
오늘은 모든 Windows PC에서 무제한으로 쓸 수 있는 로컬 AI로 앱을 만드는 방법을 이야기해 보겠습니다. 클라우드에 의존하지 않고 기기 위에서 바로 지능을 돌리는 이야기입니다.

발표자 소개
저는 Windows ML 담당 PM Anastasiya Tarnouskaya이고, 함께하는 Aditi Narvekar는 Windows AI APIs를 맡고 있습니다. 오늘 두 사람이 번갈아 가며 로컬 AI의 전체 그림을 보여드리겠습니다.

모든 PC 위의 무제한 지능
이미 5억 대가 넘는 PC에서 로컬 AI 워크로드가 돌아가고 있습니다. Microsoft Foundry on Windows는 성능을 최대로 끌어내면서 도달 범위까지 넓혀, AI 우선 시대에 효율적으로 지능을 배포하게 해 줍니다.

Foundry on Windows 영상
먼저 짧은 영상으로 Microsoft Foundry on Windows가 무엇을 할 수 있는지 감을 잡아 보시죠.

로컬 AI가 필요한 이유
왜 굳이 로컬 AI일까요? 데이터가 기기를 떠나지 않으니 프라이버시와 보안에 강하고, 지연이 낮고, 네트워크 없이도 동작하며, 비용까지 아낄 수 있습니다.
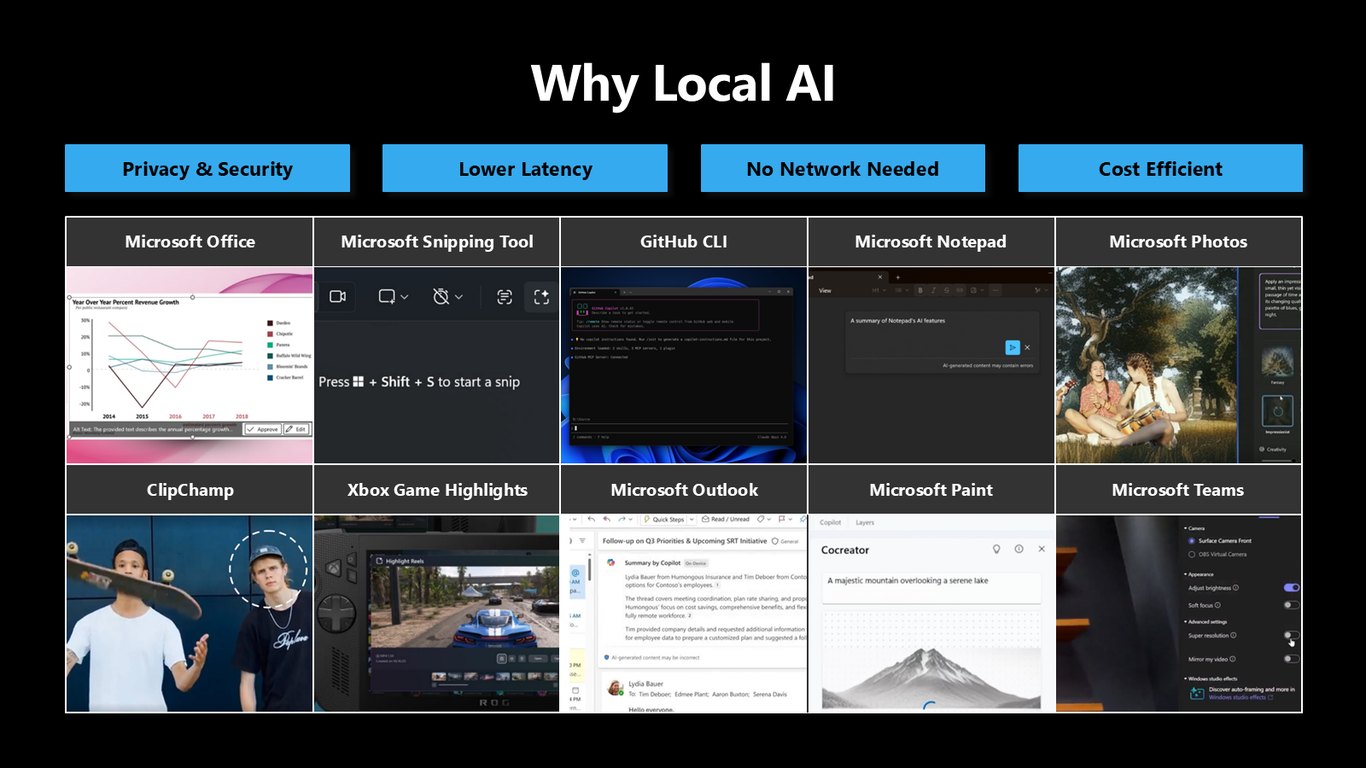
로컬 AI의 네 가지 가치
이 네 가지, 즉 프라이버시와 보안, 낮은 지연, 오프라인 동작, 비용 효율이 바로 우리가 로컬로 가야 하는 이유입니다. 이걸 실제로 가능하게 해 주는 게 다음에 소개할 Foundry on Windows입니다.
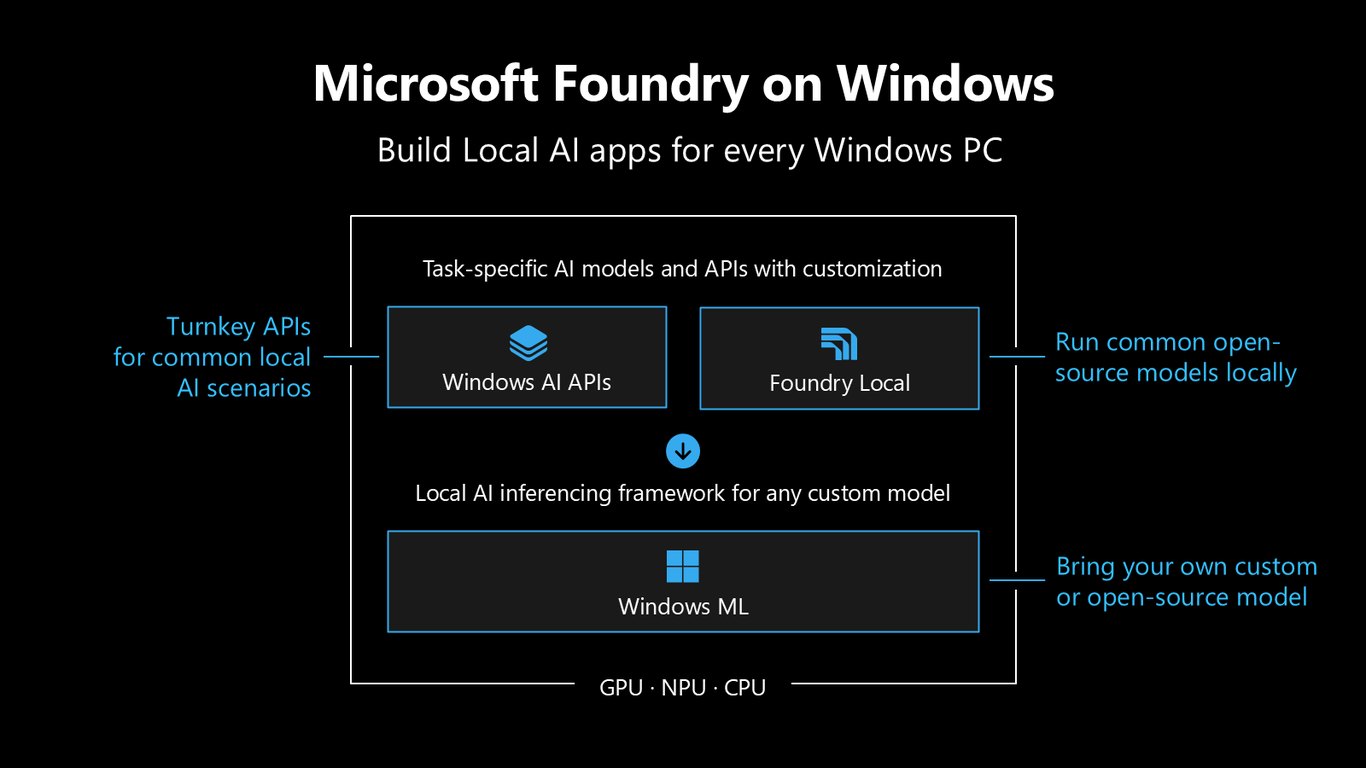
Microsoft Foundry on Windows
Foundry on Windows는 세 개의 층으로 이뤄져 있습니다. 바로 쓰는 Windows AI APIs, 오픈소스 모델을 로컬로 돌리는 Foundry Local, 그리고 내 커스텀 모델을 위한 추론 프레임워크 Windows ML입니다. 이 셋이 모두 GPU·NPU·CPU 위에서 동작합니다.

