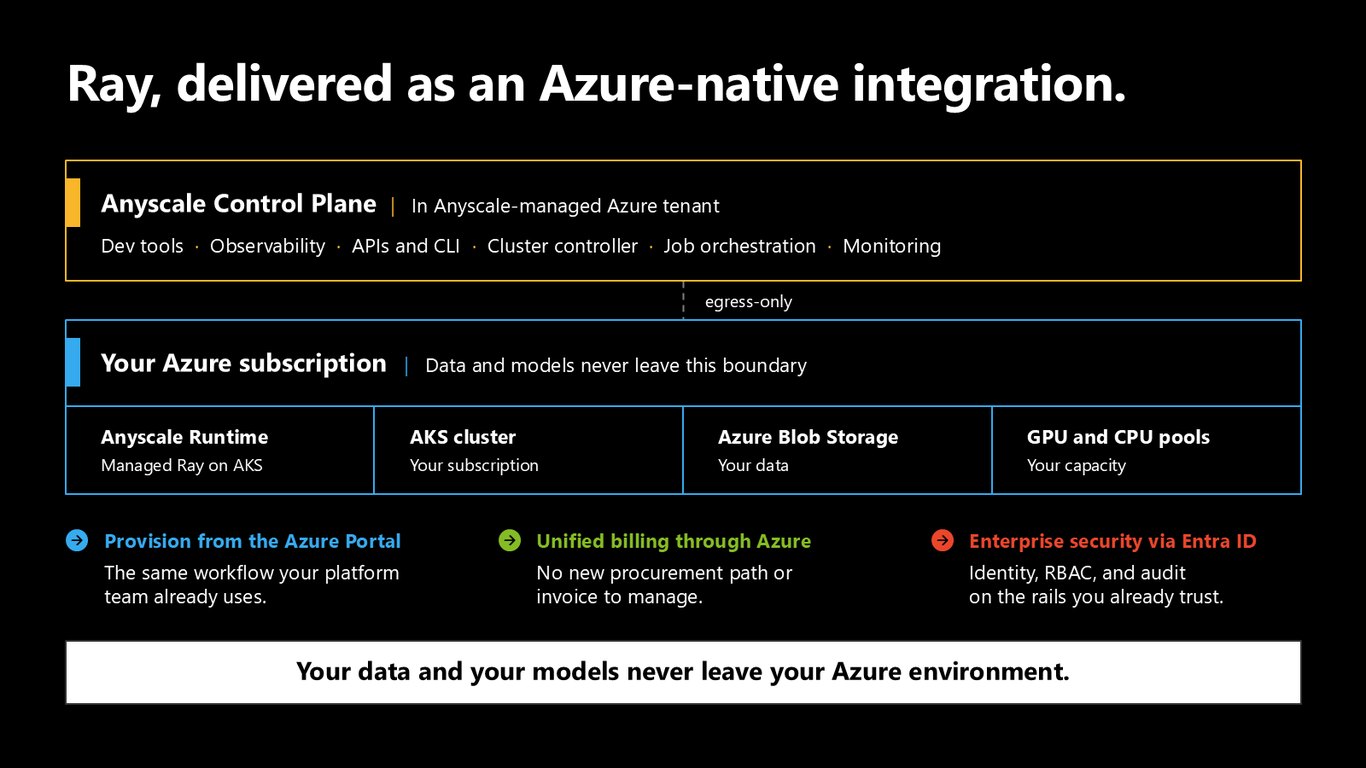
데이터와 모델은 Azure를 떠나지 않는다
구조를 보면 Anyscale Control Plane은 Anyscale이 관리하는 Azure 테넌트에 있고, 여러분 환경과는 egress 방향으로만 연결됩니다. 즉 여러분의 데이터와 모델은 절대 Azure 환경 밖으로 나가지 않습니다.
데모 (1)
이 학습 계층이 실제로 어떻게 동작하는지, 첫 번째 데모로 직접 보여 드리겠습니다.

