
안녕하세요, 오늘은 오픈소스 추론 모델을 Microsoft Foundry에서 어떻게 후처리 학습하고 배포하는지, 그 전체 루프를 닫는 이야기를 해보겠습니다. 참고로 Festival Pavilion 세션은 제공된 헤드셋으로 들으실 수 있습니다.
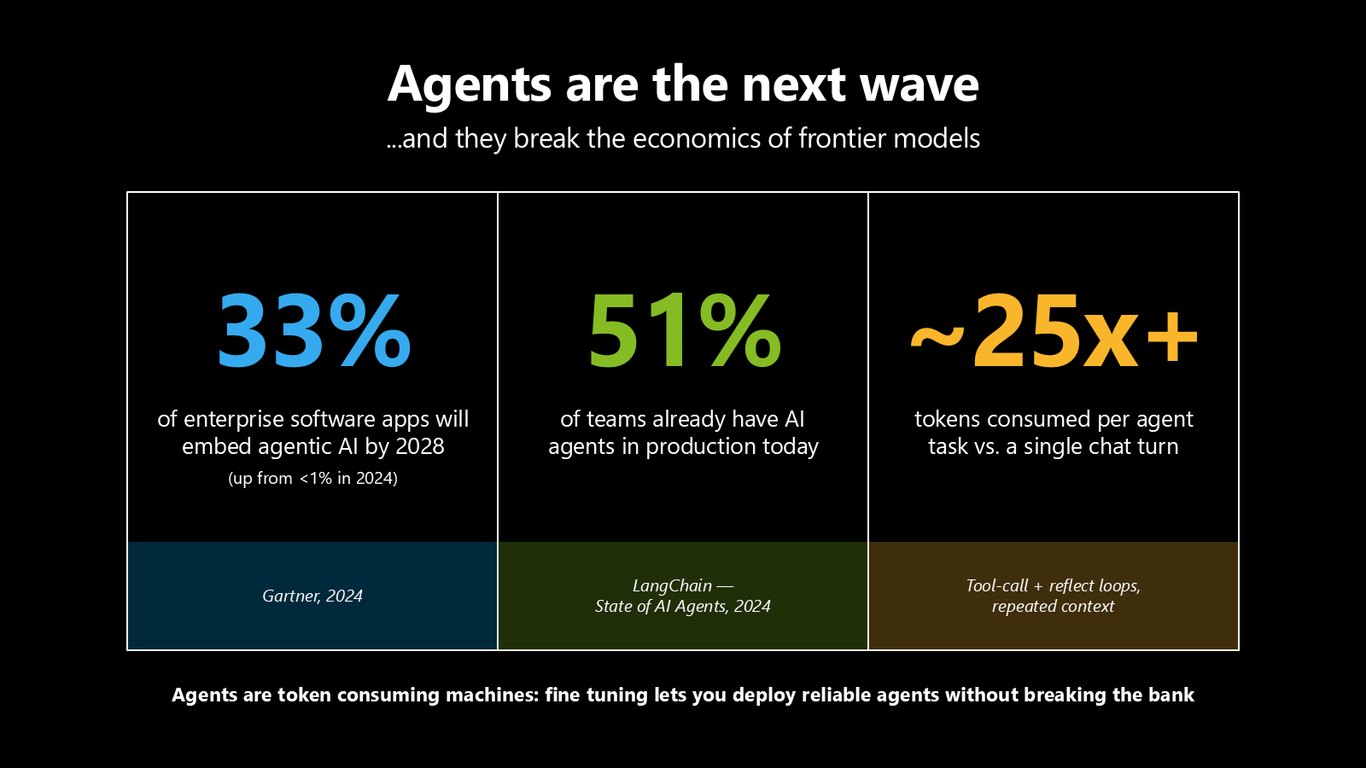
에이전트가 다음 물결입니다
에이전트가 다음 물결인데요, 문제는 이게 프론티어 모델의 경제성을 무너뜨린다는 겁니다. 2028년이면 엔터프라이즈 앱의 33%가 에이전트 AI를 탑재하고, 이미 절반이 넘는 팀이 프로덕션에 에이전트를 돌리고 있습니다. 그런데 에이전트 한 작업은 단일 채팅보다 토큰을 25배 넘게 먹습니다. 그래서 파인튜닝이 필요한 거죠.
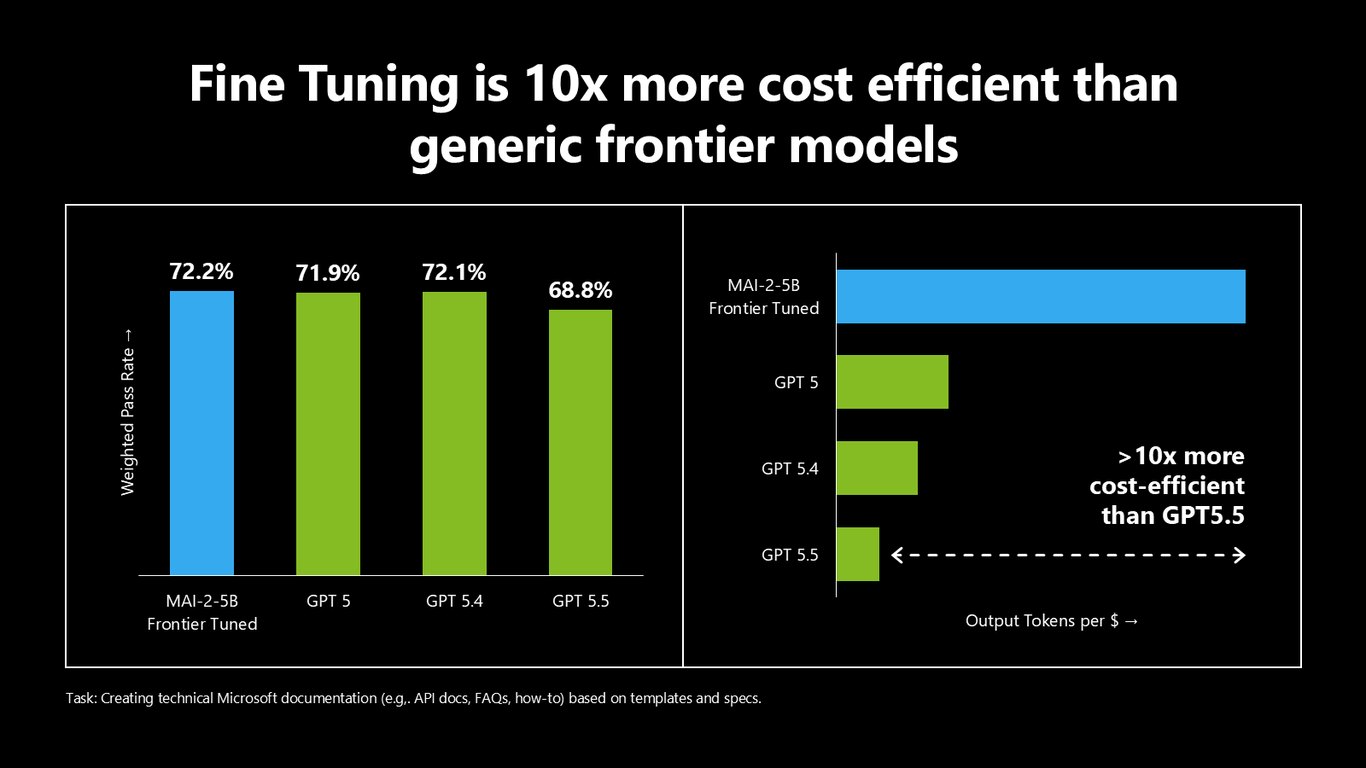
파인튜닝은 10배 더 비용 효율적
파인튜닝하면 범용 프론티어 모델보다 10배 넘게 비용 효율적입니다. 예를 들어 API 문서나 FAQ, how-to 같은 Microsoft 기술 문서를 템플릿 기반으로 생성하는 작업이라면, GPT5.5 대비 10배 이상 저렴하게 같은 일을 해낼 수 있습니다.