Unmetered Token Café
오늘 발표 내내 함께할 예시로 'Unmetered Token Café'를 소개합니다. 고객 주문, 마케팅 콘텐츠, 재고 관리, 커뮤니티 이벤트, 실험적인 신메뉴까지 — 이 카페의 모든 기능을 로컬 AI로 구현하면서 세 개 층을 하나씩 보여드리겠습니다.

이제 첫 번째 층, Windows AI APIs부터 살펴보겠습니다. 가장 빠르게 로컬 AI를 앱에 넣는 방법입니다.
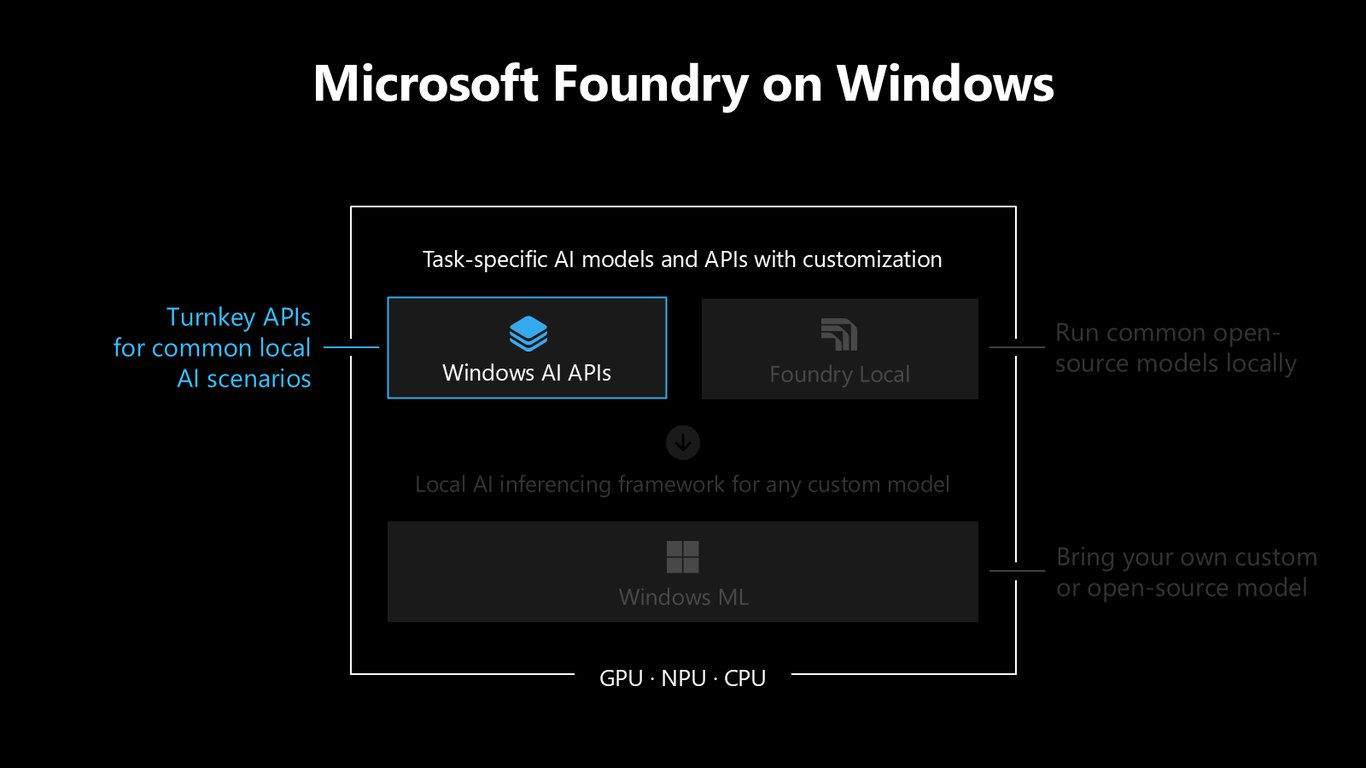
바로 쓰는 턴키 API
Windows AI APIs는 흔한 로컬 AI 시나리오를 위한 턴키 API를 제공합니다. 모델을 직접 준비할 필요 없이, 함수 하나 부르듯 요약이나 음성 인식 같은 기능을 바로 앱에 넣을 수 있습니다.