이제 남은 질문 — 에이전트는 이걸 어떻게 쓰나
기반과 서빙, 학습 계층까지 자리를 잡았으니 마지막 질문이 남습니다. 이 모든 걸 에이전트가 어떻게 소비하느냐죠. 이제 에이전트 오케스트레이션 계층으로 넘어가 보겠습니다.
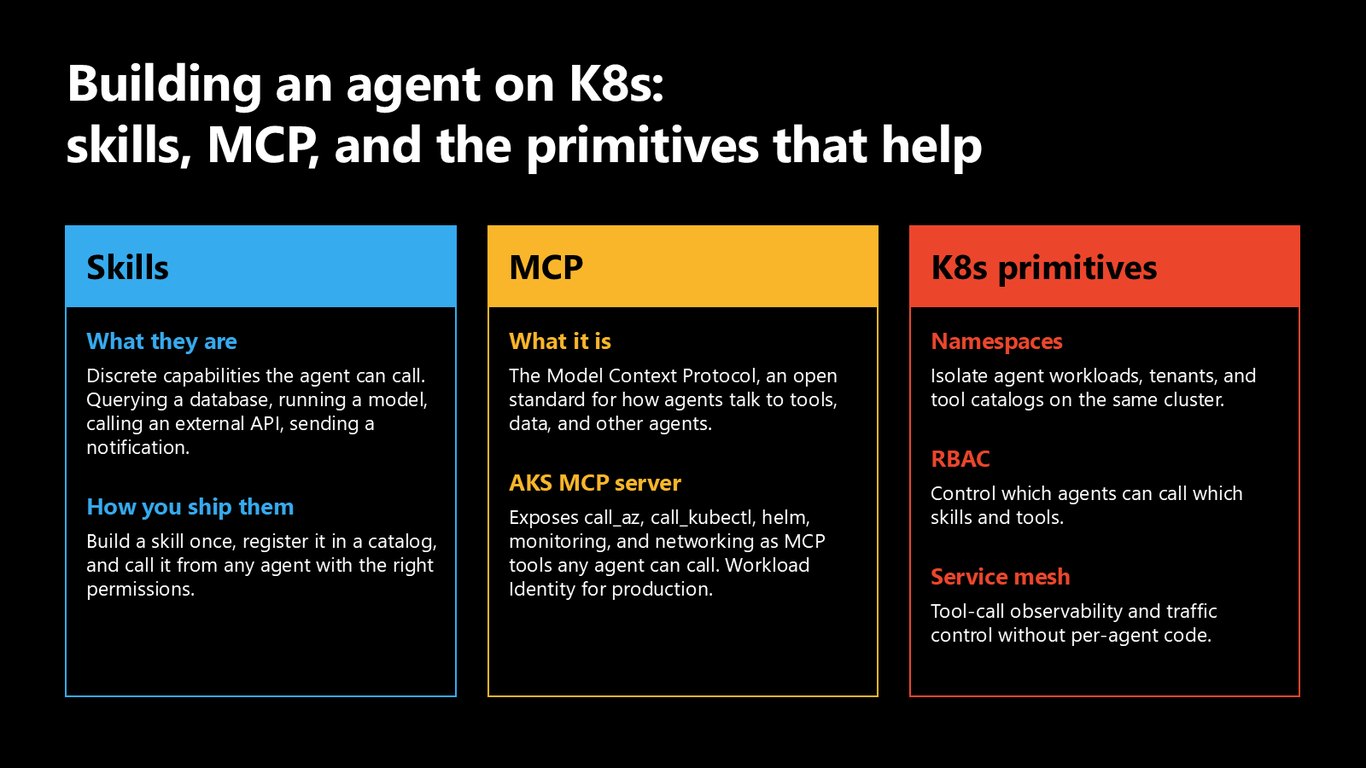
Skills, MCP, 그리고 K8s 프리미티브
에이전트는 Skills로 개별 기능을 호출합니다. 한 번 만들어 카탈로그에 등록하면 권한만 맞으면 어느 에이전트든 부를 수 있죠. MCP는 도구와 데이터를 잇는 개방 표준이고, AKS MCP Server는 kubectl과 helm 같은 걸 MCP 도구로 노출합니다. 여기에 Namespace, RBAC, 서비스 메시가 격리와 관측성을 받쳐 줍니다.
