
오늘은 PepsiCo가 어떻게 에이전틱 AI를 실제 업무에 도입했는지, 그 청사진을 Microsoft의 Bob Ward, Rishabh Saha와 PepsiCo의 Krunal Patel이 함께 풀어 보겠습니다.

AI는 데이터만큼만 똑똑하다
AI는 결국 그 위에 놓인 데이터만큼만 똑똑합니다. 리더의 83%가 데이터 인프라만 탄탄하면 AI 도입이 더 빨라졌을 거라고 답했고, 앞서가는 기업의 69%는 이미 데이터 현대화를 마쳤습니다.
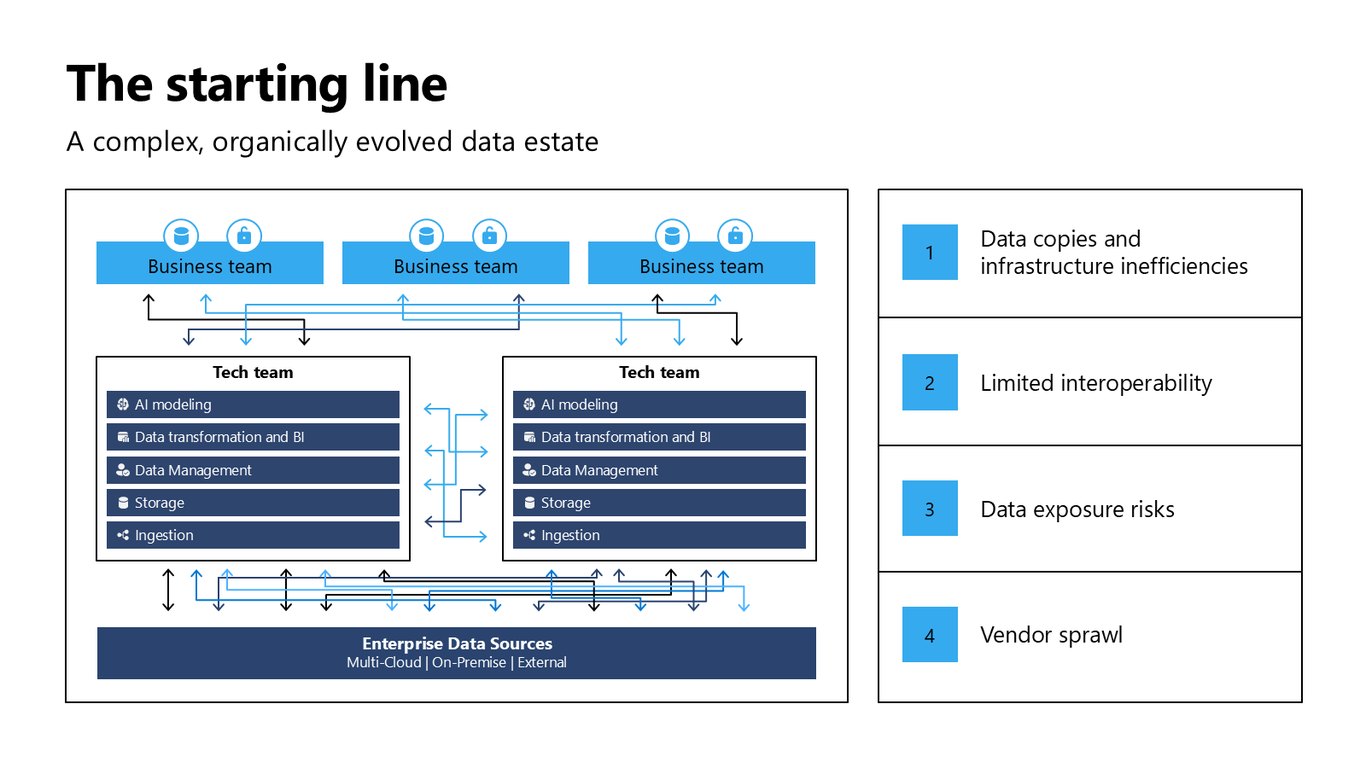
출발점: 복잡하게 얽힌 데이터 자산
많은 기업의 출발점은 이렇습니다. 여러 팀이 각자 도구를 쓰면서 데이터가 계속 복사되고, 멀티 클라우드와 온프레미스에 흩어져 유기적으로 뒤엉킨 상태죠.
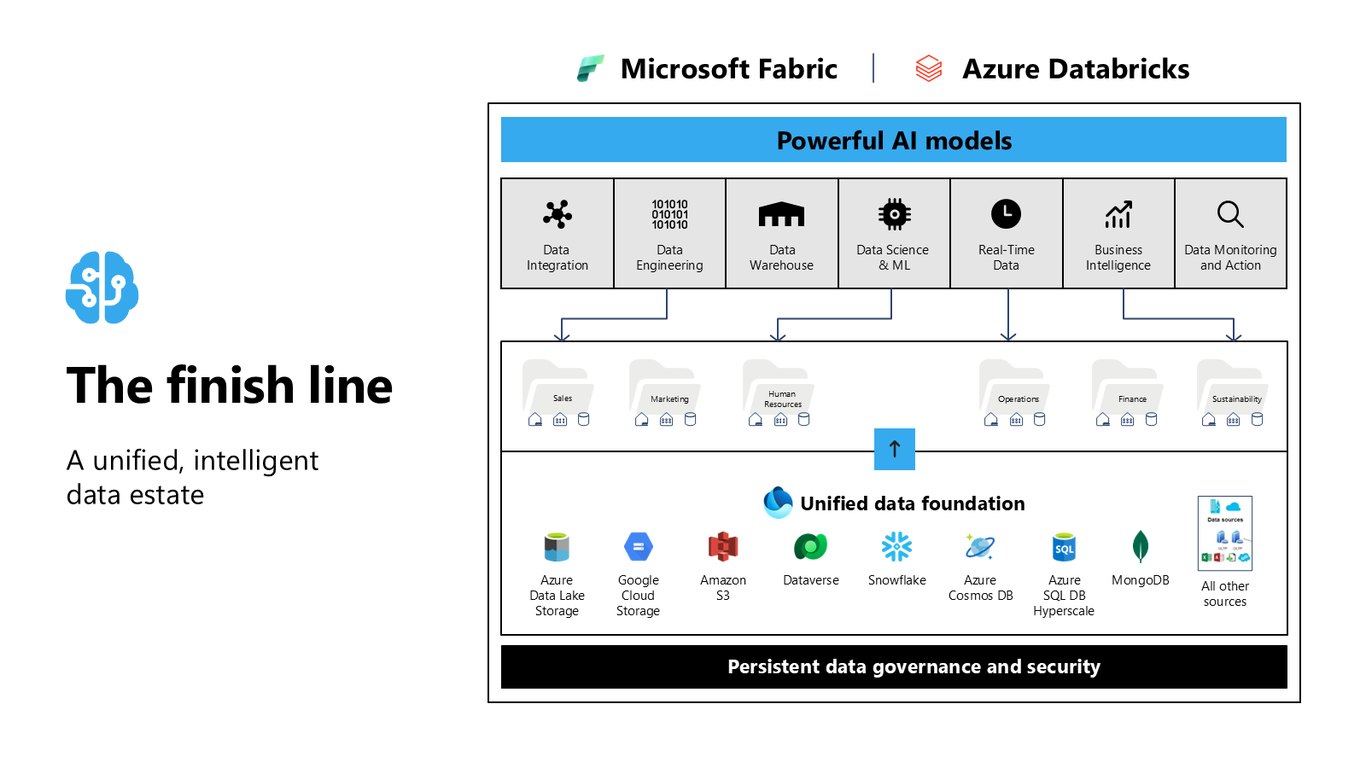
도착점: 통합된 지능형 데이터 자산
우리가 도착하고 싶은 지점은 여기입니다. S3, Google Cloud, Snowflake, Azure까지 흩어진 소스를 하나의 통합 기반 위로 모아, 강력한 AI 모델이 바로 활용할 수 있게 만드는 겁니다.
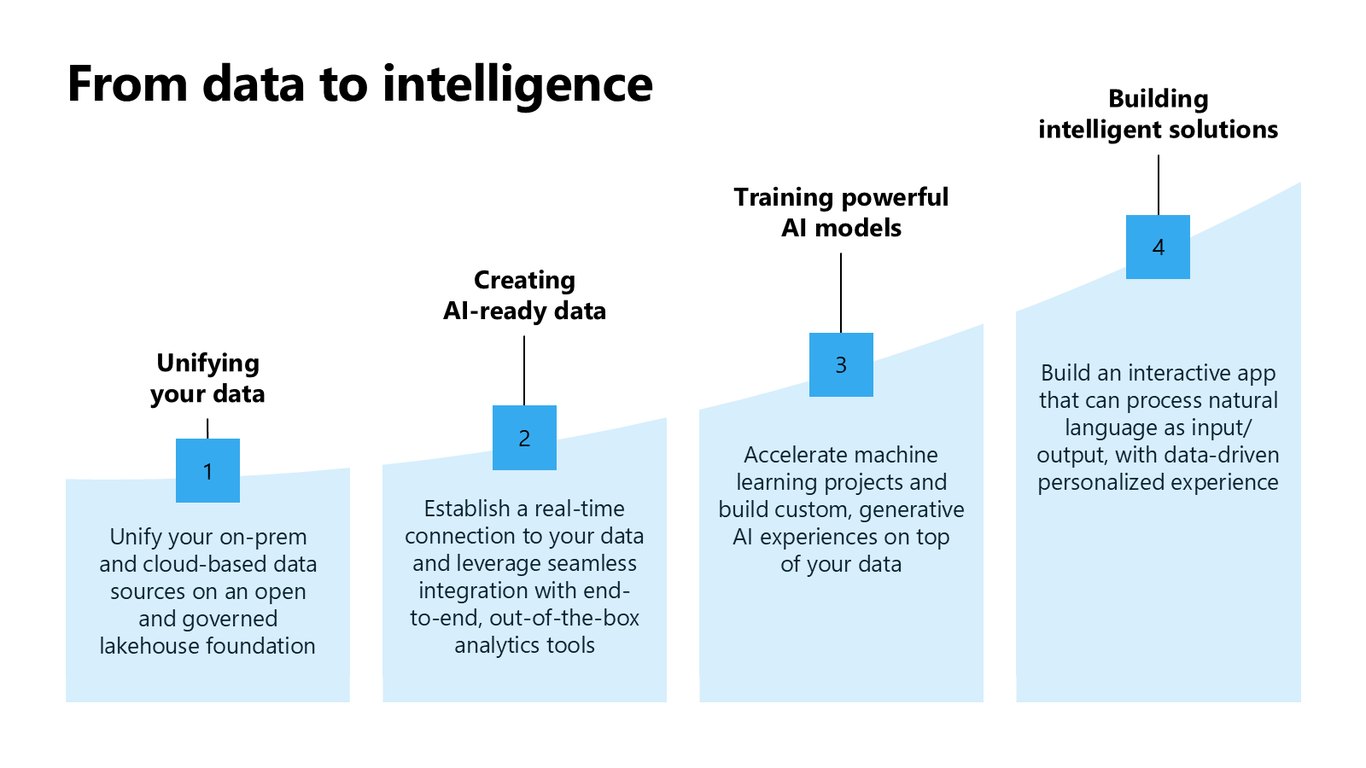
데이터에서 지능으로 가는 3단계
그 여정은 세 단계입니다. 먼저 온프레미스와 클라우드 데이터를 개방형 레이크하우스로 통합하고, 실시간으로 연결해 AI에 바로 쓸 수 있게 만든 다음, 그 위에서 강력한 AI 모델을 학습시키는 거죠.