데모: 음성 인식 API
먼저 Qualcomm Snapdragon이 들어간 Surface Pro에서 음성 인식 API를 시연해 보겠습니다. 카페에서 고객 주문을 받아 적는 장면을 떠올리시면 됩니다.

NPU 활용
이 작업은 NPU 위에서 돌아갑니다. 전용 가속기가 있으니 CPU를 붙잡지 않고도 효율적으로 처리할 수 있죠.

NPU와 CPU
NPU가 없거나 부족할 때는 CPU로도 자연스럽게 넘어갑니다. 기기마다 가진 하드웨어에 맞춰 알아서 최적의 조합을 씁니다.

NPU·CPU·GPU 전체 활용
결국 NPU, CPU, GPU까지 세 종류의 프로세서를 모두 활용할 수 있습니다. 어떤 Windows PC에 배포하든 그 기기의 성능을 최대한 끌어내는 겁니다.

데모: GPU 위의 Phi Silica
이번엔 NVIDIA GeForce RTX 5090이 탑재된 Razer Blade 18에서, Phi Silica를 GPU 위에서 돌려 보겠습니다.
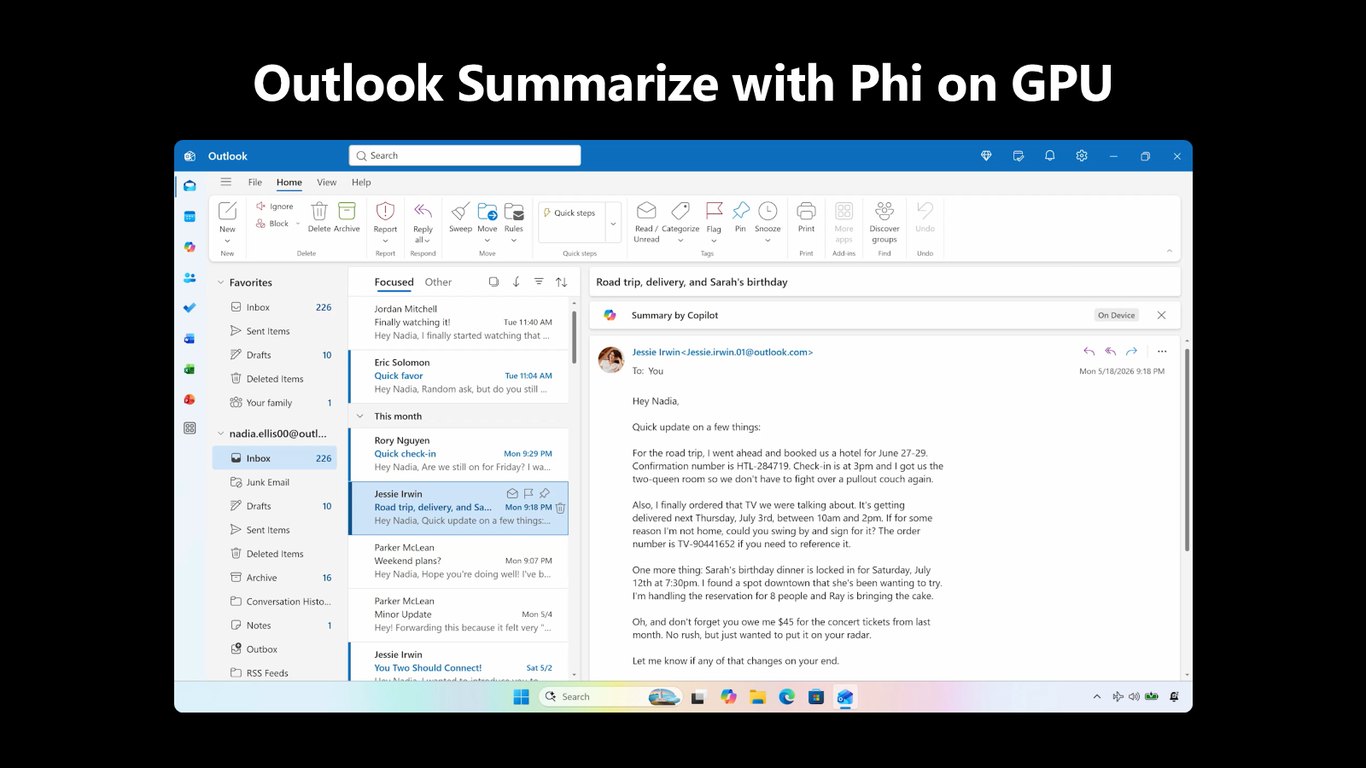
Outlook 요약 데모
영상으로 보시는 건 GPU 위의 Phi로 Outlook 메일을 요약하는 모습입니다. 강력한 GPU를 갖춘 기기에서는 이렇게 더 큰 작업도 순식간에 처리됩니다.
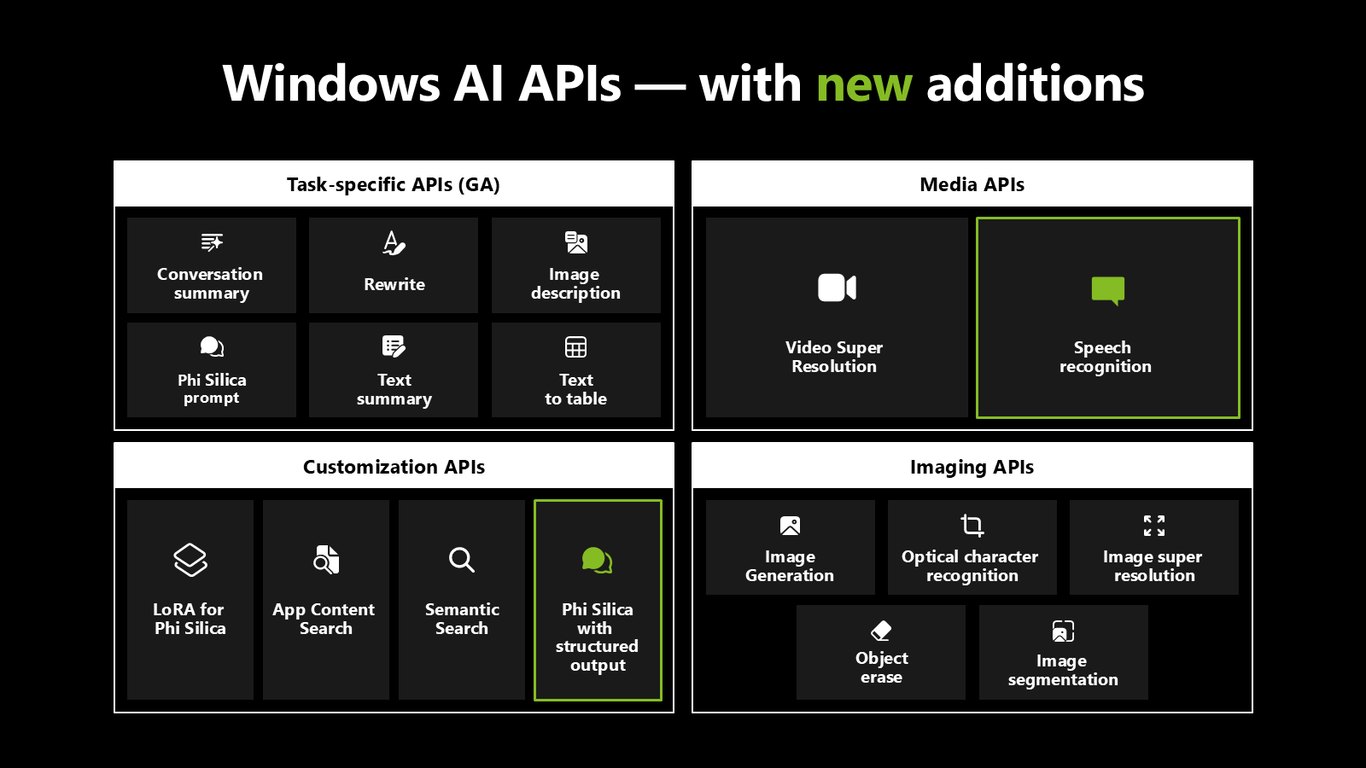
새로 늘어난 Windows AI APIs
Windows AI APIs는 계속 확장되고 있습니다. 대화 요약, 다시 쓰기, 이미지 설명 같은 정식 출시 API에 더해, LoRA 커스터마이징, 시맨틱 검색, 이미지 생성과 OCR까지 다양한 시나리오를 커버합니다.
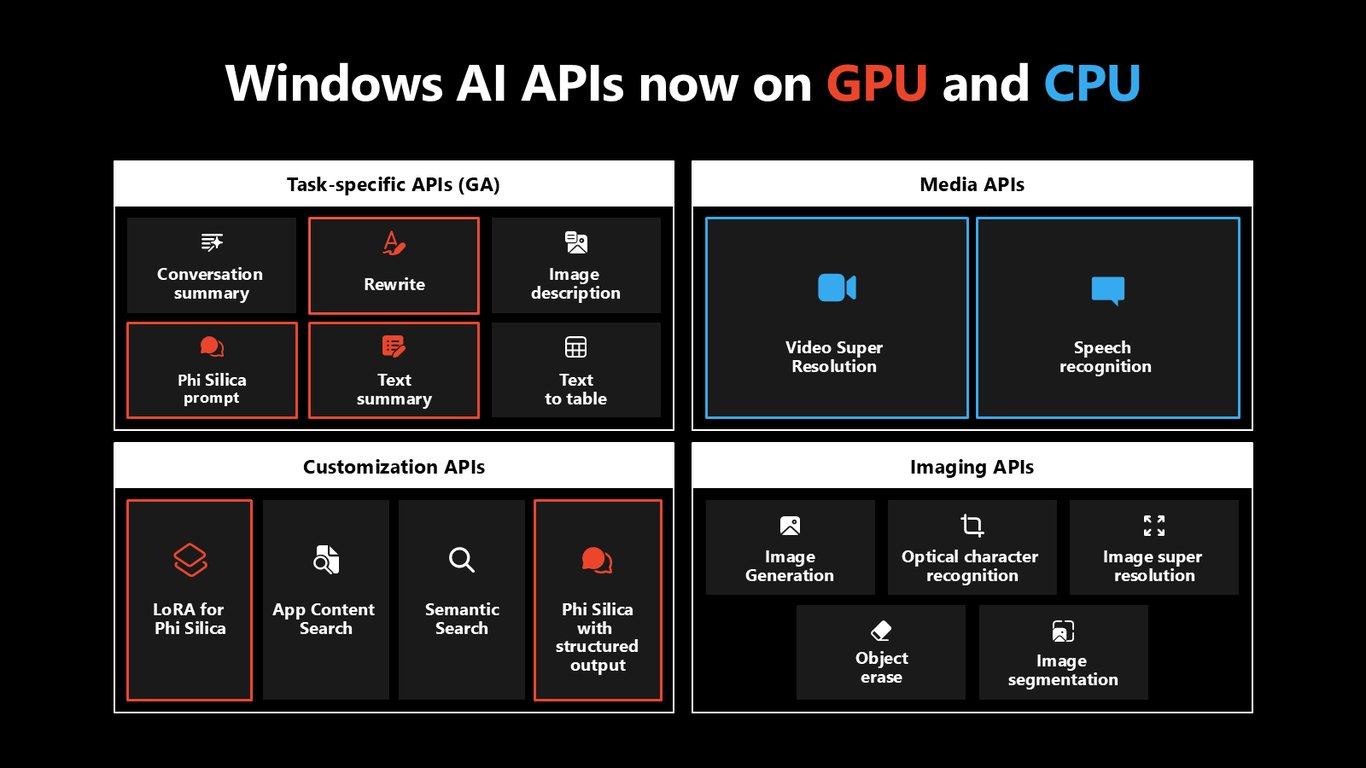
이제 GPU·CPU에서도
그리고 중요한 변화가 있습니다. 이 API들이 이제 NPU뿐 아니라 GPU와 CPU에서도 동작합니다. 덕분에 특정 하드웨어가 없는 PC에도 훨씬 넓게 도달할 수 있게 됐습니다.