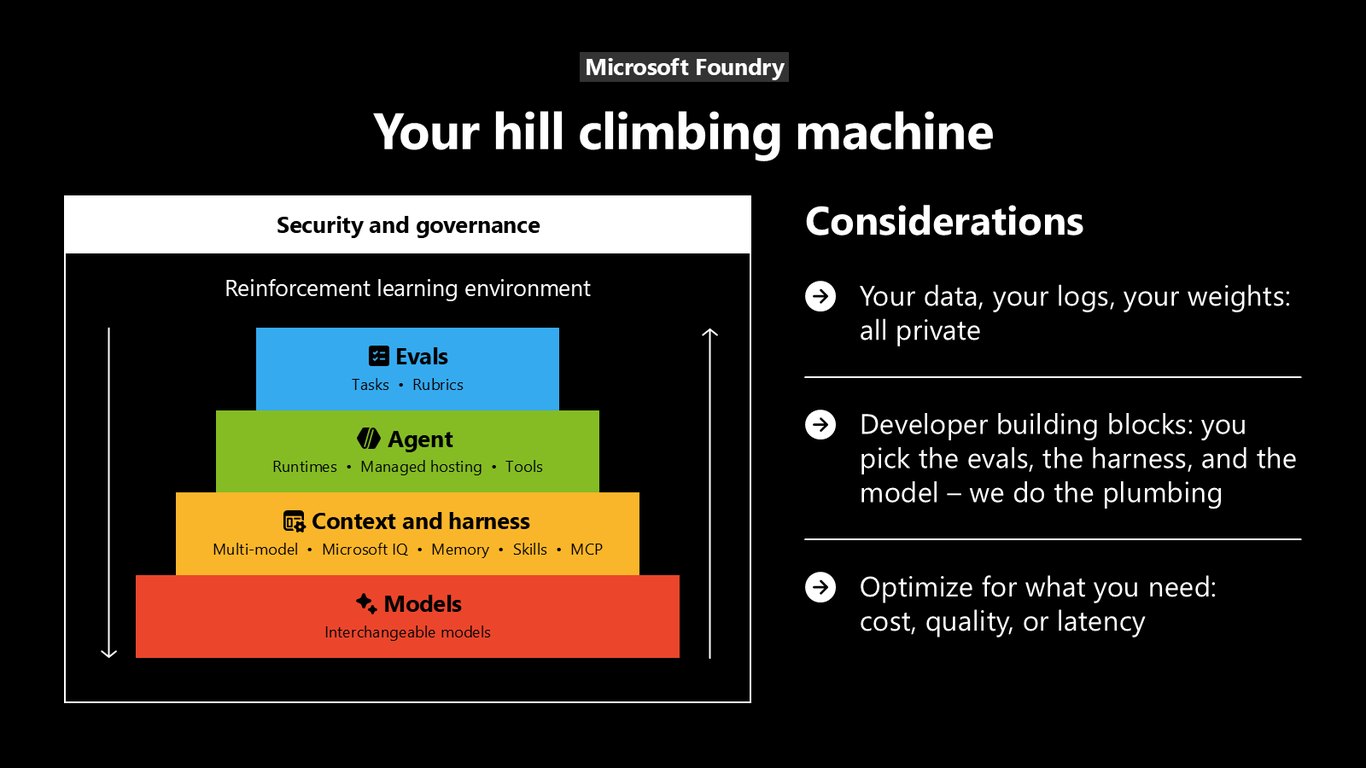
여러분의 힐 클라이밍 머신, Foundry
Microsoft Foundry를 저는 '언덕을 오르는 기계'라고 부릅니다. 강화학습 환경, 평가, 에이전트 런타임, 그리고 교체 가능한 모델까지 개발 빌딩 블록을 다 제공하는데요. 핵심은 데이터도, 로그도, 가중치도 전부 여러분 것으로 프라이빗하게 남는다는 점입니다. 비용이든 품질이든 지연이든, 필요한 걸 골라 최적화하시면 됩니다.