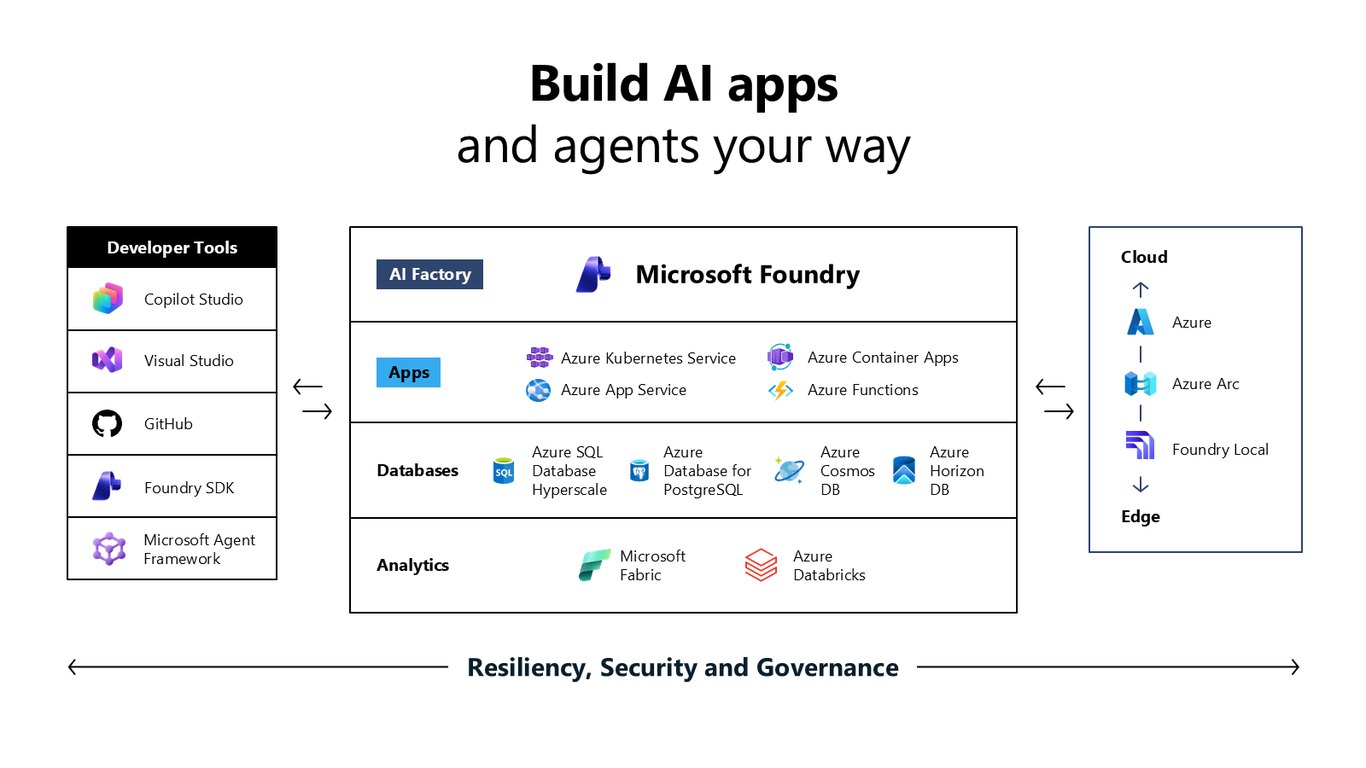
원하는 방식으로 AI 앱과 에이전트를 구축
이 기반 위에서 여러분이 원하는 방식대로 AI 앱과 에이전트를 만들 수 있습니다. 클라우드부터 엣지의 Foundry Local까지, Microsoft Foundry와 Fabric, AKS, GitHub 같은 도구가 보안과 거버넌스로 묶여 있습니다.
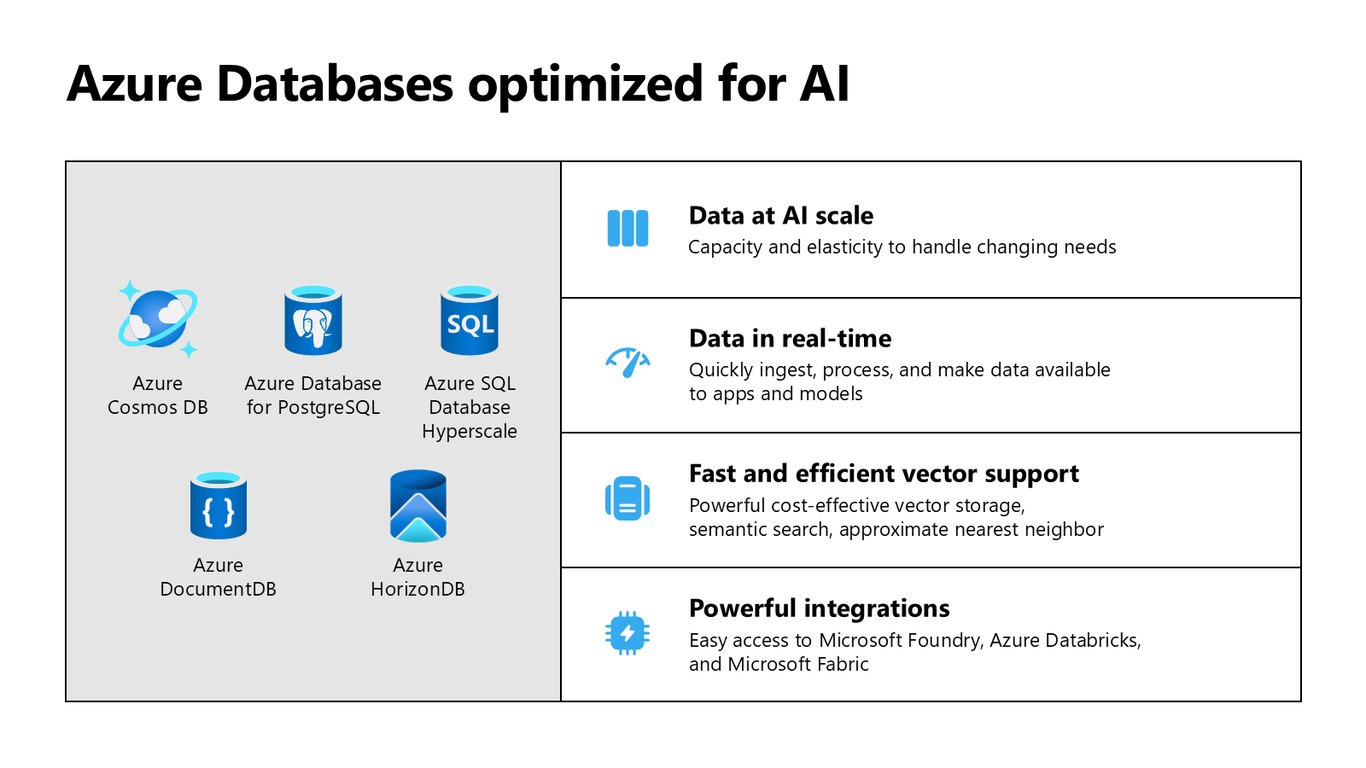
AI에 최적화된 Azure 데이터베이스
AI 규모의 데이터를 감당하려면 데이터베이스도 달라야 합니다. Azure Cosmos DB, PostgreSQL, SQL Database Hyperscale이 실시간 처리와 효율적인 벡터 지원으로 AI 워크로드에 최적화돼 있죠.
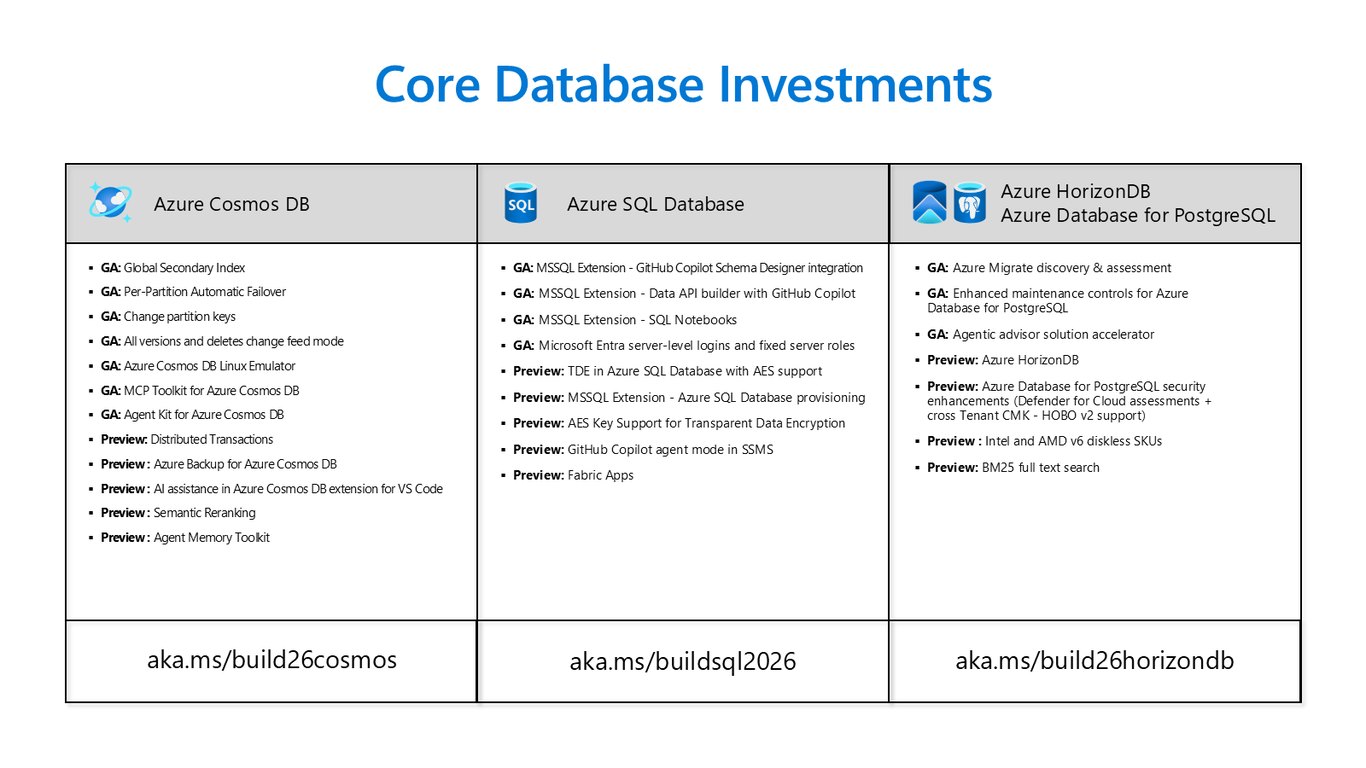
핵심 데이터베이스 투자 현황
핵심 투자도 빠르게 늘고 있습니다. Azure Cosmos DB만 봐도 Global Secondary Index, Per-Partition 자동 장애 조치가 GA로 나왔고, 분산 트랜잭션과 AI 어시스턴스가 프리뷰로 이어지고 있습니다.

이제 실제 현장 이야기로 넘어가 보겠습니다. Microsoft OCTO의 Chief Architect Rishabh Saha와 PepsiCo의 Krunal Patel이 함께 진행합니다.

PepsiCo 사례
그럼 PepsiCo가 실제로 이 기반 위에서 무엇을 만들었는지 지금부터 살펴보겠습니다.
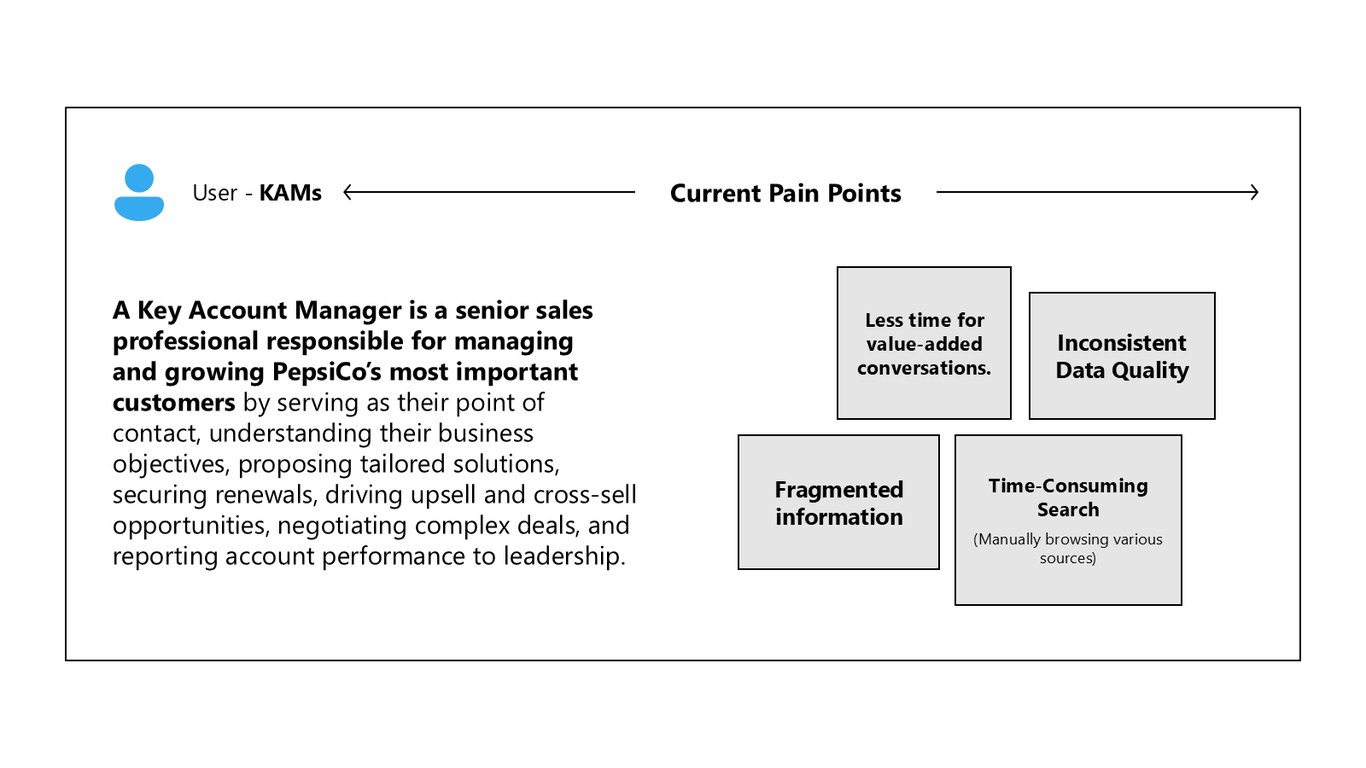
KAM 업무의 현재 고충
먼저 Key Account Manager, 즉 핵심 고객을 책임지는 영업 담당자들의 고충입니다. 데이터 품질이 들쭉날쭉하고 정보가 흩어져 있다 보니, 자료를 찾는 데 시간을 다 쓰고 정작 가치 있는 대화를 나눌 시간은 줄어듭니다.