데모: ClipChamp 영상 화질 개선
AMD Ryzen AI MAX+ 395 NPU가 들어간 ASUS ROG Flow Z13에서, ClipChamp의 Video Super Resolution을 시연합니다. 카페 홍보 영상을 로컬에서 또렷하게 업스케일하는 셈이죠.

데모: Aion으로 Prompt API
Intel이 들어간 Surface Laptop for Business에서 Edge의 Prompt API를 Aion으로 써 봅니다. 궁금하시면 aka.ms/TryAion에서 직접 체험해 보실 수 있습니다.

이제 두 번째 층, Foundry Local로 넘어가겠습니다. 인기 있는 오픈소스 모델을 로컬에서 그대로 돌리고 싶을 때 쓰는 방법입니다.
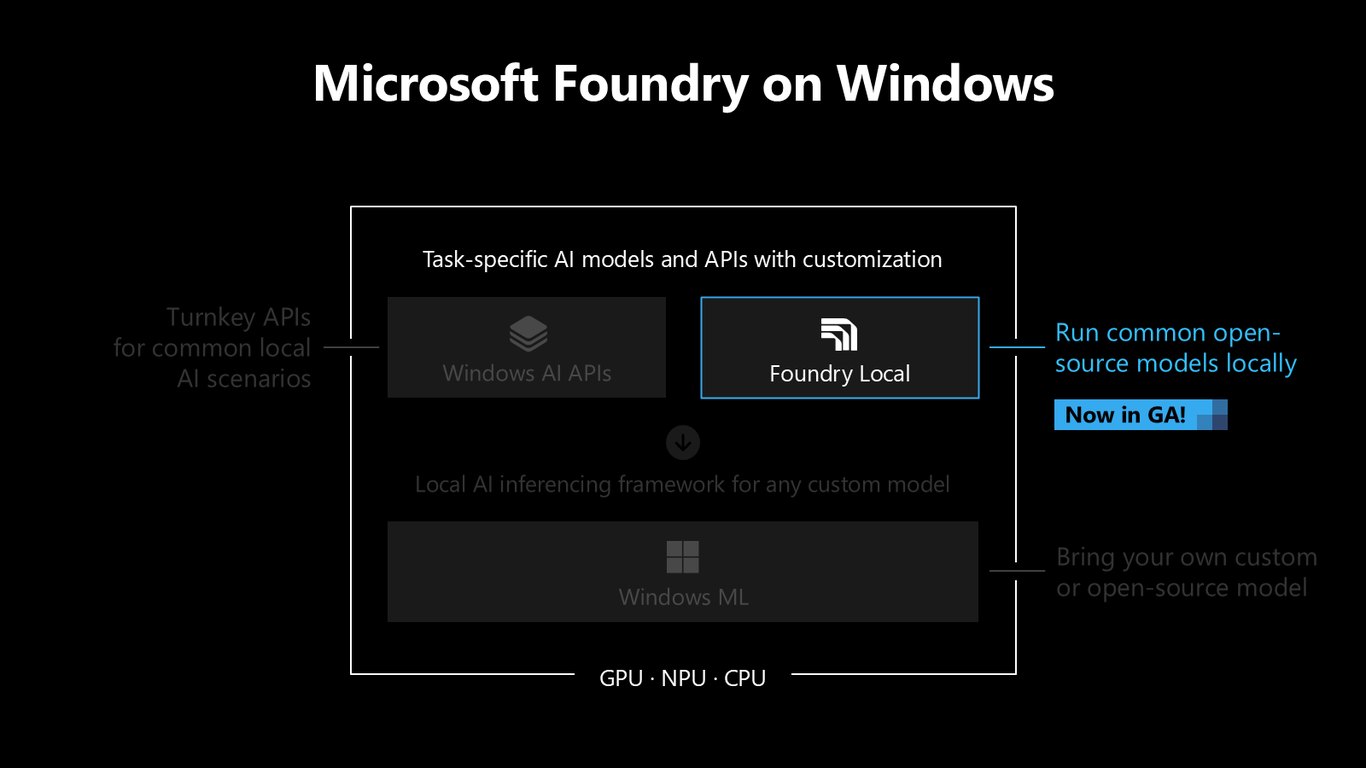
오픈소스 모델을 로컬로
Foundry Local은 검증된 오픈소스 모델들을 미리 최적화된 형태로 제공해, 내려받아 바로 로컬에서 실행하게 해 줍니다. 턴키 API보다 한 단계 더 유연하게 원하는 모델을 고를 수 있죠.