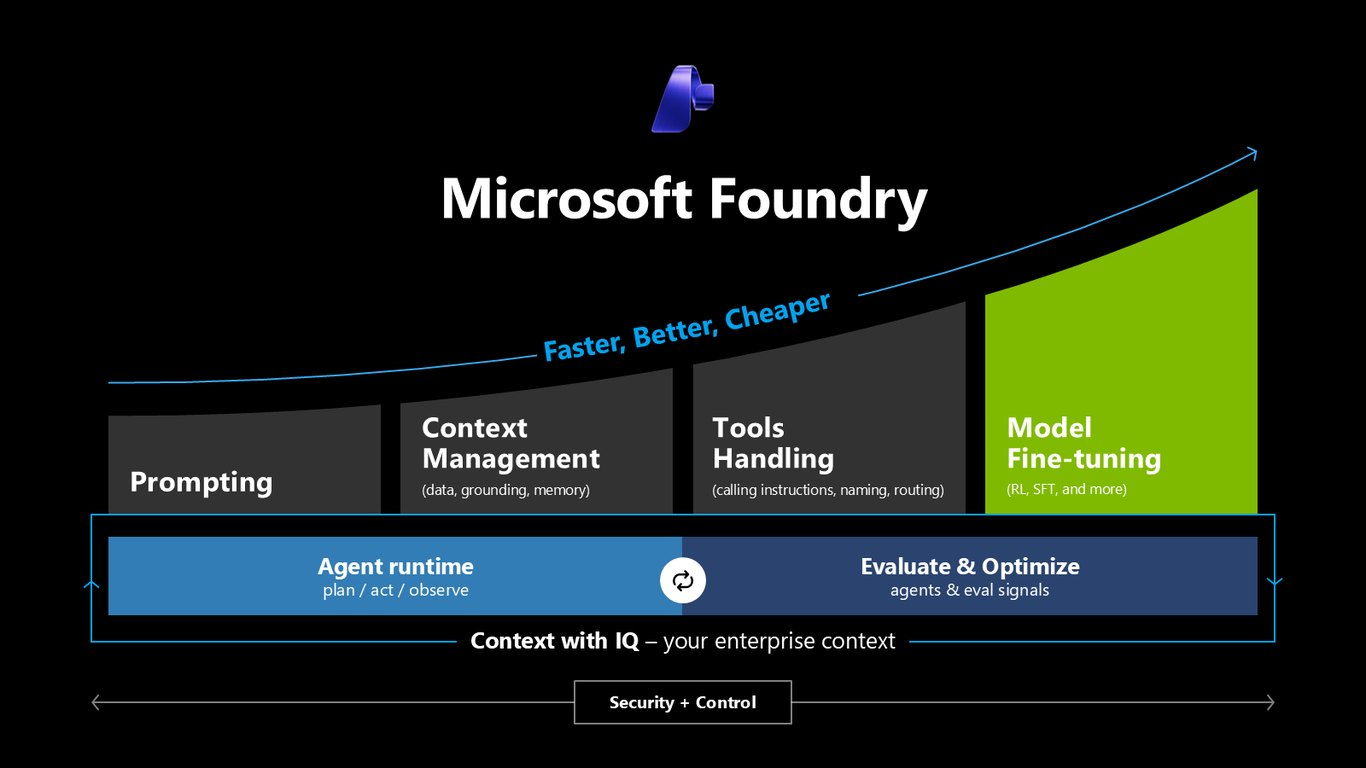
더 빠르고, 더 좋고, 더 싸게
프롬프팅, 컨텍스트 관리, 툴 핸들링, 파인튜닝, 에이전트 런타임, 그리고 평가와 최적화까지. Foundry는 이 전 과정을 하나로 엮어서 더 빠르고, 더 좋고, 더 싸게 만들어 줍니다. 여기에 IQ로 여러분의 엔터프라이즈 컨텍스트를 붙이고, 보안과 통제까지 함께 가져갑니다.

자, 이제 첫 번째 단계, 모델을 선택하는 이야기부터 시작하겠습니다.
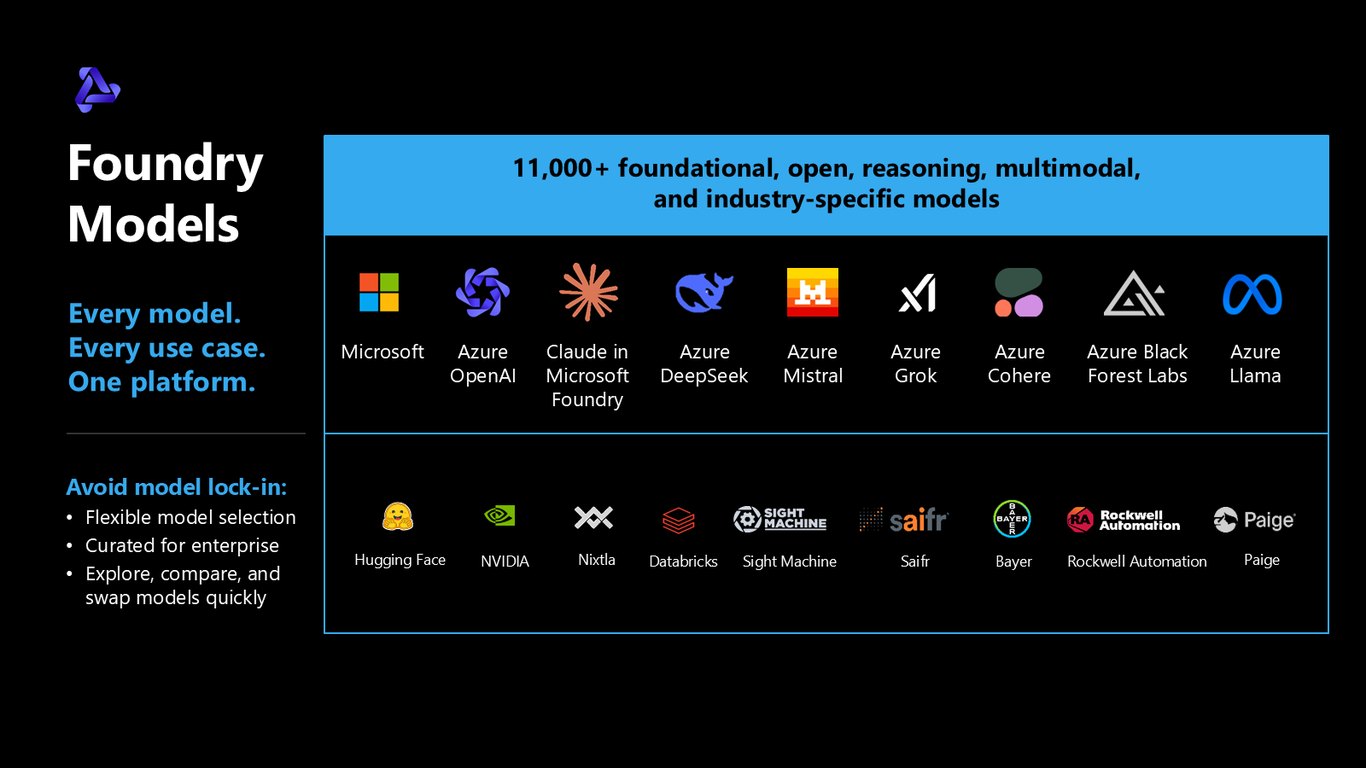
모든 모델, 모든 유스케이스, 하나의 플랫폼
Foundry Models에는 파운데이션, 오픈, 추론, 멀티모달, 산업 특화까지 11,000개 이상의 모델이 있습니다. Azure OpenAI, Claude, DeepSeek, Mistral, Llama, Hugging Face까지요. 모델 종속을 피하고, 자유롭게 탐색하고 비교하고 빠르게 갈아끼울 수 있다는 게 핵심입니다.

모델을 골랐으면 다음은 평가입니다. 개선 루프에서 가장 중요한 단계죠.

평가가 곧 제품 명세서
개선 루프에서 평가는 사실상 제품 명세서입니다. 무엇이 '좋음'인지, 어떤 트레이드오프가 중요한지, 시스템을 바꿀 때마다 무엇을 측정할지를 정의하거든요. 정확성, 정책 준수, 툴 호출 유효성, 에스컬레이션 정확도, 안전과 프라이버시까지 시나리오별 평가 계약으로 묶는 겁니다.