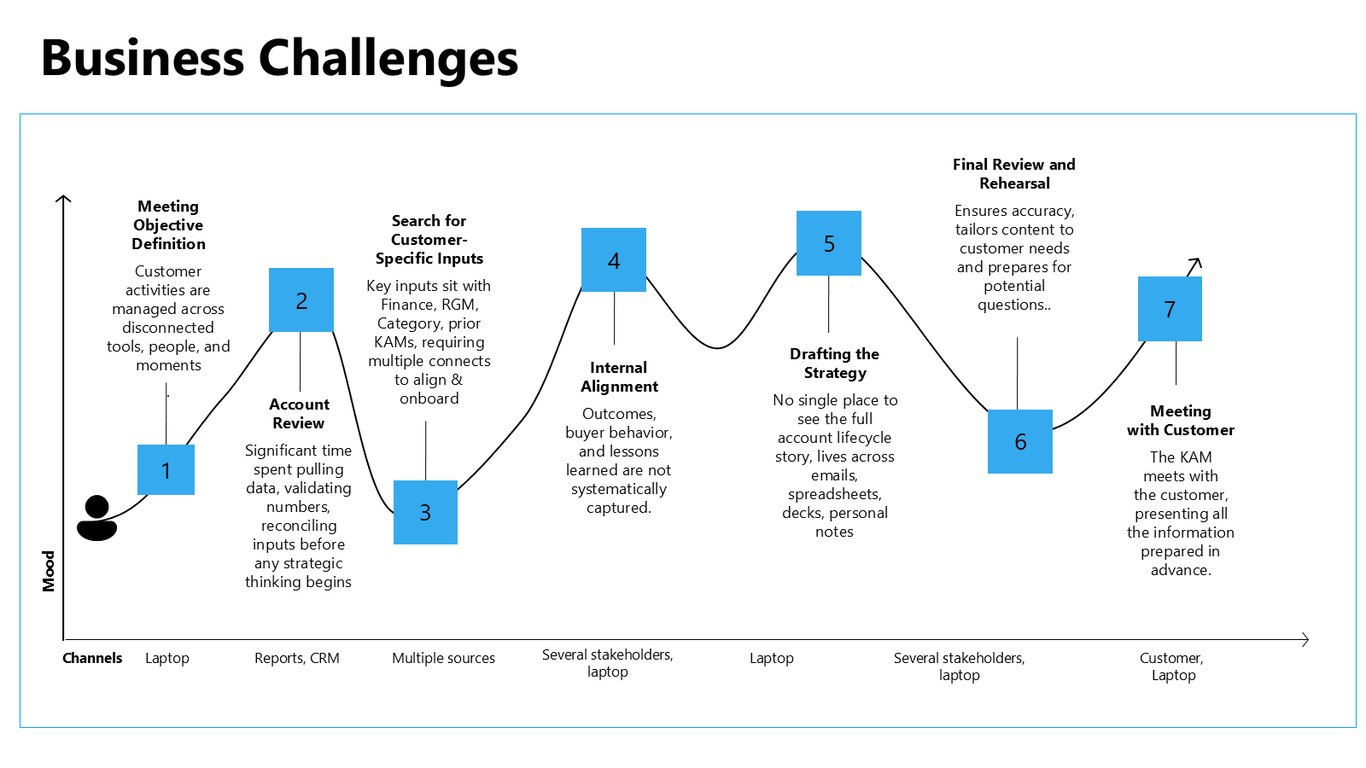
미팅 준비 여정의 단절
미팅 준비 과정을 따라가 보면 문제가 더 뚜렷해집니다. 목표 설정부터 계정 리뷰까지 도구와 사람, 순간이 다 끊겨 있어서, 숫자를 맞추고 검증하는 데만 상당한 시간이 들어갑니다.
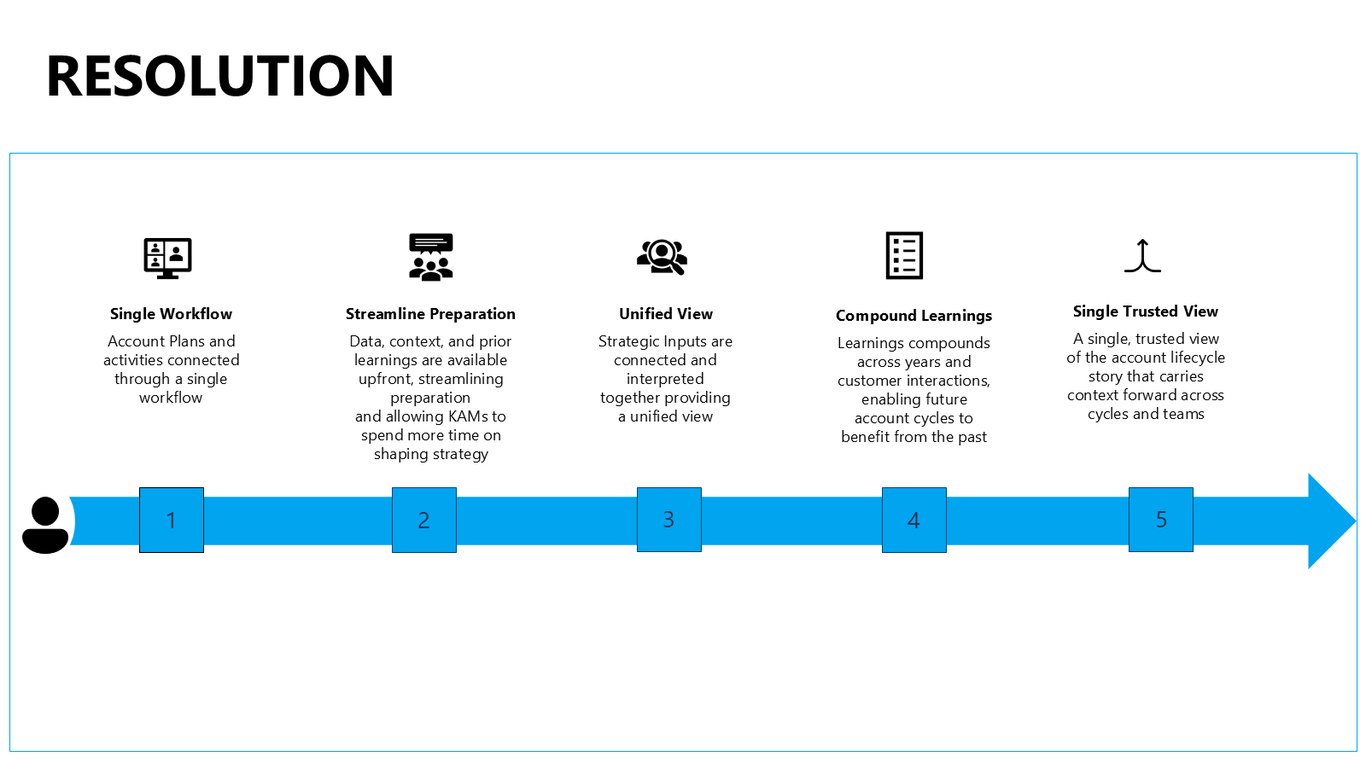
해법: 하나로 연결된 워크플로우
그래서 저희가 제안하는 해법은 하나로 연결된 워크플로우입니다. 준비 과정을 간소화하고, 전략 입력을 통합된 뷰로 묶고, 학습이 해가 갈수록 쌓여서 신뢰할 수 있는 단일 계정 스토리로 이어지게 하는 거죠.
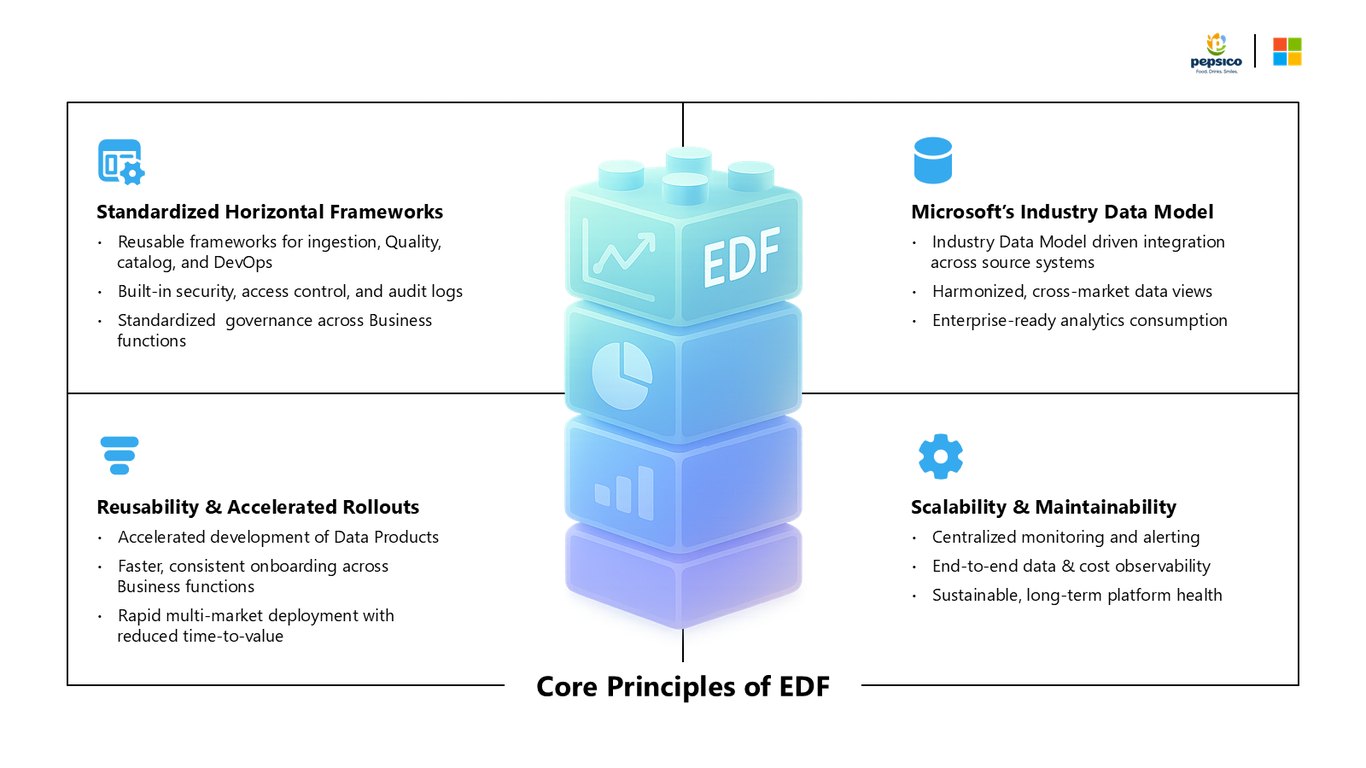
EDF의 핵심 원칙
이걸 떠받치는 게 Enterprise Data Foundation, EDF입니다. 표준화된 수평 프레임워크와 Microsoft의 Industry Data Model로 소스 시스템을 통합하고, 보안과 감사 로그를 처음부터 내장했습니다.