Foundry Local SDK 데모
Blackwell 아키텍처의 RTX 5090이 탑재된 Razer Blade 18에서 Foundry Local SDK를 시연해 보겠습니다. 코드 몇 줄로 모델을 불러와 추론하는 모습을 보실 수 있습니다.
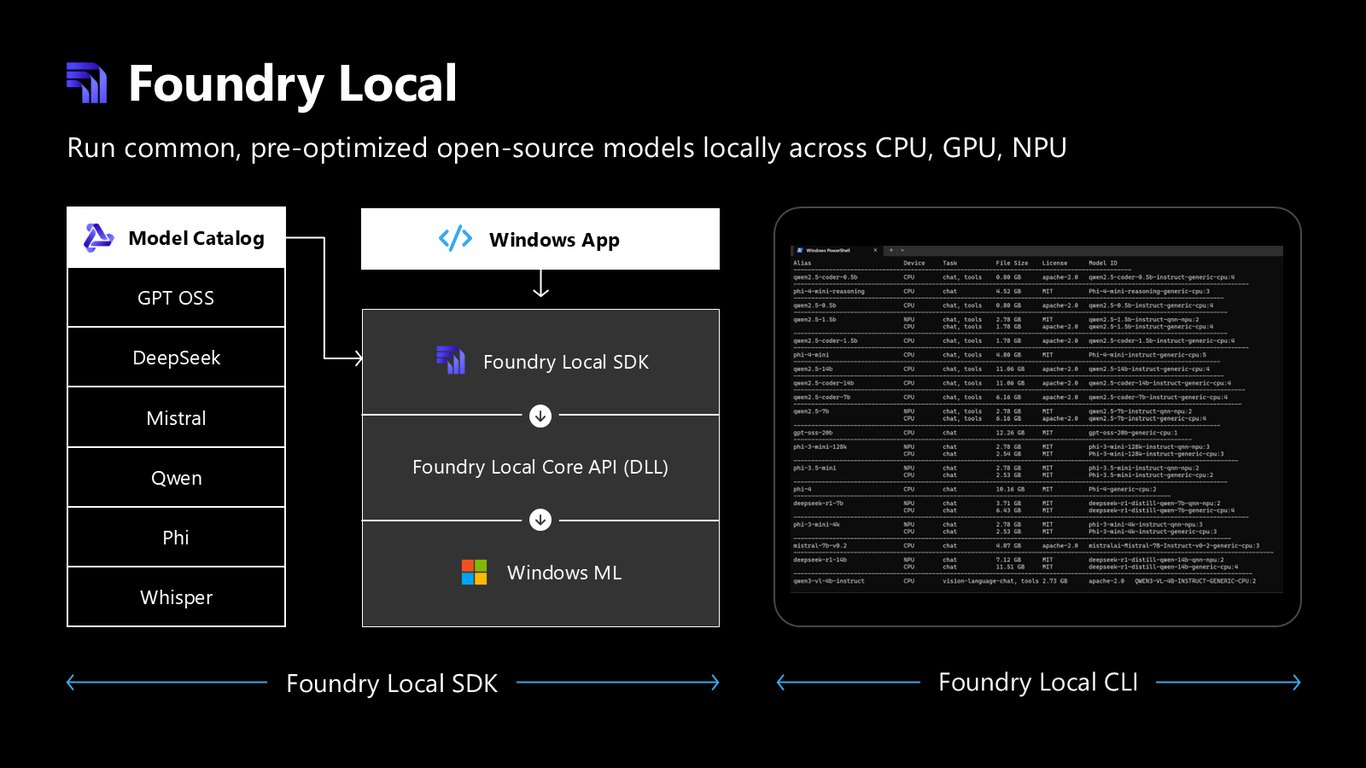
모델 카탈로그와 SDK
GPT OSS, DeepSeek, Mistral, Qwen, Phi, Whisper 같은 모델을 카탈로그에서 골라 CPU·GPU·NPU 어디서든 돌릴 수 있습니다. Foundry Local SDK와 CLI, Core API를 통해 앱에 손쉽게 붙입니다.