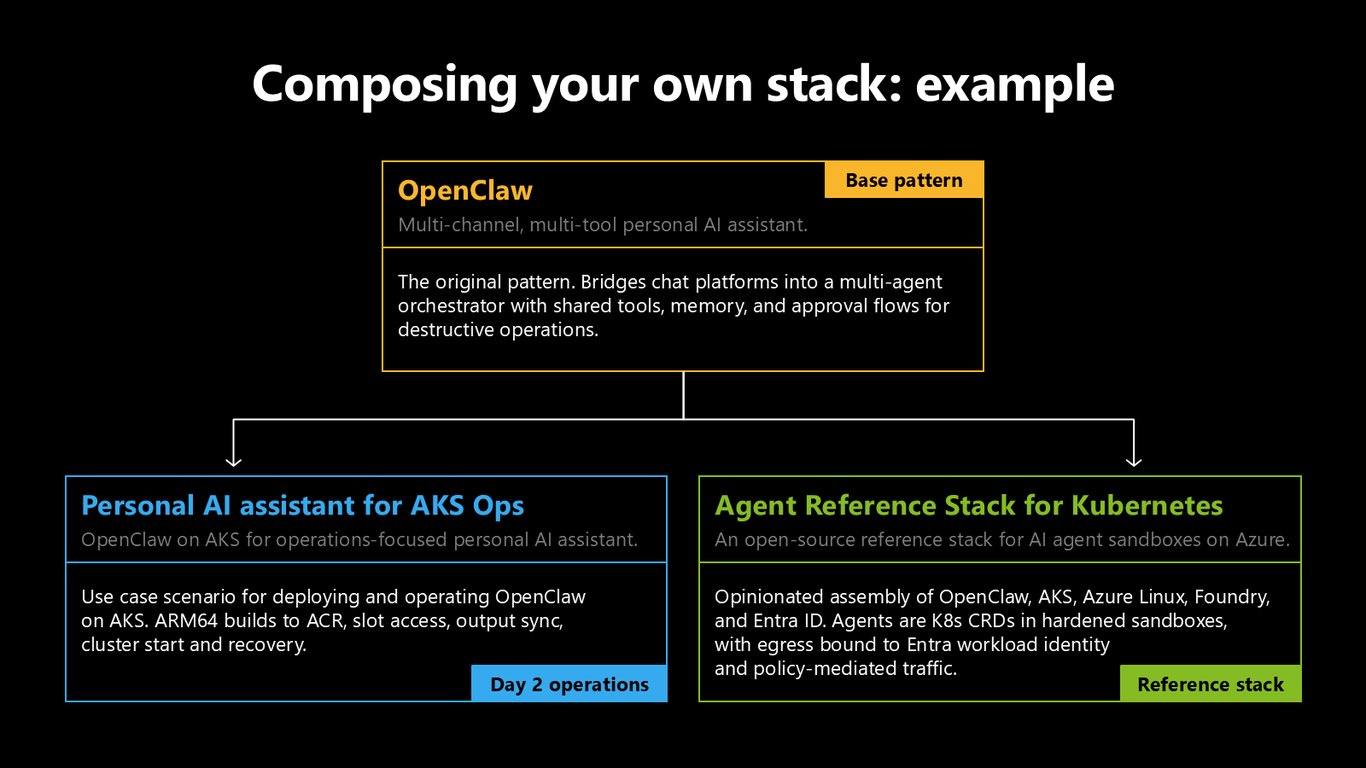
직접 조립하는 스택, 실제 예시
예를 들어 AKS 운영을 위한 개인 AI 비서를 OpenClaw로 AKS 위에 올릴 수 있습니다. 채팅 플랫폼을 멀티 에이전트 오케스트레이터로 이어 주는 기본 패턴 위에, OpenClaw와 Foundry, Entra ID를 조합한 Agent Reference Stack까지 — 에이전트를 강화된 샌드박스 안 K8s CRD로 다루는 구조입니다.
데모 (2) — Agent Reference Stack
이 Agent Reference Stack이 실제로 어떻게 굴러가는지, 두 번째 데모로 보여 드리겠습니다.