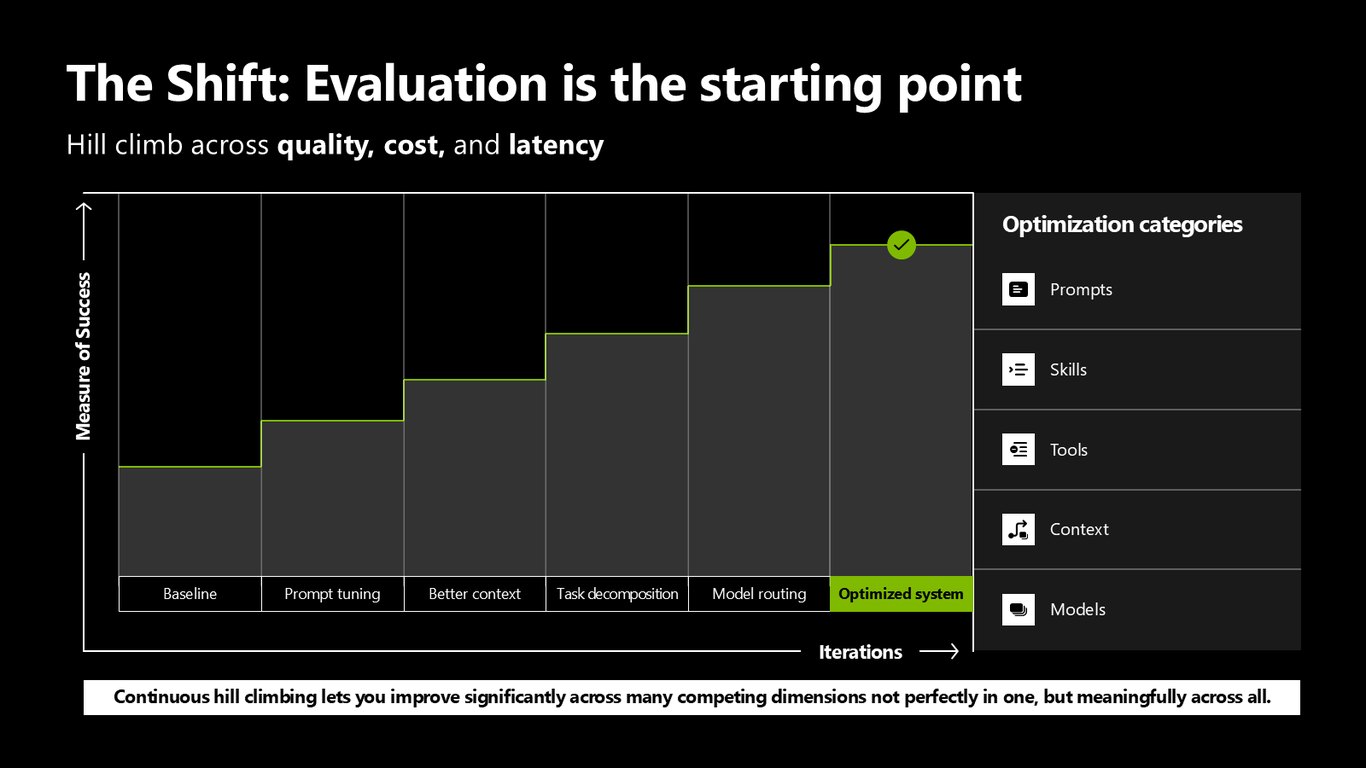
평가는 출발점입니다
발상을 바꿔야 합니다. 평가는 마지막이 아니라 출발점이에요. 베이스라인에서 시작해 프롬프트 튜닝, 더 나은 컨텍스트, 작업 분해, 모델 라우팅으로 품질·비용·지연을 함께 밀어 올립니다. 한 축에서 완벽해지는 게 아니라, 여러 경쟁하는 축에서 의미 있게 나아지는 거죠.
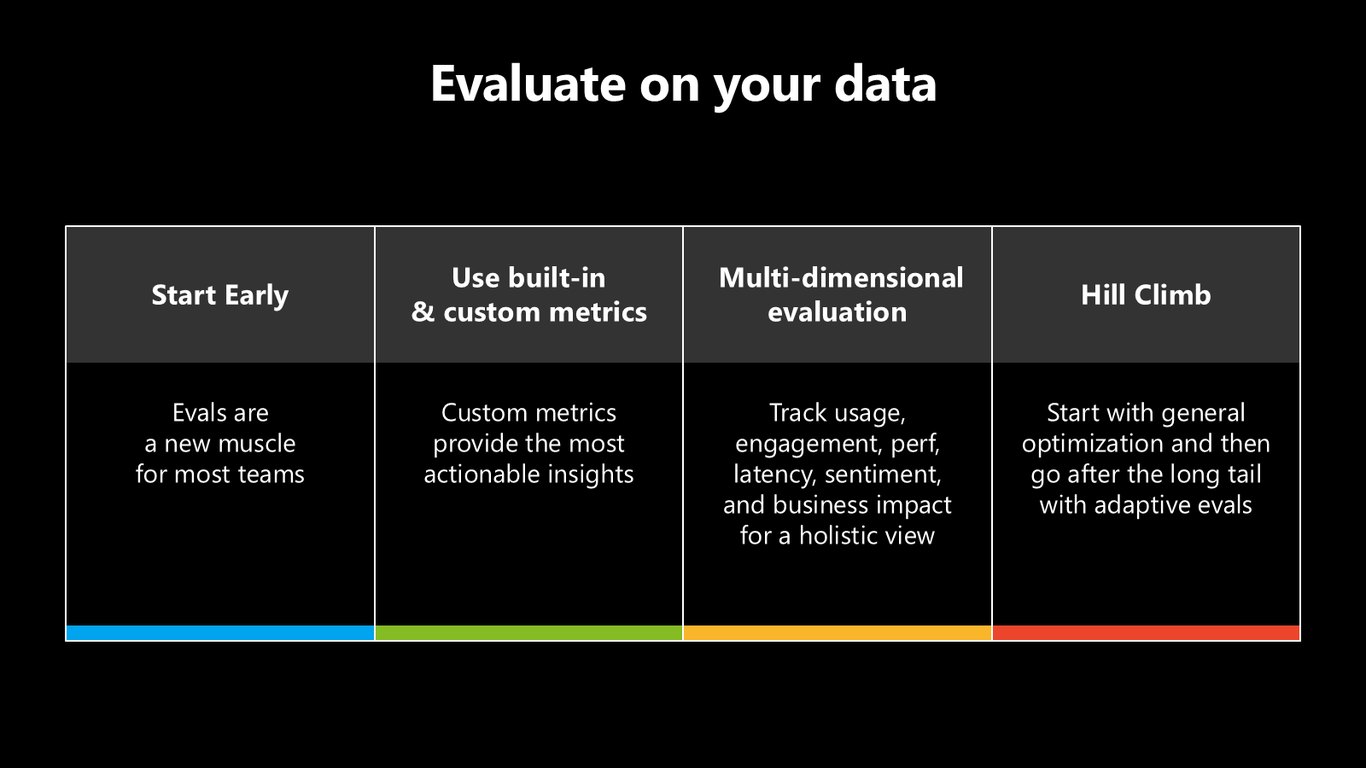
여러분의 데이터로 평가하세요
평가는 반드시 여러분의 데이터로, 그리고 일찍 시작하셔야 합니다. 내장 지표에 커스텀 지표를 더해 다차원으로 보시고요. 사용량, 참여도, 성능, 지연, 감성, 비즈니스 임팩트까지 종합적으로 추적하세요. 대부분 팀에게 평가는 새로 길러야 할 근육입니다.