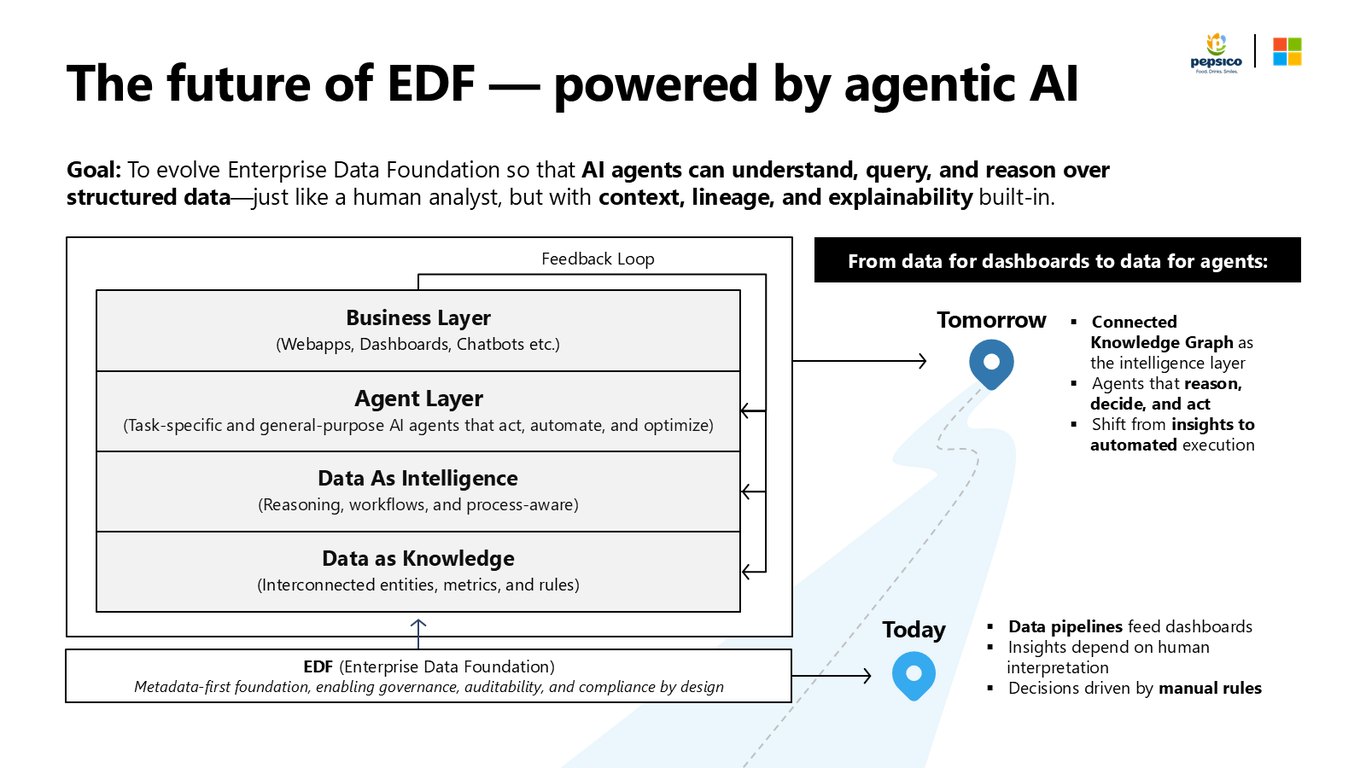
에이전틱 AI로 진화하는 EDF
EDF의 다음 단계는 에이전틱 AI입니다. 대시보드를 위한 데이터에서 에이전트를 위한 데이터로 옮겨 가서, AI 에이전트가 사람 분석가처럼 맥락과 계보를 이해하고 추론하게 만드는 게 목표죠.
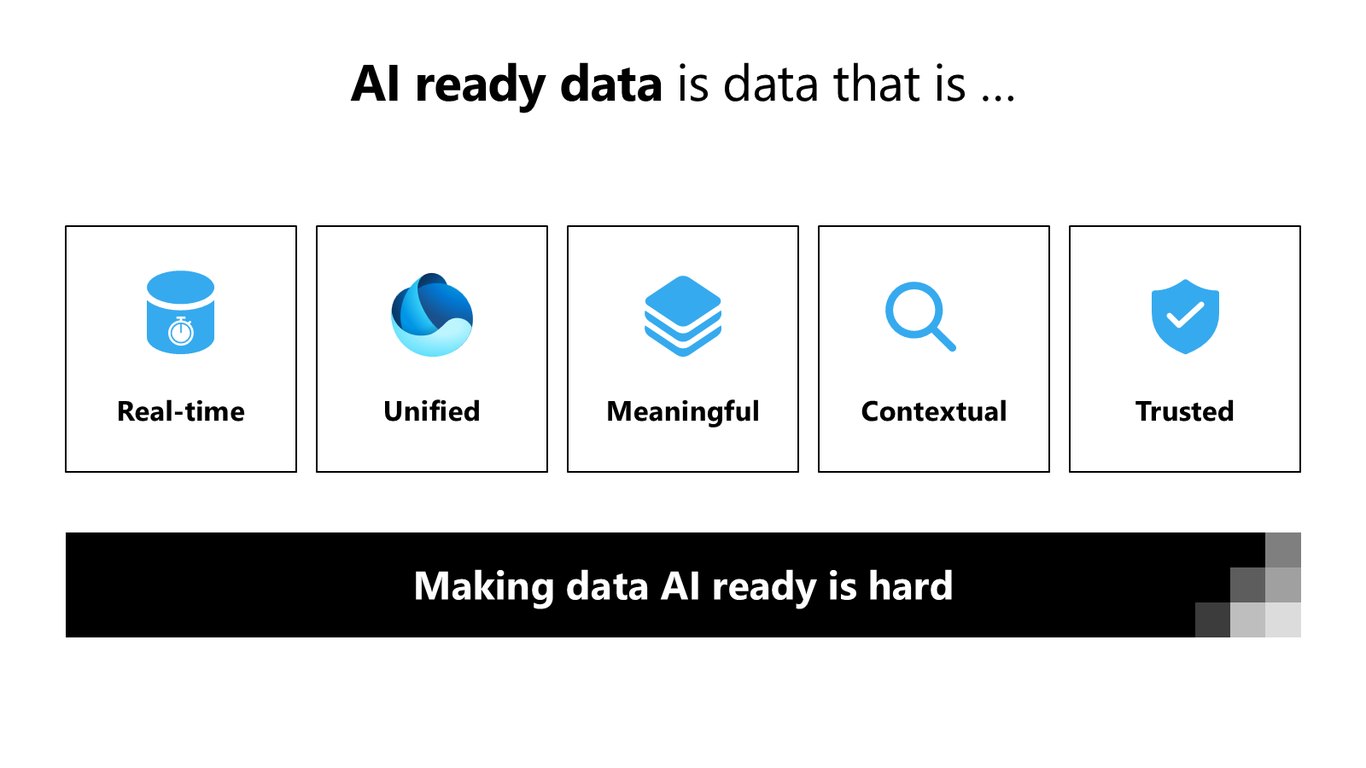
AI-ready 데이터란
그렇다면 AI에 바로 쓸 수 있는 데이터란 뭘까요. 실시간이고, 통합돼 있고, 의미가 있고, 맥락이 담기고, 신뢰할 수 있어야 합니다. 말은 쉽지만 실제로 이걸 갖추는 건 정말 어렵습니다.
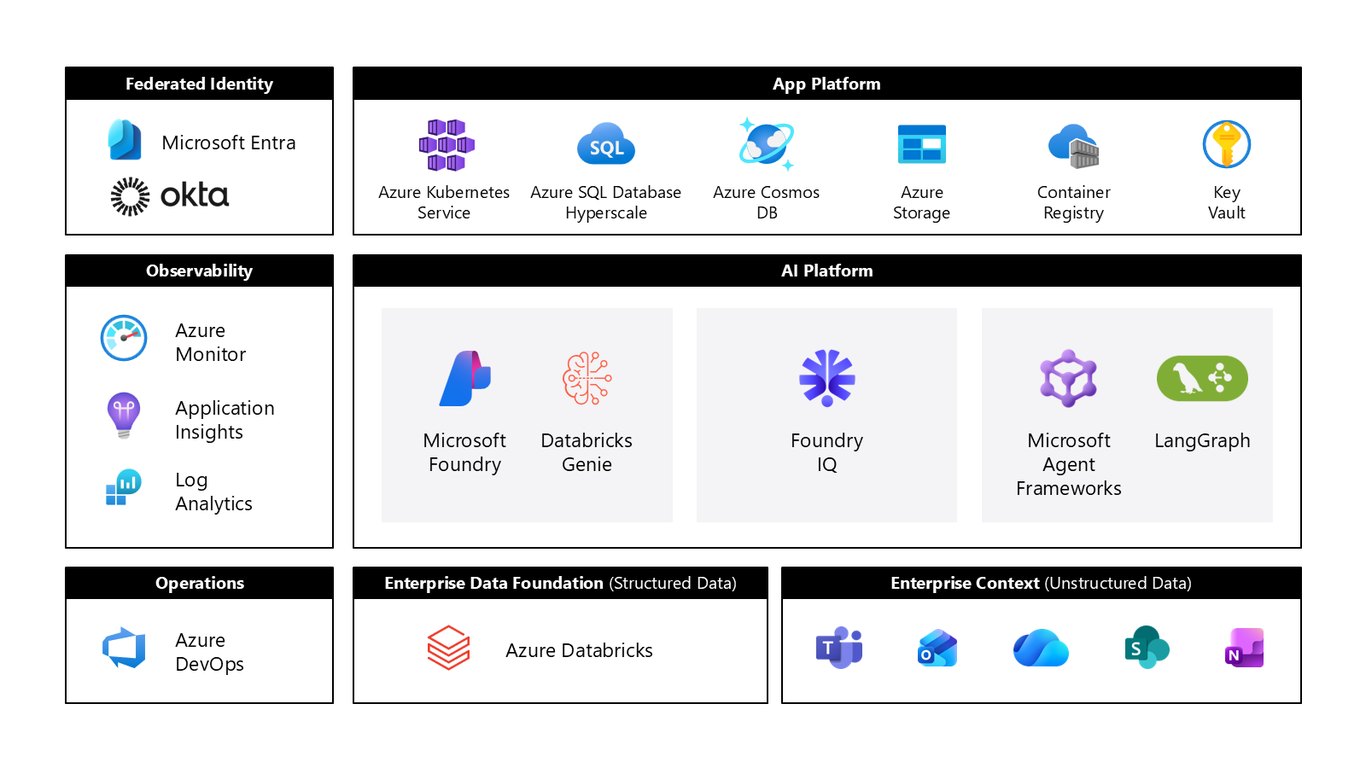
엔드투엔드 AI 플랫폼 스택
이 모든 걸 담아낸 게 PepsiCo의 엔드투엔드 스택입니다. Microsoft Entra의 페더레이션 인증부터 AKS, Azure SQL Hyperscale, Cosmos DB, 그리고 Microsoft Foundry와 Databricks Genie까지 한 층씩 쌓아 올렸습니다.
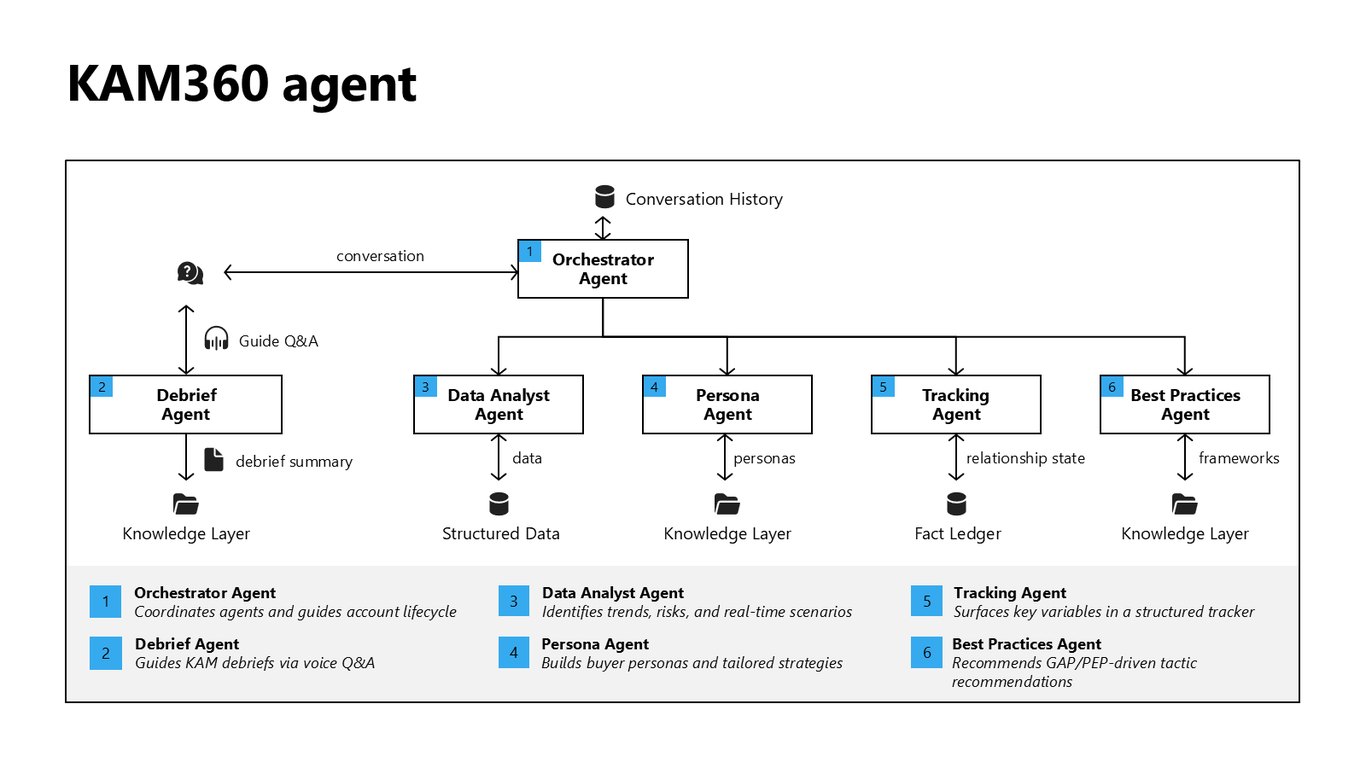
KAM360 에이전트 구성
그 위에서 돌아가는 게 KAM360 에이전트입니다. 트렌드를 읽는 Data Analyst, 페르소나를 만드는 Persona, 변수를 추적하는 Tracking, 그리고 이들을 조율하는 Orchestrator까지 여섯 개 에이전트가 계정 라이프사이클을 함께 이끕니다.