에이전트 계층이 곧 새로운 컨트롤 플레인
정리하면 이제 에이전트 계층이 AI 앱의 새로운 컨트롤 플레인이고, 실무자들은 바로 그걸 Kubernetes 위에서 만들고 있습니다. 지속 볼륨으로 세션 상태를 견디게 하고, CRD와 오퍼레이터로 멀티스텝 조율을, 서비스 메시로 도구 호출 관측성을 확보하죠. 어느 계층에도 벤더 종속이 없습니다.

이 모든 걸 떠받치는 프로덕션급 AKS
그렇다면 이 전체 스택을 프로덕션급으로 떠받치는 AKS 기반은 무엇이 다를까요? 이제 그 토대 이야기를 해 보겠습니다.

단일 클러스터에서 플릿까지
AKS는 단일 클러스터에서 멀티 클러스터, 그리고 클라우드와 온프레미스, 엣지를 아우르는 플릿까지 함께 확장됩니다. 오늘 이와 관련해 네 가지를 발표합니다 — AKS Automatic 관리형 시스템 노드풀, Azure Container Linux, 베어메탈 AKS, 그리고 Arc 클러스터용 Fleet Manager입니다.

AKS Automatic 관리형 시스템 노드풀
이제 CoreDNS나 kube-proxy 같은 클러스터 핵심 컴포넌트가 도는 시스템 노드풀을 저희가 직접 호스팅하고 관리합니다. 더 이상 시스템 풀 사이징이나 컨트롤 플레인 여유분 걱정을 안 하셔도 되죠. 덕분에 GPU 노드는 한 바이트까지 워크로드에 온전히 씁니다. 정식 출시됐습니다.

Azure Container Linux, 보이지 않는 OS 계층
OS 계층은 눈에 안 띄어야 합니다. Azure Container Linux는 패키지 풋프린트를 줄여 공격 표면과 CVE를 줄이고, 서명된 아티팩트와 예측 가능한 업그레이드 경로로 공급망을 투명하게 만듭니다. 호스트든 컨테이너든 같은 강화된 베이스를 씁니다. 정식 출시됐습니다.

베어메탈 위의 AKS
AKS 노드를 하이퍼바이저 없이 물리 하드웨어 위에 바로 올릴 수 있습니다. 워크로드와 GPU 사이 가상화 계층이 사라지죠. 컨트롤 플레인도 kubectl도 그대로인데, NVLink와 RDMA에 직접 접근하면서 가상화 세금은 사라집니다. 학습과 지연 민감 추론에 최고의 GPU 성능을 냅니다. 퍼블릭 프리뷰입니다.

Arc 클러스터용 Fleet Manager
클라우드와 온프레미스, 엣지의 AI 클러스터를 하나의 컨트롤 플레인으로 다룹니다. 헬스 게이트를 낀 점진적 롤아웃, 적절한 GPU SKU와 근접성을 고려한 지능형 배치, 그리고 플릿 전체에 일관된 RBAC과 정책 적용까지 — Arc로 온프레미스와 엣지 클러스터까지 닿습니다. 정식 출시됐습니다.