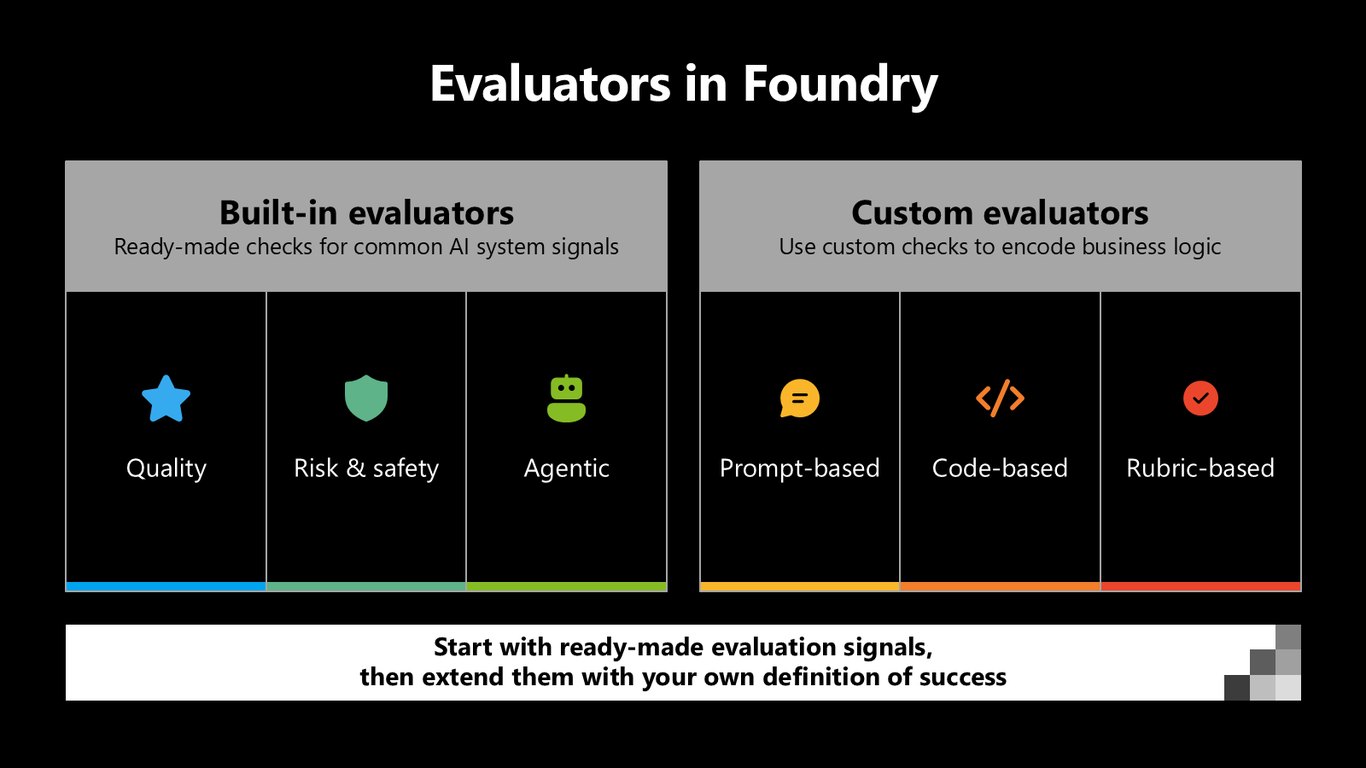
Foundry의 평가기
Foundry에는 품질, 리스크·안전, 에이전트 신호를 바로 확인하는 내장 평가기가 있고요. 프롬프트 기반, 코드 기반, 루브릭 기반으로 여러분의 비즈니스 로직을 담는 커스텀 평가기도 만들 수 있습니다. 기성 신호로 시작해서, 여러분만의 성공 정의로 확장해 나가시면 됩니다.

이제 세 번째 단계, 최적화로 넘어가겠습니다. 여기서 진짜 재미있는 후처리 학습 이야기가 나옵니다.
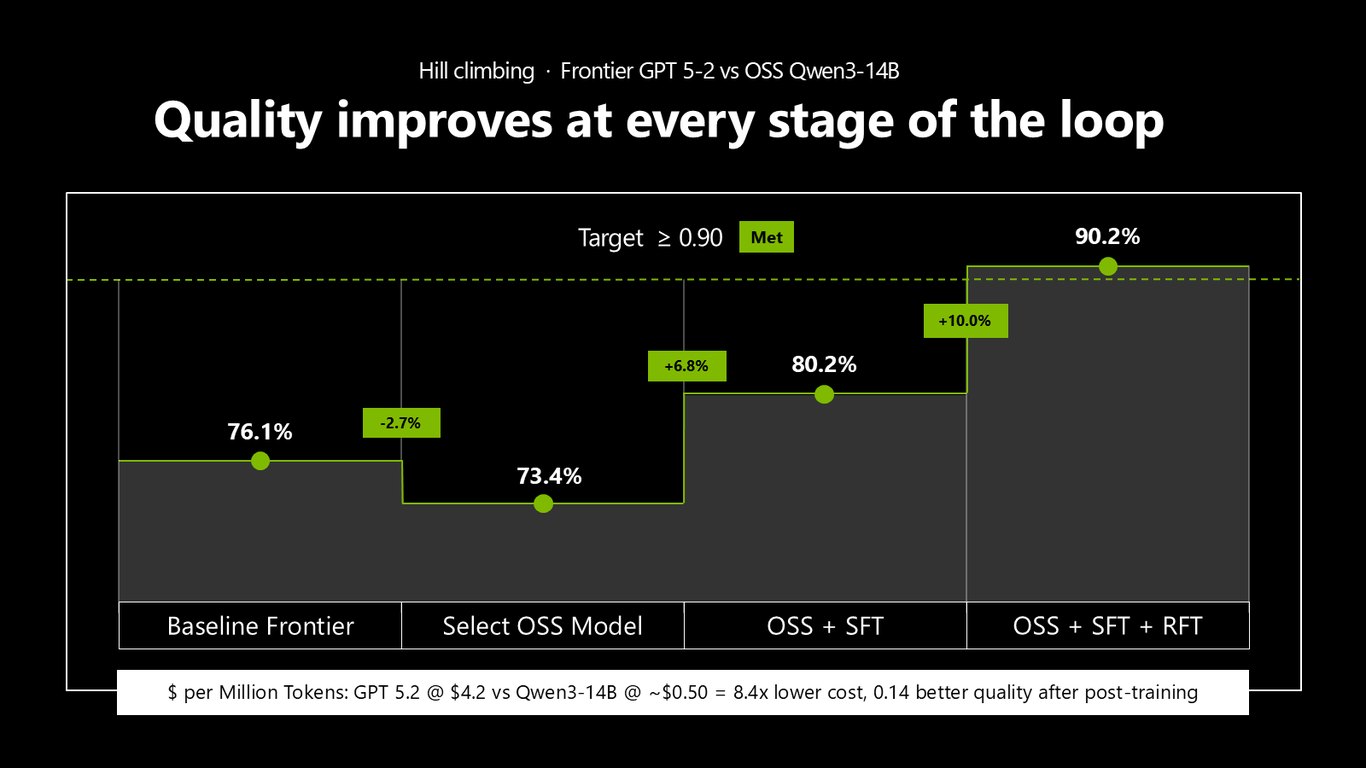
단계마다 품질이 오릅니다
힐 클라이밍의 실제 숫자를 보시죠. 프론티어 GPT 5-2 대비 OSS Qwen3-14B로 시작하면 처음엔 조금 낮지만, SFT를 더하고 RFT까지 얹으면 품질이 목표치 0.90을 넘깁니다. 그러면서 토큰당 비용은 8.4배 저렴하죠. 후처리 학습만으로 더 싸고 더 좋은 지점을 잡는 겁니다.