먼저 Data Analyst Agent부터 자세히 들여다보겠습니다.
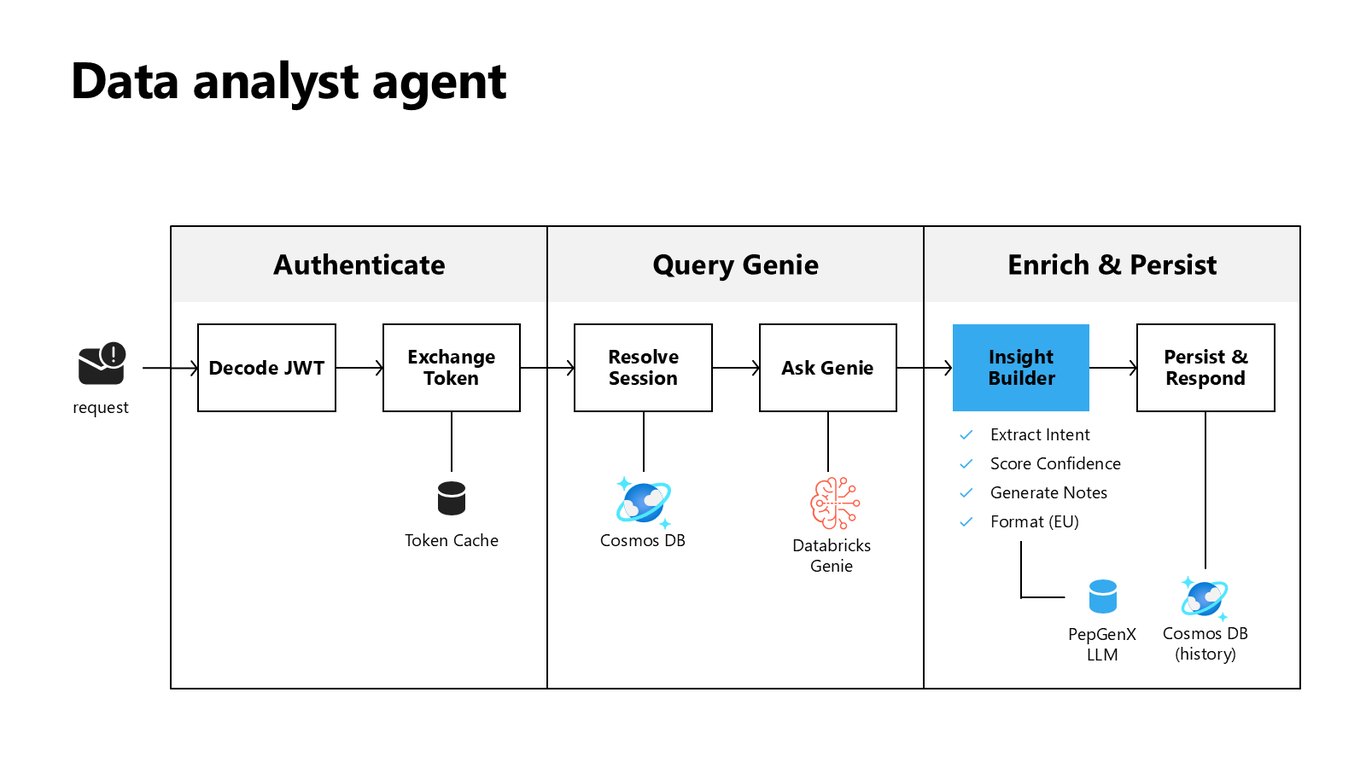
Data Analyst Agent 동작 흐름
동작을 따라가 보면, 요청이 들어오면 JWT를 디코딩하고 세션을 확인한 뒤 Databricks Genie에 질의합니다. 의도를 추출하고 신뢰도를 매겨 인사이트를 만들고, PepGenX LLM으로 다듬어 Cosmos DB에 이력을 남기죠.
자, 이제 말로만 하지 말고 직접 움직이는 모습을 보시죠.
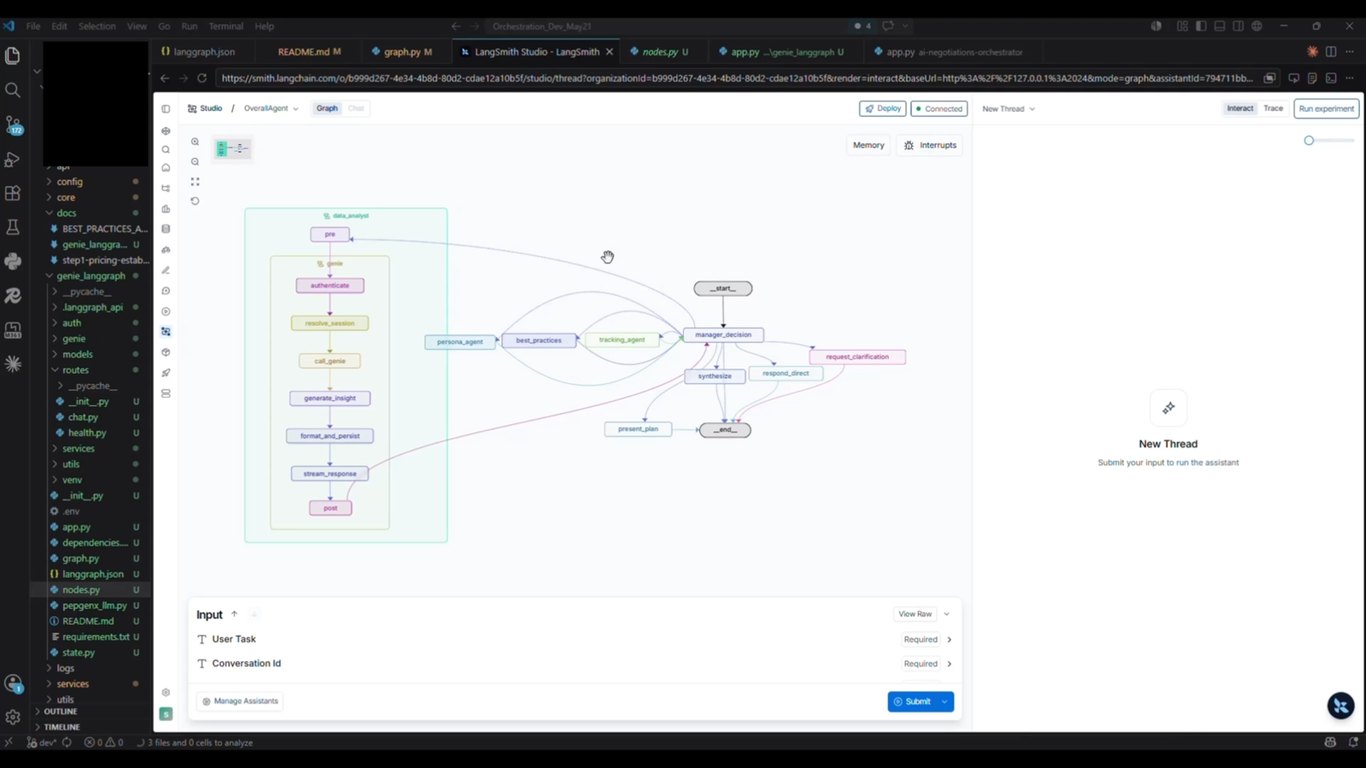
Data Analyst Agent 데모
보시는 것처럼 KAM이 자연어로 물으면 에이전트가 실시간 데이터를 읽어 바로 인사이트를 돌려줍니다.

다음은 시간이 갈수록 똑똑해지는 Tracking Agent를 보겠습니다.
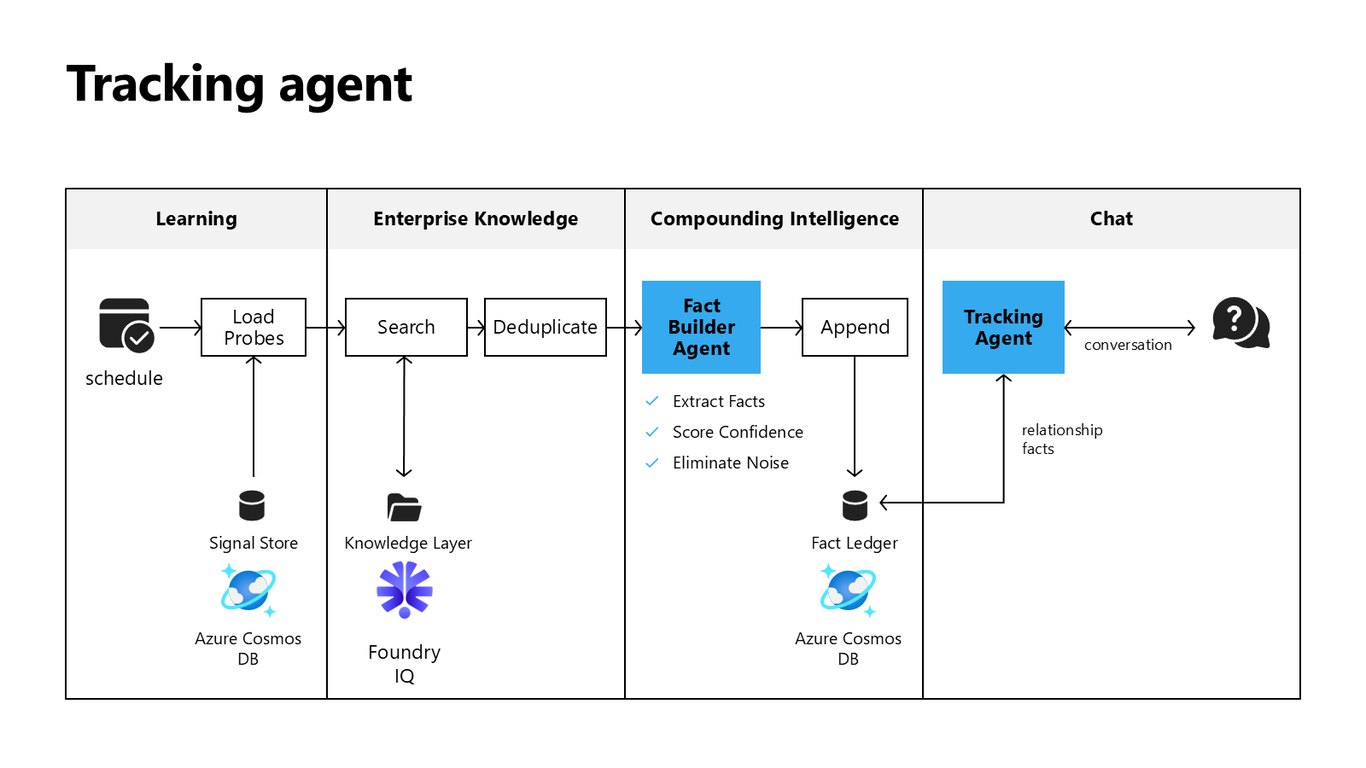
Tracking Agent 동작 흐름
Tracking Agent는 대화와 신호에서 관계 사실을 추출하고 신뢰도를 매겨 노이즈를 걸러냅니다. 이렇게 정리된 사실을 Fact Ledger에 쌓아 Foundry IQ와 Cosmos DB 위에서 지식이 복리처럼 불어나게 하죠.
이 부분도 실제로 어떻게 작동하는지 함께 보겠습니다.