다시, 기반 위에 조립하는 AI 스택
정리하면 이렇습니다. 단일 클러스터에서 플릿까지 이어지는 AKS 기반 위에, KAITO와 AI Runway로 서빙을, Ray와 Anyscale로 학습을, MCP와 Skills, OpenClaw 스타일 스택으로 에이전트 계층을 조립하는 것 — 이게 오늘 말씀드린 전체 그림입니다.
이제 마지막 파트입니다. 지금까지의 이야기가 실제 현장에서 어떤 모습으로 나타나는지, 고객 사례로 보여 드리겠습니다.
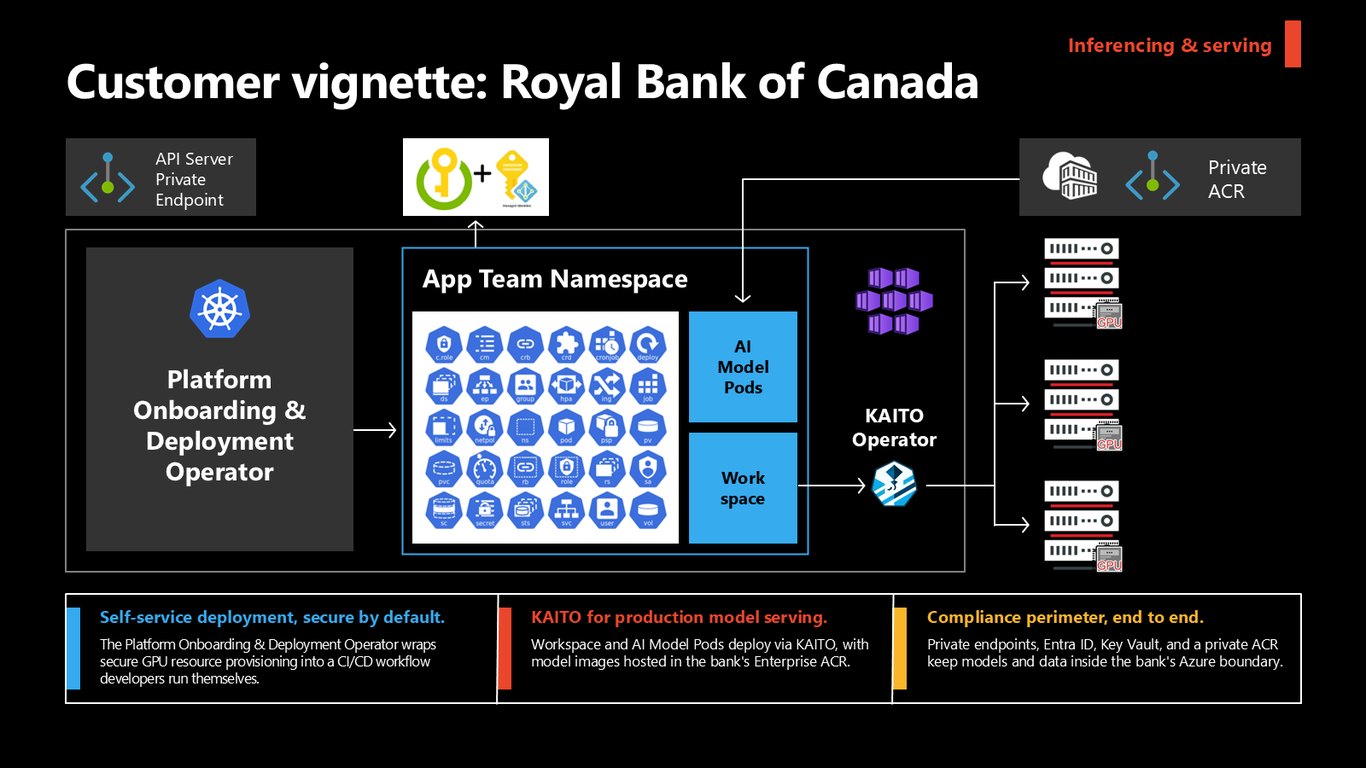
고객 사례 — Royal Bank of Canada
RBC는 안전을 기본값으로 두고 셀프서비스 배포를 구현했습니다. Platform Onboarding & Deployment Operator가 안전한 GPU 프로비저닝을 CI/CD로 감싸 개발자가 직접 돌리고, KAITO로 프로덕션 모델을 서빙하죠. Private Endpoint와 Entra ID, Key Vault, 프라이빗 ACR로 모델과 데이터를 은행의 Azure 경계 안에 묶어 둡니다.

Wayve, Azure 위에서 자율주행을 다시 쓰다
Wayve는 규칙 기반 대신 종단간 딥러닝으로 자율주행을 다시 썼습니다. AI Driver 학습엔 방대한 영상과 센서 데이터가 필요한데, AKS와 Anyscale on Azure가 수천 개 GPU를 하나의 유연한 슈퍼컴퓨터로 묶어 냈죠. 그 결과 새 Nissan 차량으로 단 넉 달 만에 도쿄에서 자율주행을 시연했습니다.