마지막 세 번째 층은 Windows ML입니다. 남이 만든 모델이 아니라 내가 직접 만든 커스텀 모델을 돌려야 할 때 바로 이 층이 필요합니다.
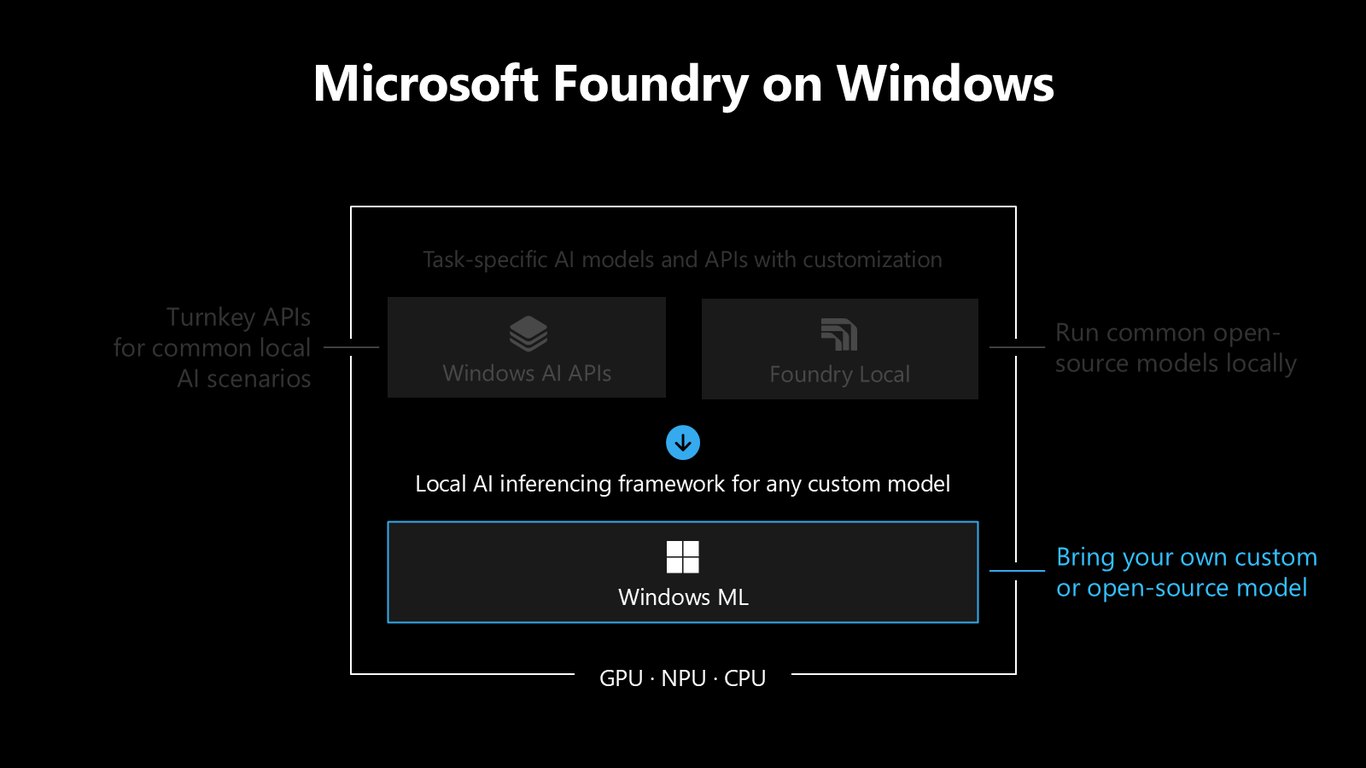
커스텀 모델을 위한 프레임워크
Windows ML은 어떤 커스텀 모델이든 받아들이는 로컬 AI 추론 프레임워크입니다. 위의 두 층이 모두 이 Windows ML 위에서 돌아간다는 점이 핵심이죠.
모든 층의 기반
다시 강조하면, Windows AI APIs도 Foundry Local도 결국 이 Windows ML을 토대로 삼습니다. 가장 밑단에서 하드웨어와 모델을 이어 주는 공통 엔진인 셈입니다.
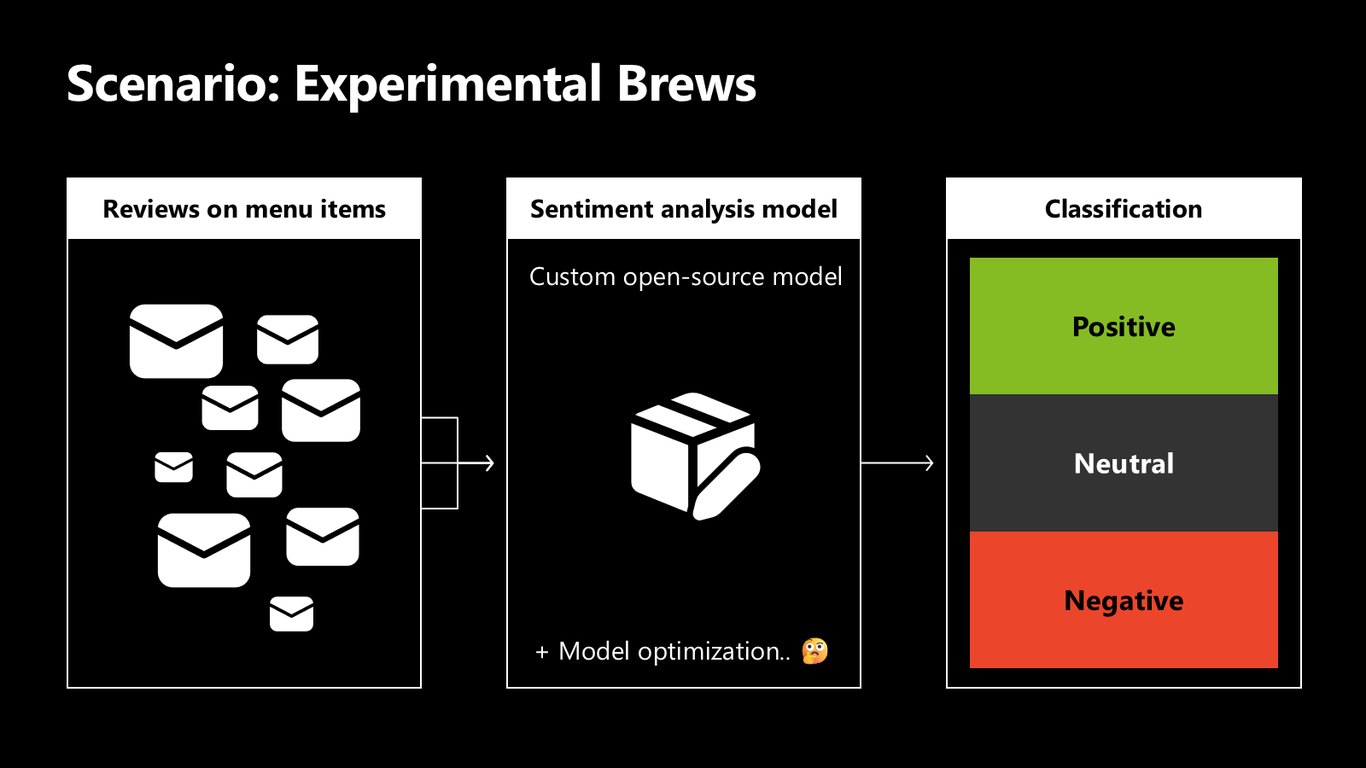
시나리오: 실험적인 신메뉴
카페 예시로 돌아와서, 메뉴 리뷰를 긍정·중립·부정으로 분류하는 감성 분석을 하고 싶다고 해 봅시다. 커스텀 오픈소스 모델을 가져오면 되는데, 여기서 '모델 최적화'라는 고민이 생깁니다.