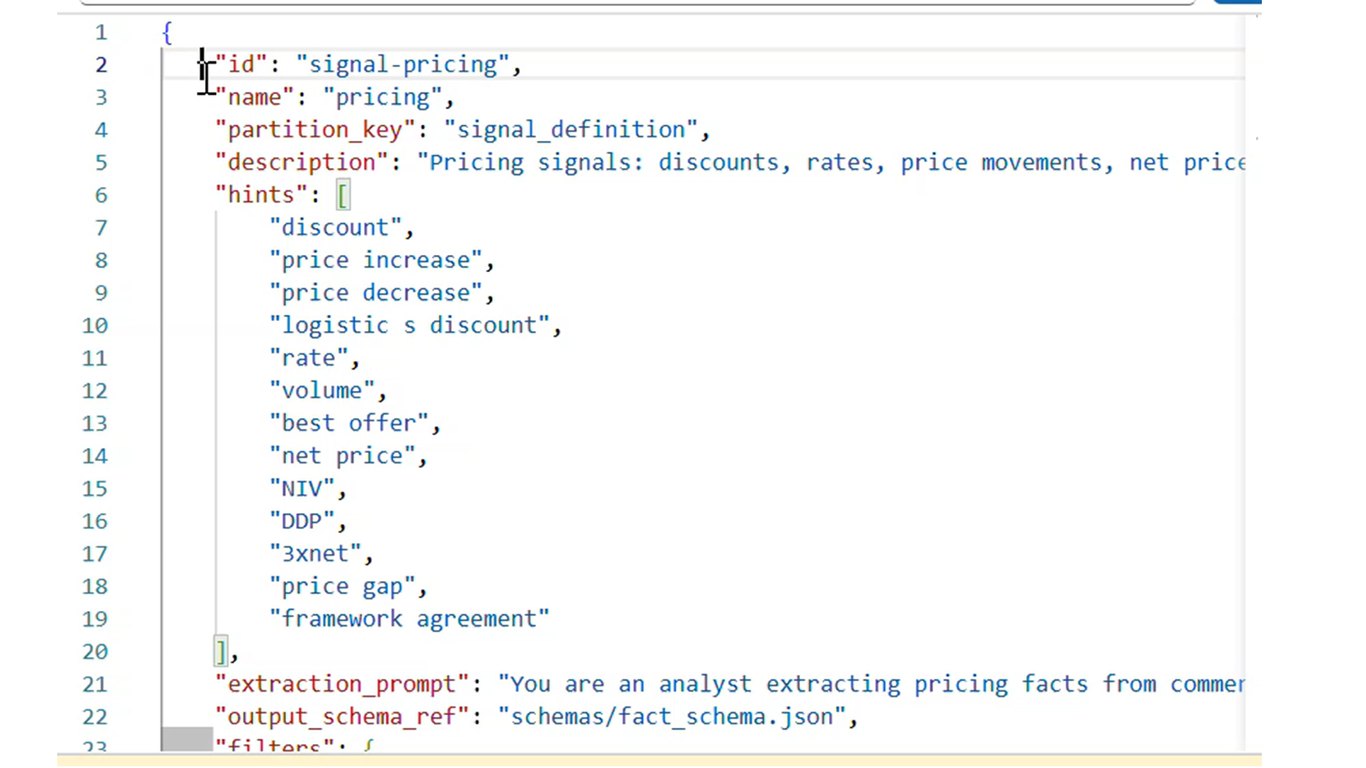
Tracking Agent 데모 (1)
대화 속에서 핵심 사실이 어떻게 자동으로 잡히는지 보시죠.
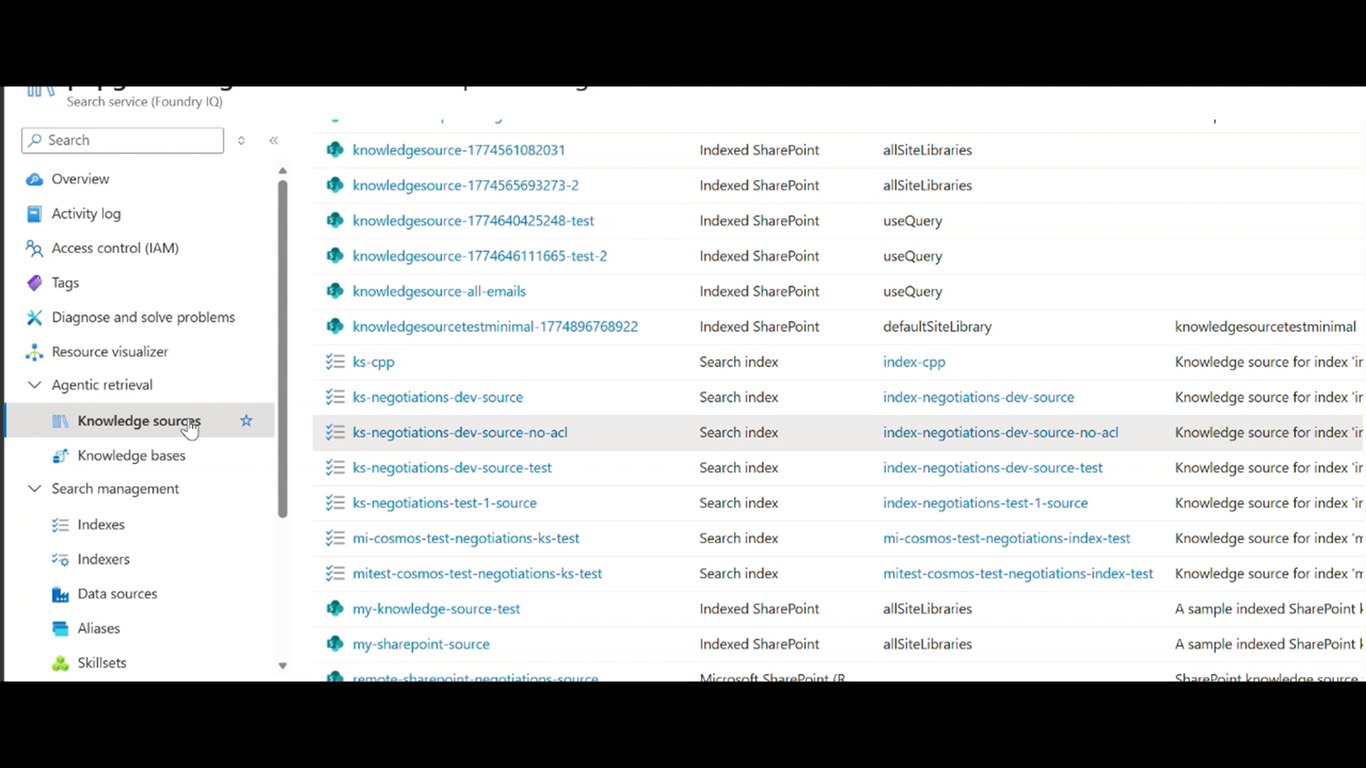
Tracking Agent 데모 (2)
이렇게 추출된 사실이 중복 제거를 거쳐 지식 계층에 차곡차곡 쌓입니다.
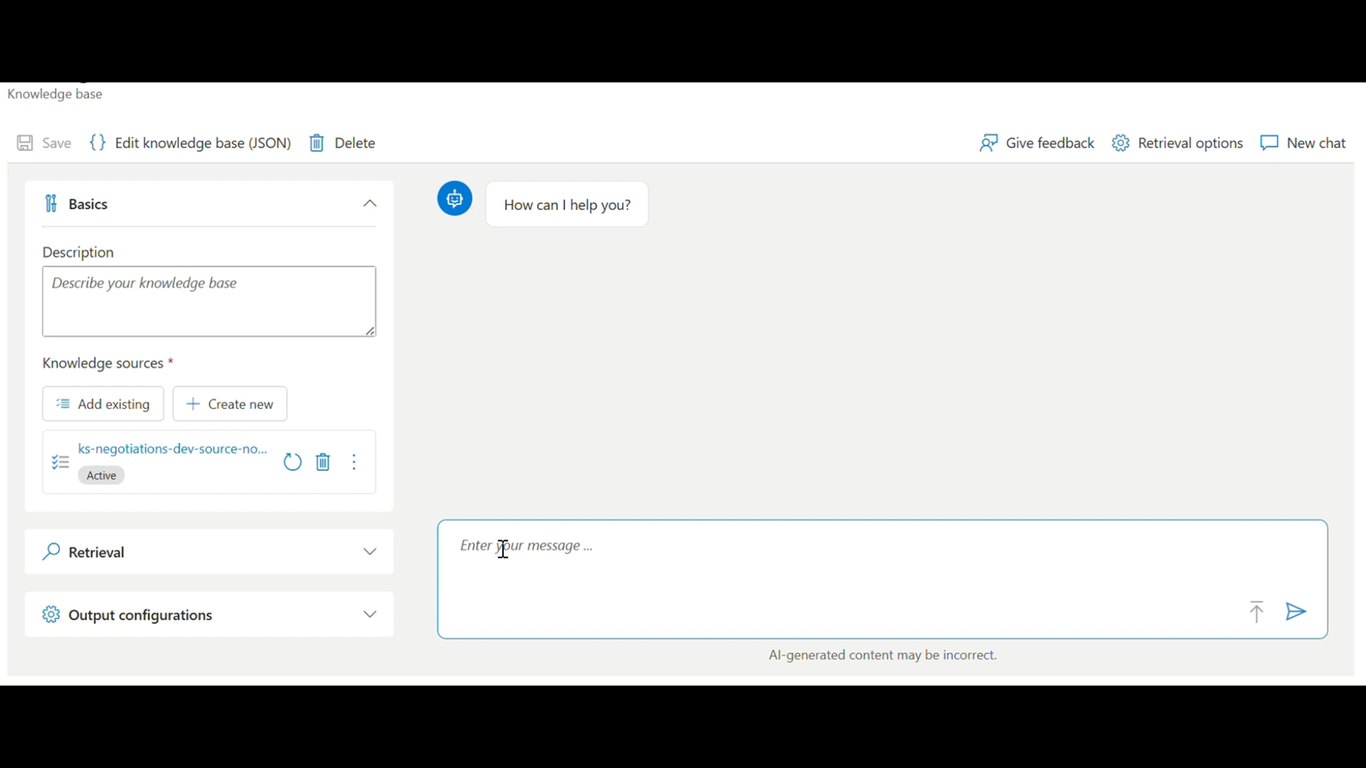
Tracking Agent 데모 (3)
쌓인 사실들이 다음 계정 사이클에서 어떻게 다시 활용되는지 이어서 보겠습니다.
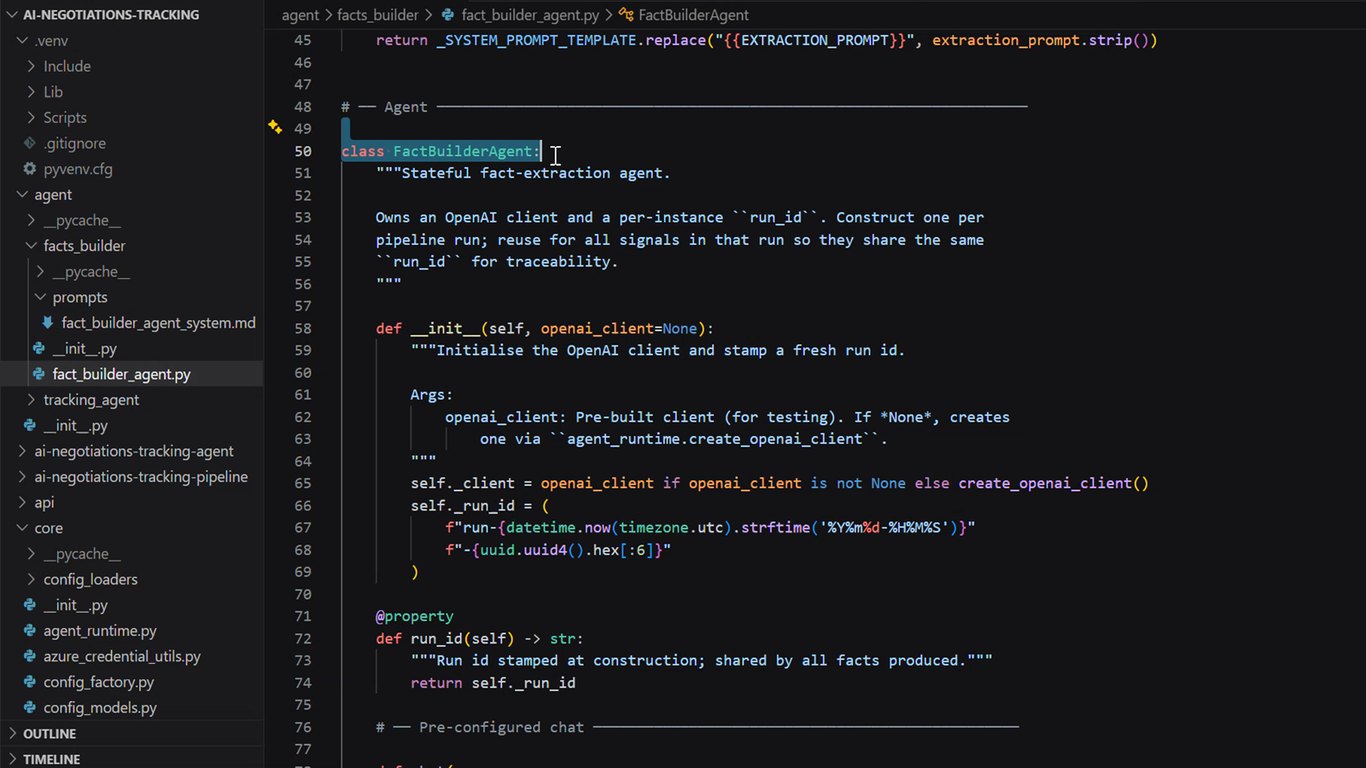
Tracking Agent 데모 (4)
에이전트가 축적된 맥락을 바탕으로 더 정교한 판단을 내리는 걸 확인할 수 있습니다.