내부 사례 — 모든 AKS 엔지니어의 개인 AI 에이전트
내부에서도 쓰고 있습니다. 모든 AKS 엔지니어가 AKS 위에서 도는 개인 AI 에이전트를 활용하죠. 인시던트 트리아지와 자동 조사, 로그와 메트릭 쿼리 생성, 트러블슈팅 가이드 검색, 온콜 지식 이전까지 — 실제 운영 현장에서 매일 쓰이고 있습니다.
자, 그렇다면 이제 무엇을 하면 될까요? 오늘 이야기를 여러분의 다음 주로 가져갈 수 있게 정리해 드리겠습니다.
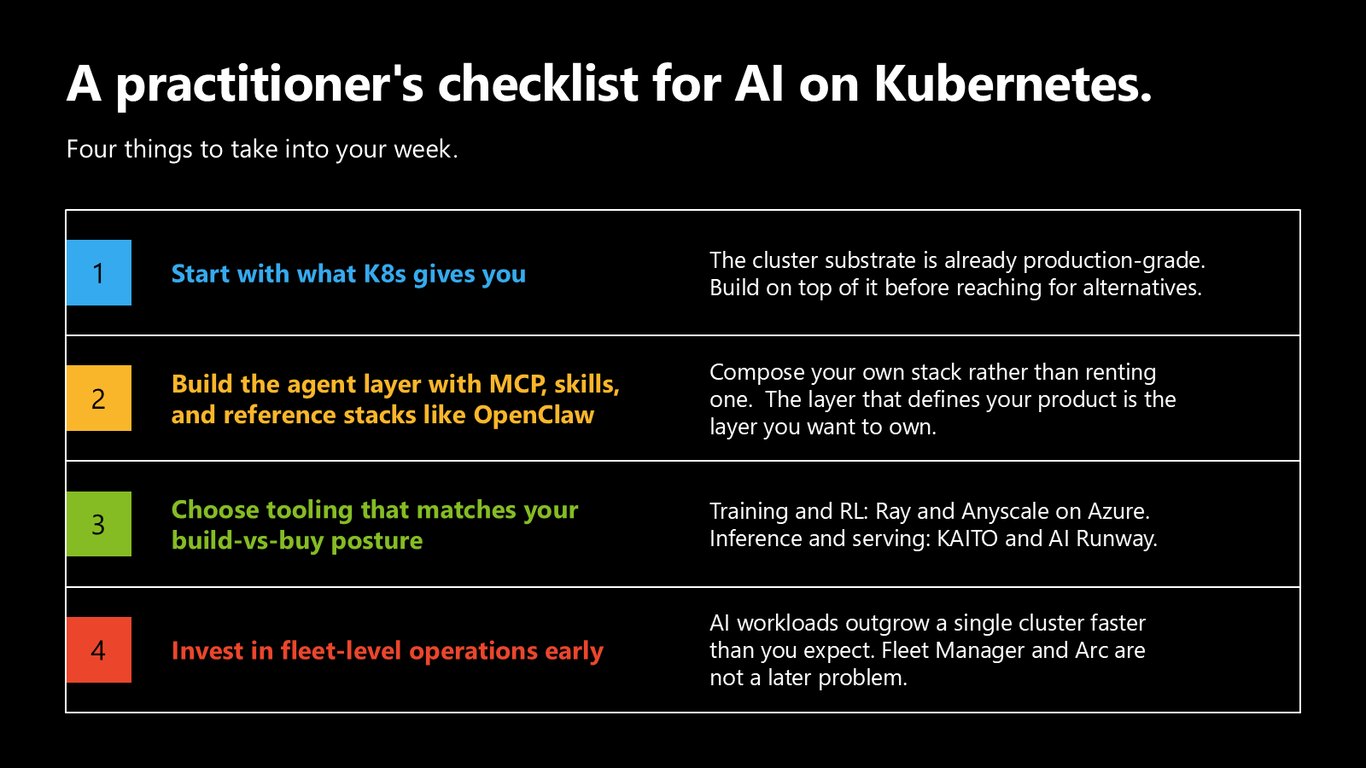
실무자를 위한 체크리스트 네 가지
네 가지만 챙기세요. 첫째, Kubernetes가 이미 주는 것에서 출발하세요 — 기반은 이미 프로덕션급입니다. 둘째, MCP와 Skills, OpenClaw 같은 레퍼런스로 에이전트 계층을 쌓으세요. 셋째, 빌드냐 바이냐에 맞는 도구를 고르세요. 넷째, 플릿 단위 운영을 일찍 준비하세요. 단일 클러스터는 생각보다 빨리 벗어납니다.

감사합니다
감사합니다. 세션 상세 페이지에서 튜토리얼과 리소스, 코드를 확인하실 수 있고, aka.ms/build/evals 또는 QR 코드로 설문에 참여해 주시면 큰 도움이 됩니다.