말로만 하면 아쉬우니까, 후처리 학습을 실제로 어떻게 하는지 데모로 직접 보여드리겠습니다.
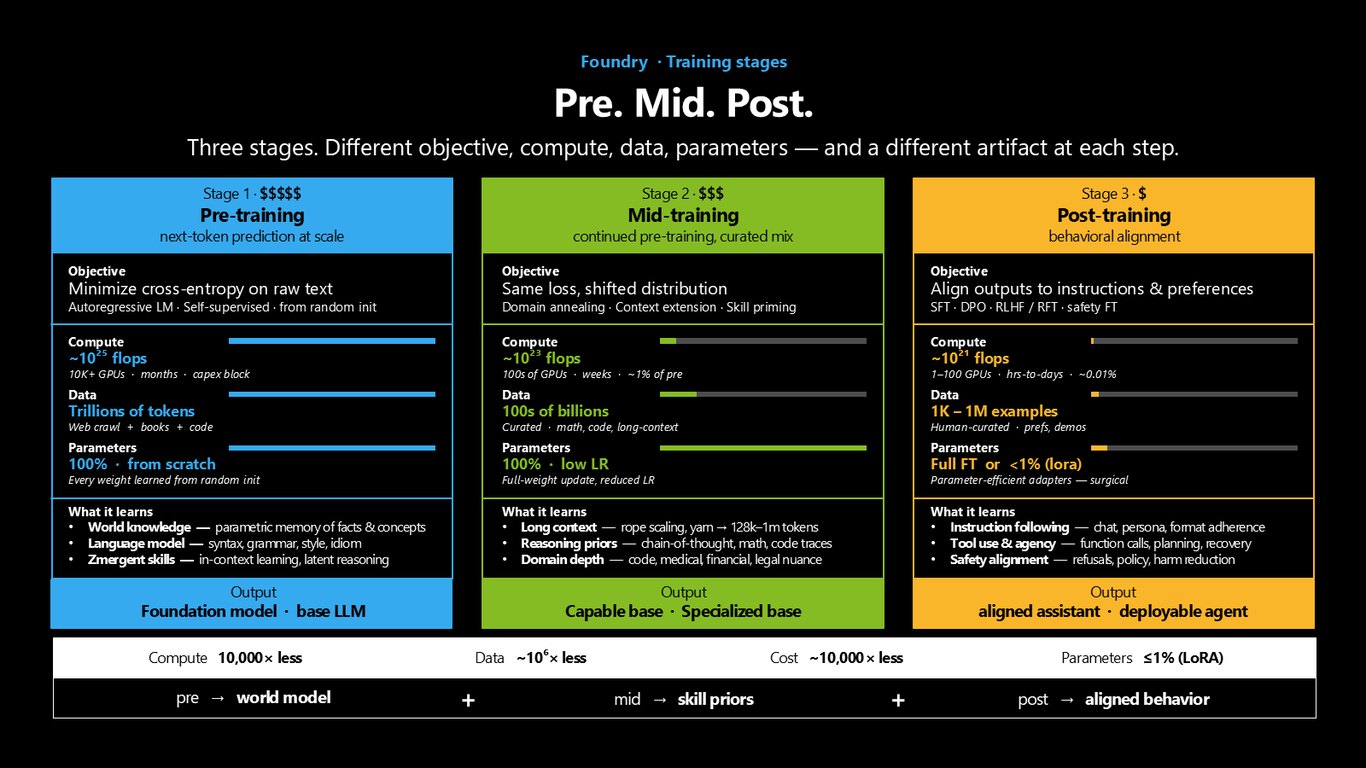
Pre · Mid · Post, 세 단계
학습에는 세 단계가 있습니다. 목적도, 연산량도, 데이터도, 만들어지는 산출물도 다 다릅니다. Pre-training은 방대한 텍스트로 다음 토큰을 예측하며 세상 지식과 언어를 통째로 배우는, 수천만 GPU 시간과 자본이 드는 단계고요. 우리가 오늘 집중할 곳은 그다음, 후처리 단계입니다.

후처리 학습이 모든 걸 형성합니다
프리트레이닝 이후의 거의 모든 것, 그러니까 지시 따르기, 안전, 도메인 지식, 에이전트 신뢰성은 후처리 학습이 형성합니다. 증류, 에이전트 궤적 SFT, 합성 데이터, 인간 선호 DPO·RLHF, 검증 가능한 보상 RFT까지 데이터를 어떻게 섞느냐가 관건인데요. 실제로 학습 시간의 약 80%가 데이터 준비에 들어갑니다.