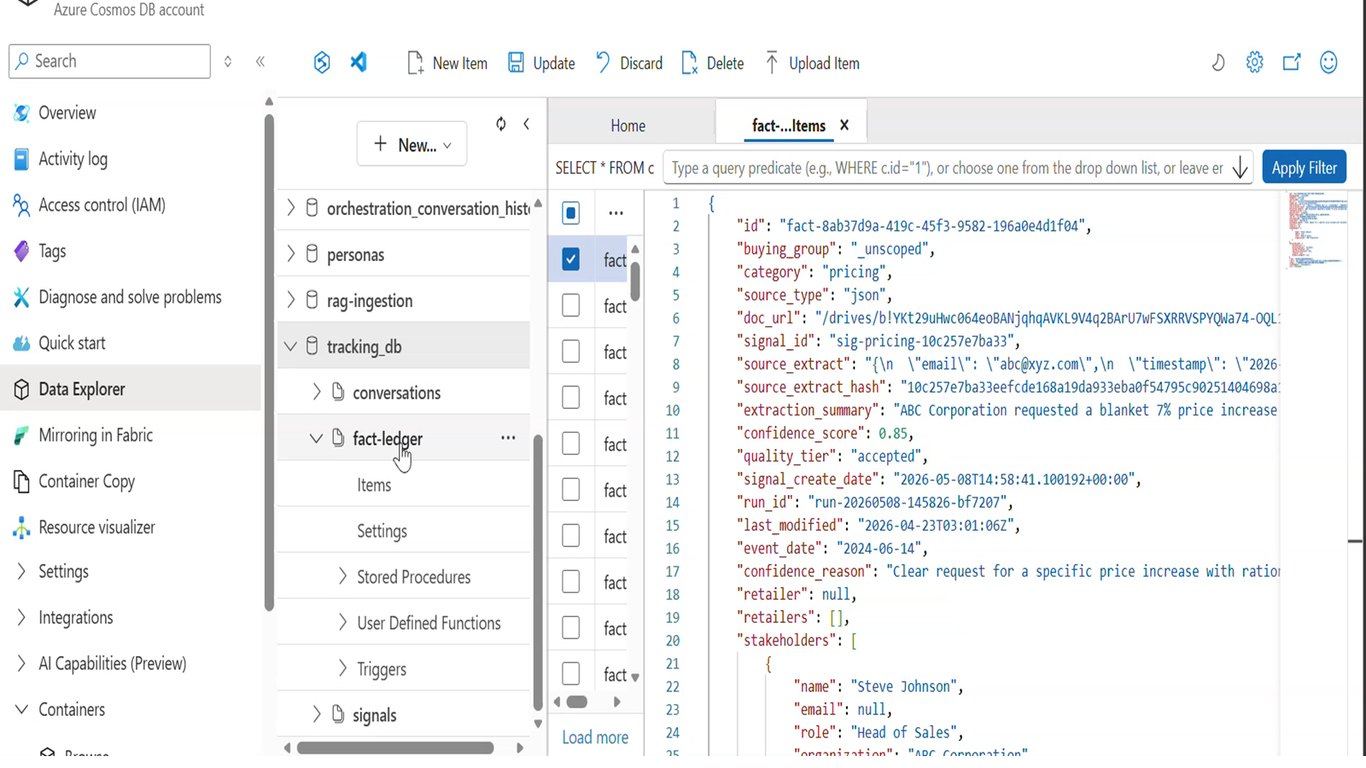
Tracking Agent 데모 (5)
여러 상호작용을 거치면서 지식이 복리처럼 불어나는 흐름을 보여드립니다.
Tracking Agent 데모 (6)
실제 KAM 업무 시나리오에 적용했을 때 얼마나 자연스럽게 녹아드는지 보시죠.
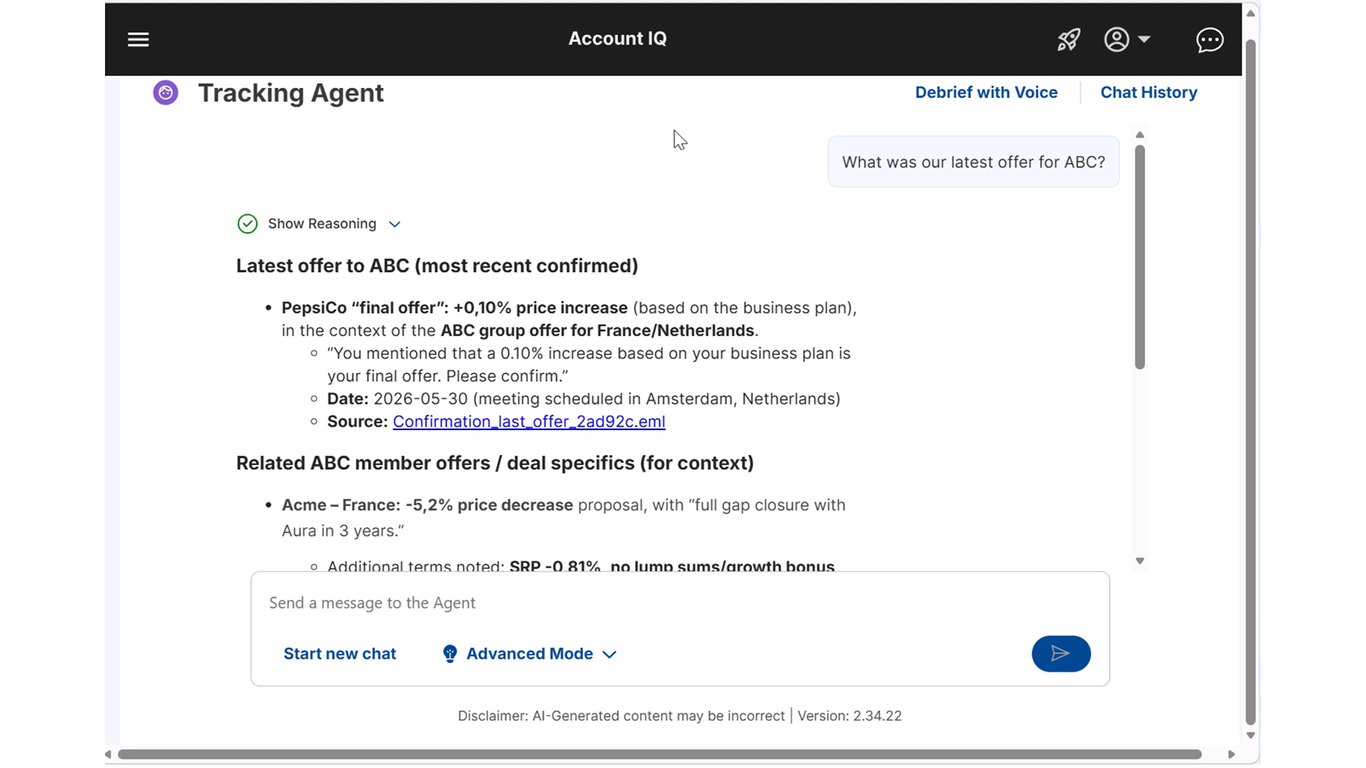
Tracking Agent 데모 (7)
마지막으로 추적된 인사이트가 실제 의사결정으로 어떻게 이어지는지 보여드립니다.
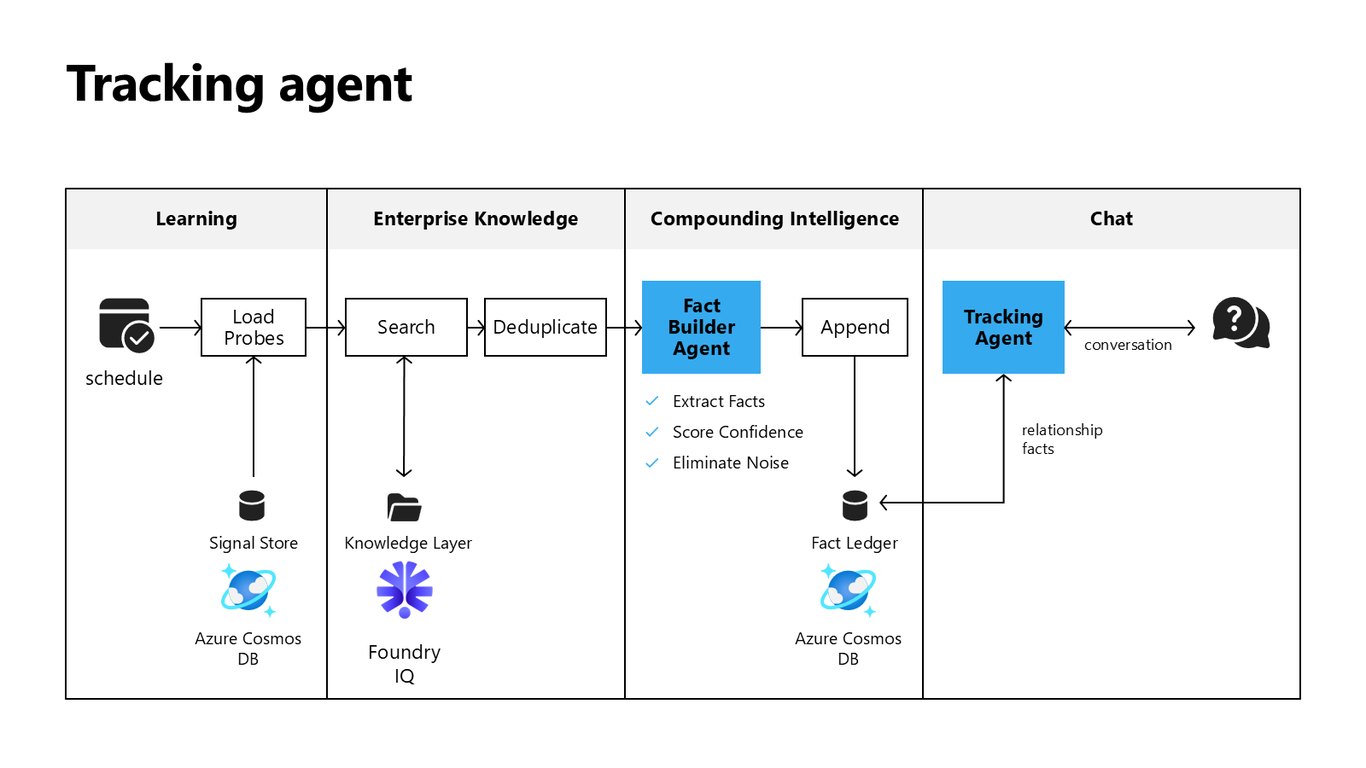
Tracking Agent 아키텍처 정리
정리하면, Chat과 스케줄로 신호를 받아 Fact Builder Agent가 사실을 다듬고, 지식 계층에 append하며 기업 지식이 계속 성장하는 구조입니다.
이제 이 여정에서 저희가 배운 교훈을 나눠 보겠습니다.

우리가 얻은 세 가지 교훈
핵심은 세 가지입니다. 한 번에 바다를 끓이려 하지 말고 하나의 워크플로우, 하나의 페르소나부터 시작하세요. 데이터 품질을 얕봤더니 에이전트가 환각을 일으켰고, 반대로 제대로 된 EDF가 갖춰지자 에이전트의 가치가 복리로 불어났습니다.
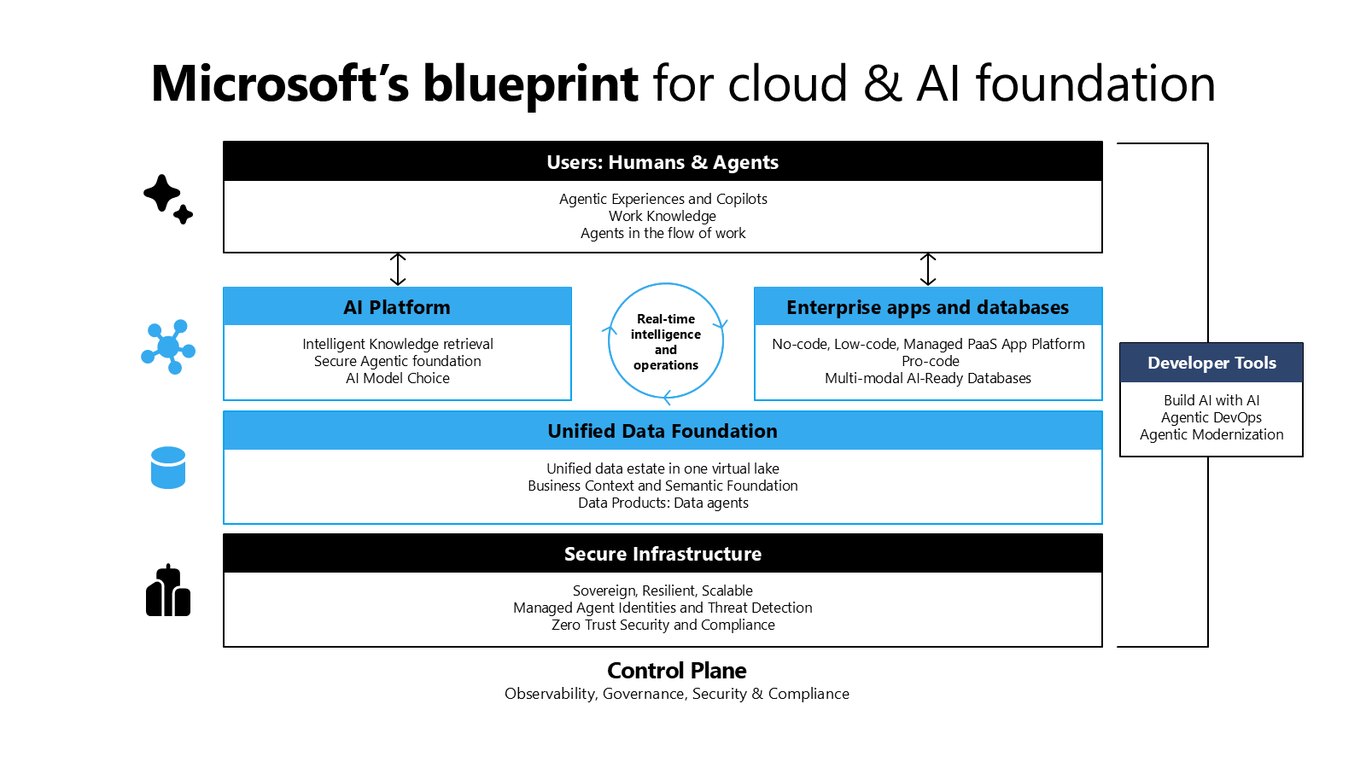
Microsoft의 클라우드·AI 기반 청사진
이 경험을 Microsoft의 청사진으로 정리하면 이렇습니다. 하나의 가상 레이크로 통합된 데이터 기반 위에 AI 플랫폼과 앱 플랫폼을 올리고, 관측성과 거버넌스, Zero Trust 보안이 전체를 감싸는 구조죠.