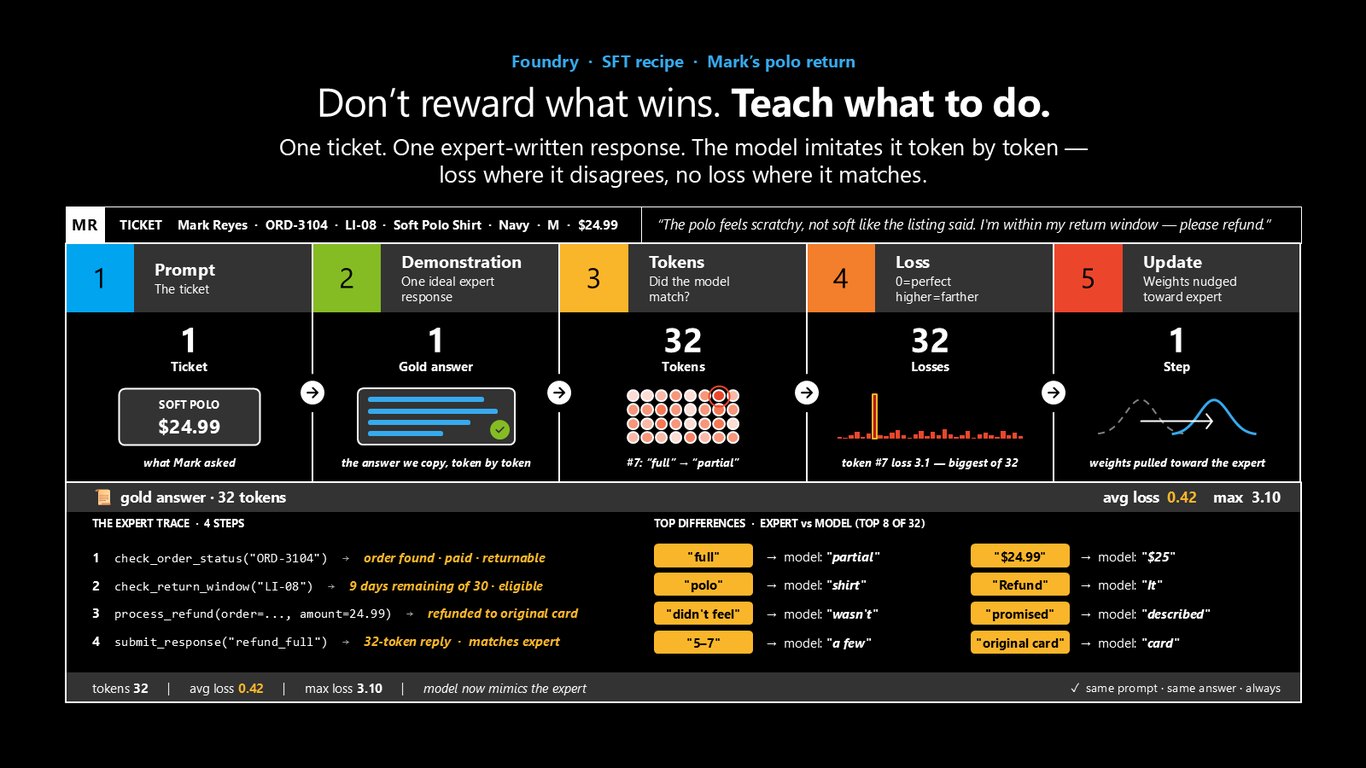
SFT · 이길 걸 보상하지 말고, 할 걸 가르쳐라
먼저 SFT입니다. Mark의 폴로셔츠 환불 티켓 하나에, 전문가가 쓴 이상적인 답변 하나를 두고, 모델이 그걸 토큰 단위로 그대로 모방하게 합니다. 틀린 토큰에는 손실을 주고 맞은 토큰엔 안 주는 거죠. '이길 걸 보상'하는 게 아니라, '무엇을 해야 하는지'를 직접 가르치는 방식입니다.

RFT · 할 걸 가르치지 말고, 이길 걸 보상하라
반대로 RFT는 같은 티켓에 에이전트가 32가지 방법을 시도하게 하고, 코드가 각각을 채점합니다. 이긴 시도가 다음 버전을 만들죠. 예를 들어 21번째 시도가 0.87점, 평균보다 0.25 높으면 그 방향으로 정책을 업데이트합니다. 이번엔 '무엇을 하라'가 아니라 '이긴 걸 보상'하는 겁니다.
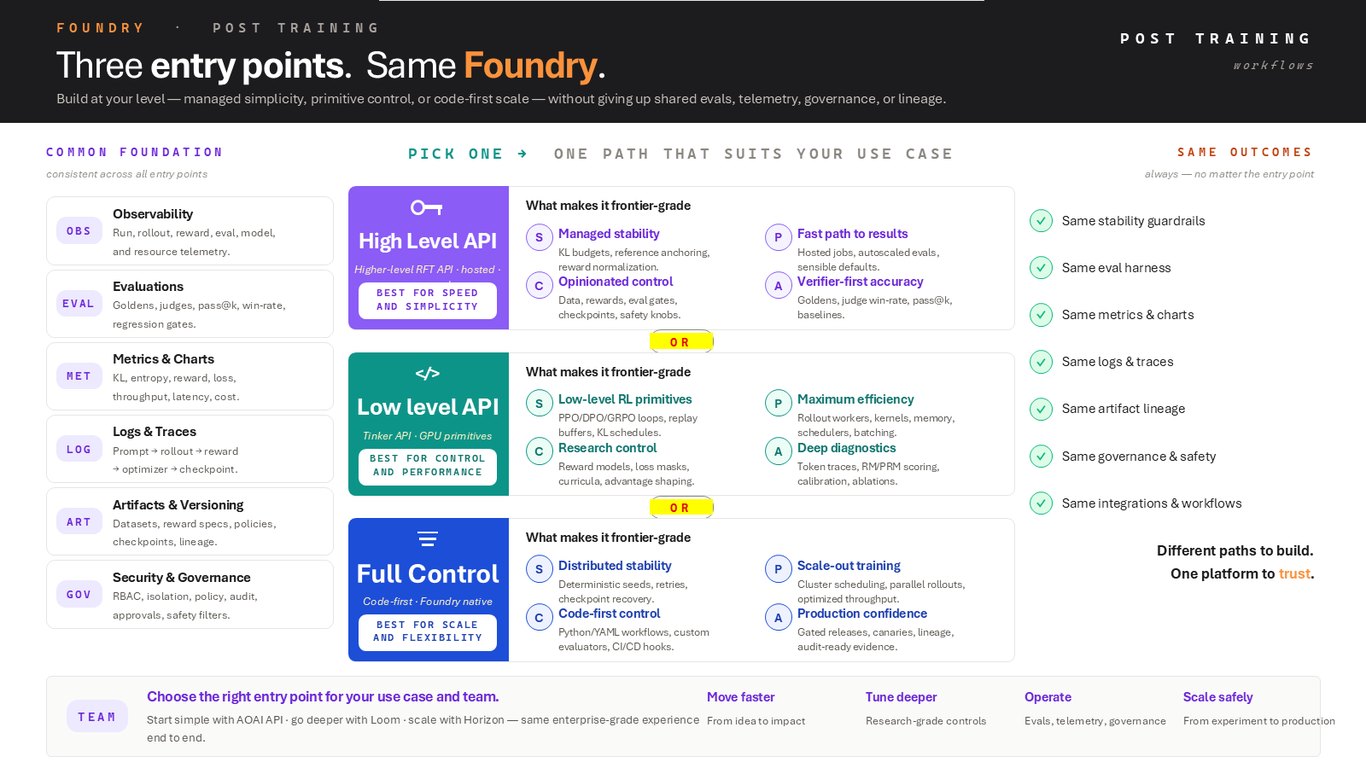
진입점은 셋, Foundry는 하나
후처리 학습에 들어오는 방식은 세 가지입니다. 관리형 단순함, 프리미티브 수준의 제어, 코드 우선의 확장. 어느 쪽으로 들어오든 관측성, 평가, 지표, 로그와 트레이스, 아티팩트 버전 관리, 보안·거버넌스라는 공통 기반은 똑같이 공유합니다.