이제 여러분이 직접 시작해 볼 수 있는 리소스를 안내해 드리겠습니다.

Azure AI 서비스 무료로 체험
먼저 비용 걱정 없이 시작해 보세요. Azure Databricks는 무료 체험으로, Azure Cosmos DB와 Azure SQL Database는 무료 티어로 바로 만져 볼 수 있습니다.
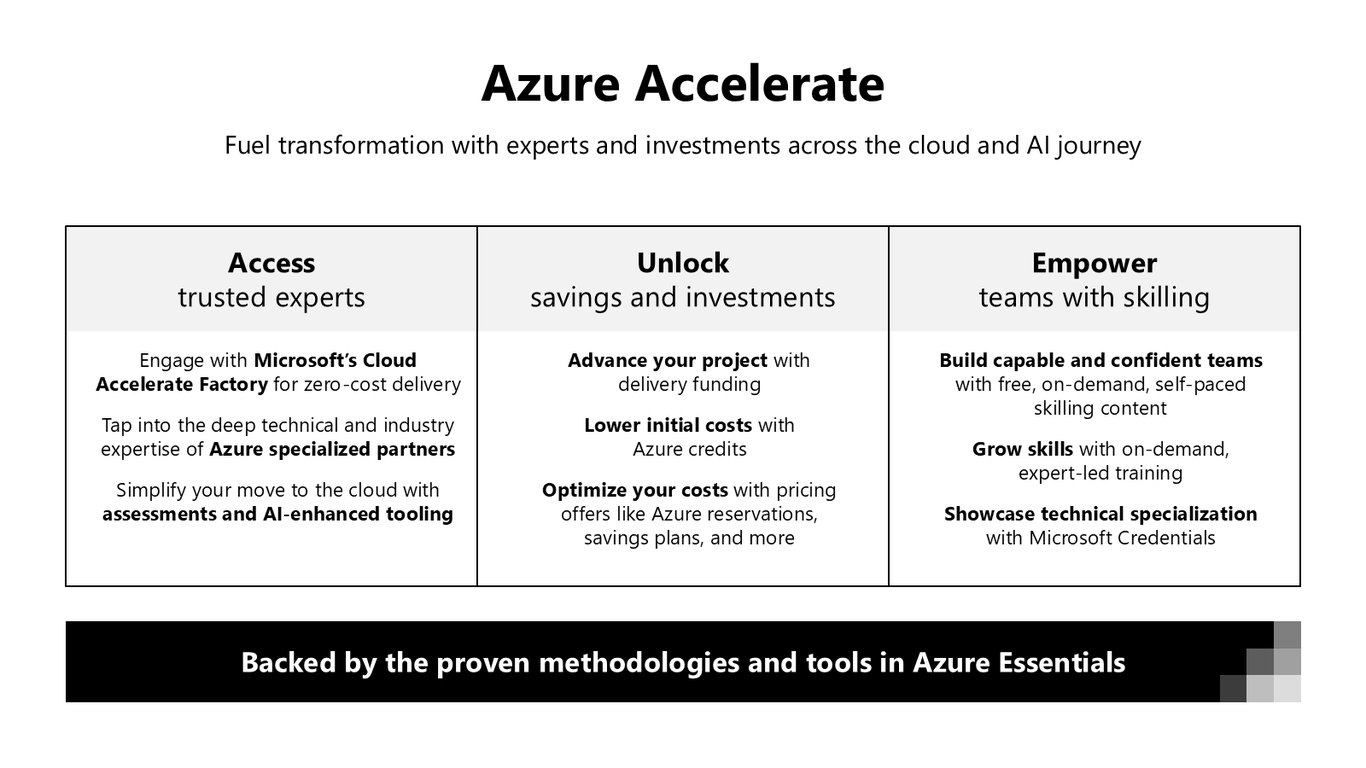
Azure Accelerate
더 큰 전환이 필요하다면 Azure Accelerate가 있습니다. 신뢰할 수 있는 전문가, 비용 절감과 투자, 그리고 팀 역량 강화까지 클라우드와 AI 여정 전반을 지원합니다.
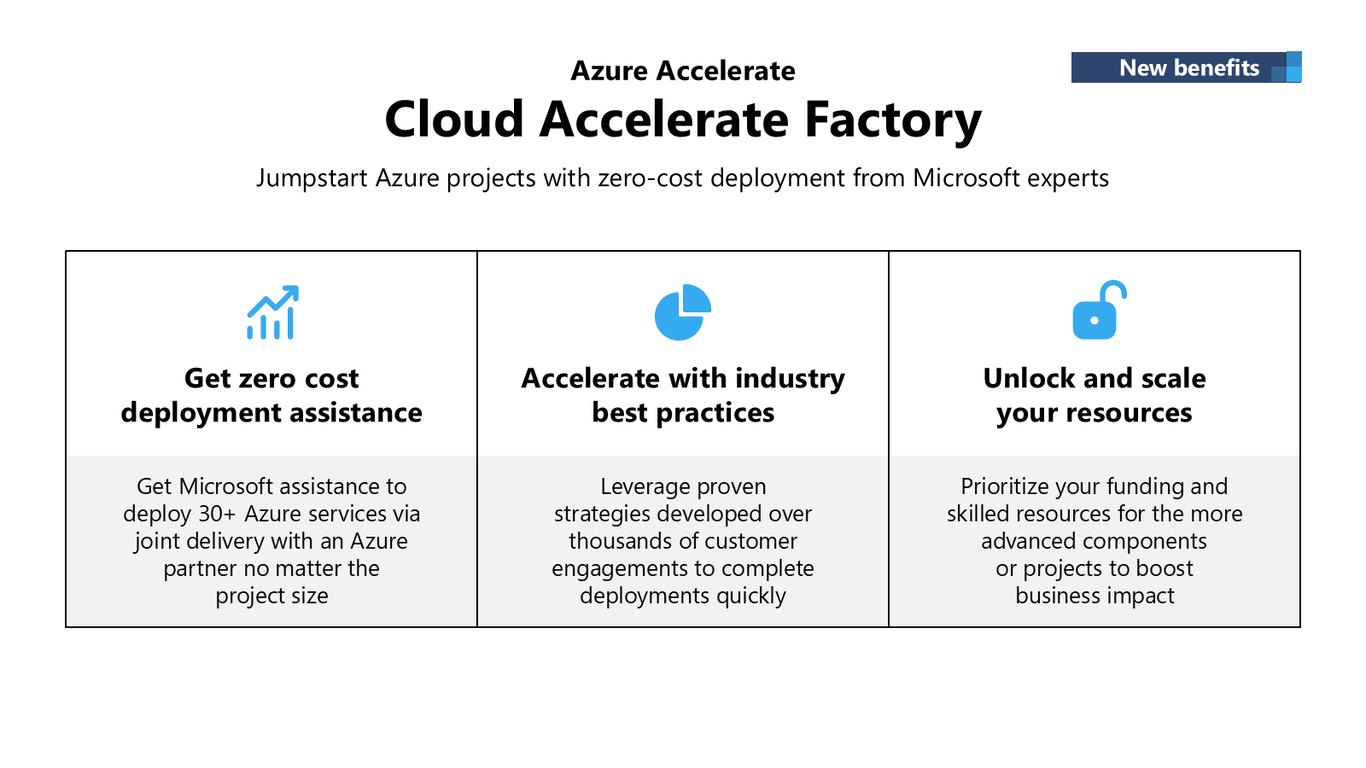
Cloud Accelerate Factory
특히 Cloud Accelerate Factory를 활용하면 Microsoft 전문가가 무료로 배포를 도와드립니다. 프로젝트 규모와 상관없이 30개 이상의 Azure 서비스를 파트너와 함께 검증된 모범 사례로 배포할 수 있죠.
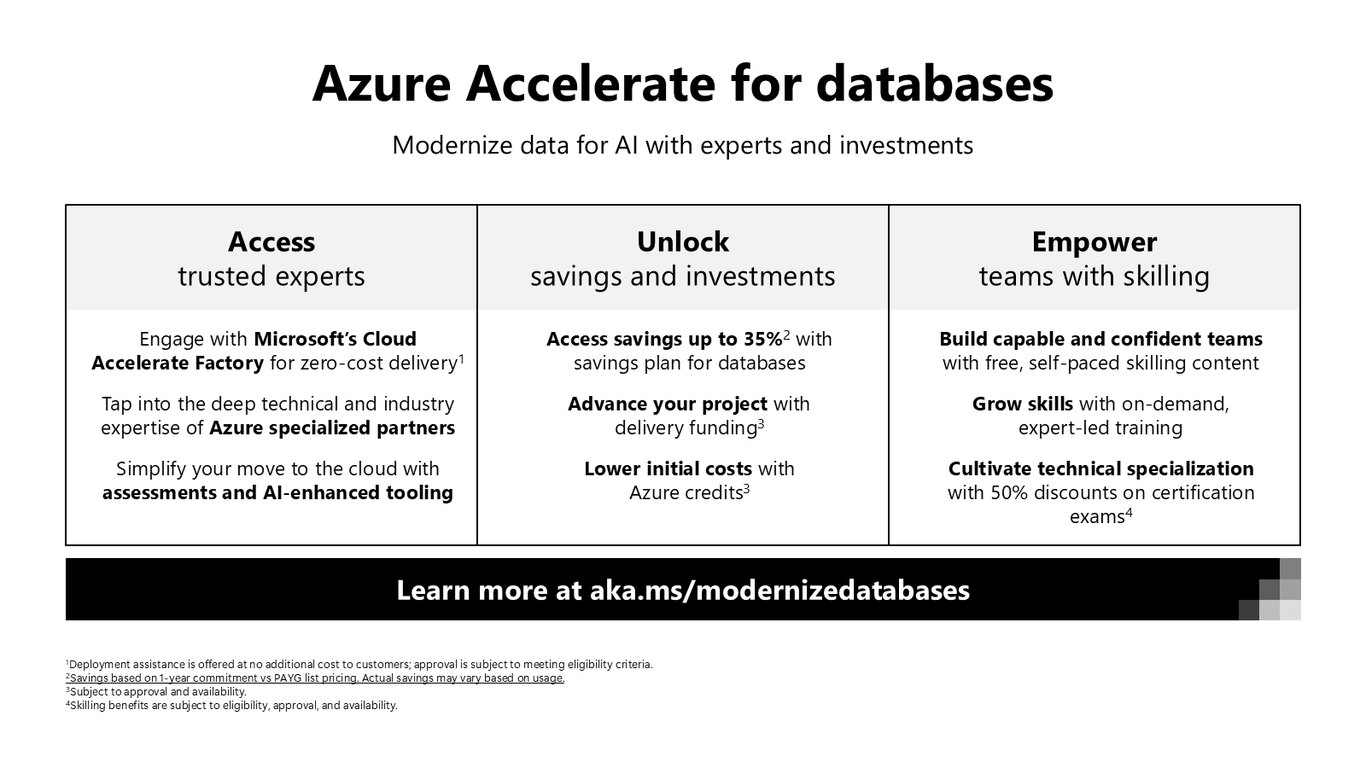
데이터베이스를 위한 Azure Accelerate
데이터 현대화에 초점을 맞춘 프로그램도 있습니다. Savings plan으로 최대 35%까지 비용을 아끼고, 전문가 지원과 스킬링까지 받아 AI를 위한 데이터로 옮겨 갈 수 있습니다.

GitHub의 데모 코드
오늘 보신 데모 코드는 모두 GitHub에 올려 두었습니다. aka.ms/build26/BRK224에서 직접 받아 보실 수 있습니다.

세션 상세 페이지와 설문
세션 상세 페이지에서 튜토리얼과 리소스, 코드로 바로 이어서 실습해 보세요. aka.ms/build/evals나 QR 코드로 설문에도 참여해 주시면 감사하겠습니다.

감사합니다
감사합니다.