Foundry에 Fireworks AI, 그리고 Managed Compute
여기서 발표를 하나 드립니다. Microsoft Foundry에 Fireworks AI와 Managed Compute가 들어옵니다. 오픈 모델을 위한 새로운 실행 경로인데요. Hugging Face, NVIDIA, Microsoft Research의 수천 개 모델을 vLLM, SGLang, NVIDIA NIM 같은 최적화 런타임으로 돌릴 수 있습니다. 엔드포인트도, 인증도, SDK도 그대로고요.

어디서든 학습하고, Foundry에서 배포·확장
커스텀 모델을 어디서 학습했든 Foundry에서 배포하고 확장할 수 있습니다. 가중치를 올리는 BYOW로 업로드·등록·Hugging Face 임포트가 되고요. 컨테이너까지 가져오는 BYOC도 지원합니다. 그리고 배포는 Foundry 관리형 컴퓨트, 여러분의 Azure VM 클러스터, 또는 Fireworks PTU 중에 워크로드별로 고르시면 됩니다.

Foundry로 계속 개선하기
정리하면 다섯 단계입니다. 워크로드에 맞는 모델을 고르고, 여러분 데이터로 평가하고, 강화학습으로 최적화하고, Managed Compute나 Fireworks로 통제하며 운영하고, 다시 평가를 돌려 근거로 판단해 업그레이드를 내보내는 겁니다. 프론티어 모델은 종착점이 아니라 출발점이에요.
오늘 밤부터 에이전트를 튜닝하세요
어렵게 생각하지 마시고, 바로 오늘 밤부터 여러분의 에이전트를 튜닝해 보세요. 정말 감사합니다.
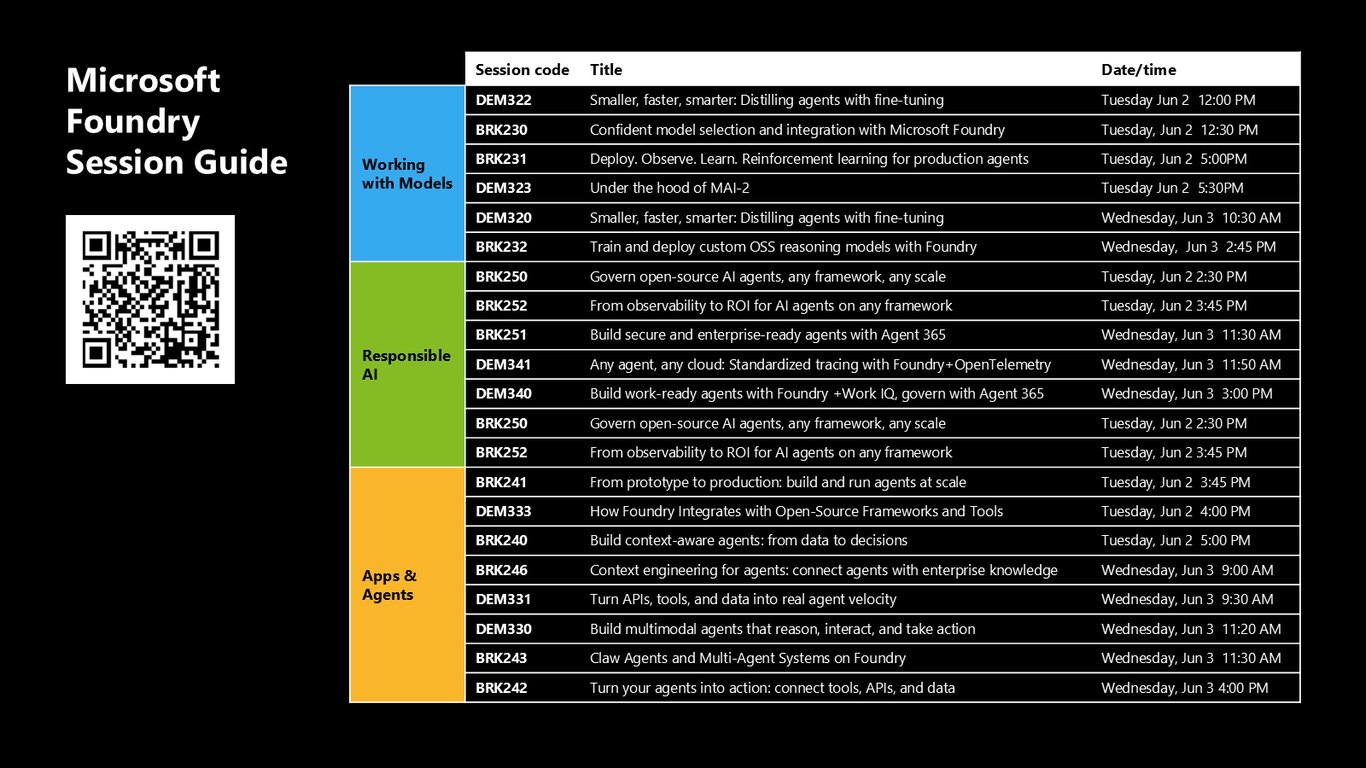
Microsoft Foundry 세션 가이드
Foundry를 더 깊이 파고 싶으시면 관련 세션들을 참고하세요. 모델 선택의 BRK230, 프로덕션 에이전트 강화학습의 BRK231, 파인튜닝 증류의 DEM322·DEM320, 그리고 오픈소스 AI 거버넌스의 BRK250까지 이어서 들으시면 좋습니다.

감사합니다
감사합니다.

세션 페이지에서 이어가기
세션 상세 페이지에 튜토리얼과 리소스, 코드가 준비돼 있으니 꼭 활용해 보세요. aka.ms/build/evals에 방문하시거나 QR 코드를 스캔해서 설문도 남겨 주시면 감사하겠습니다.

마무리
오늘 함께해 주셔서 다시 한번 감사드립니다. 오픈소스 추론 모델, 이제 여러분의 손으로 직접 다듬어 보시죠.