그 고민을 풀어 주는 게 바로 Windows ML CLI입니다. 미리보기로 공개된 이 도구를 살펴보겠습니다.

모델 최적화 파이프라인
Windows ML CLI는 변환, 분석, 최적화, 양자화, 벤치마크까지 이어지는 통합 파이프라인입니다. HuggingFace의 수만 개 ONNX·PyTorch 모델이나 내가 학습한 모델을 에이전트 친화적으로 최적화해 주죠. aka.ms/winmlcli에서 지금 바로 써 보실 수 있습니다.

Windows ML CLI 데모
Intel이 들어간 Surface Laptop for Business에서 Windows ML CLI를 직접 돌려 보겠습니다. 모델을 최적화하는 과정이 얼마나 간단해지는지 보시죠.
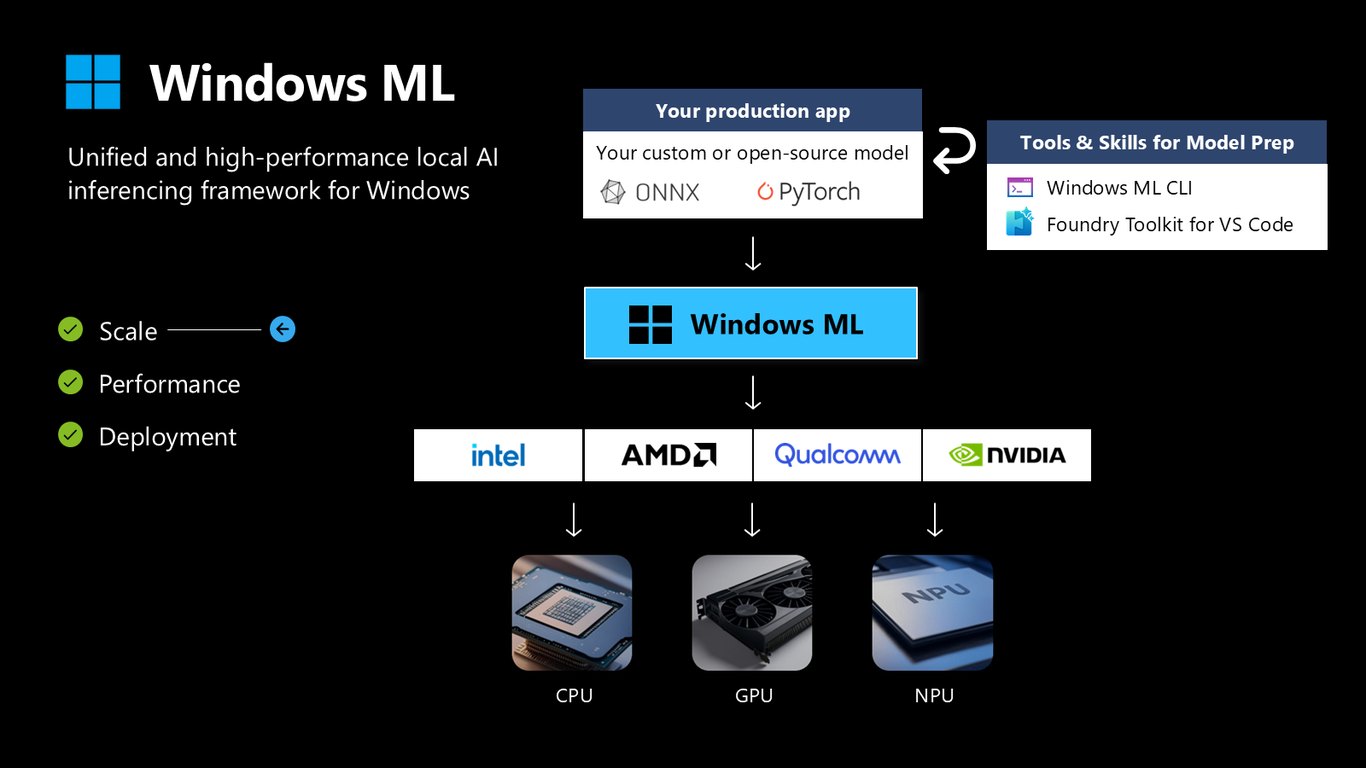
확장·성능·배포
Windows ML은 확장성, 성능, 배포 이 세 가지를 한 번에 챙깁니다. 내 프로덕션 앱과 커스텀 모델 사이에서 CPU·GPU·NPU를 통합해 주는 고성능 추론 프레임워크입니다.
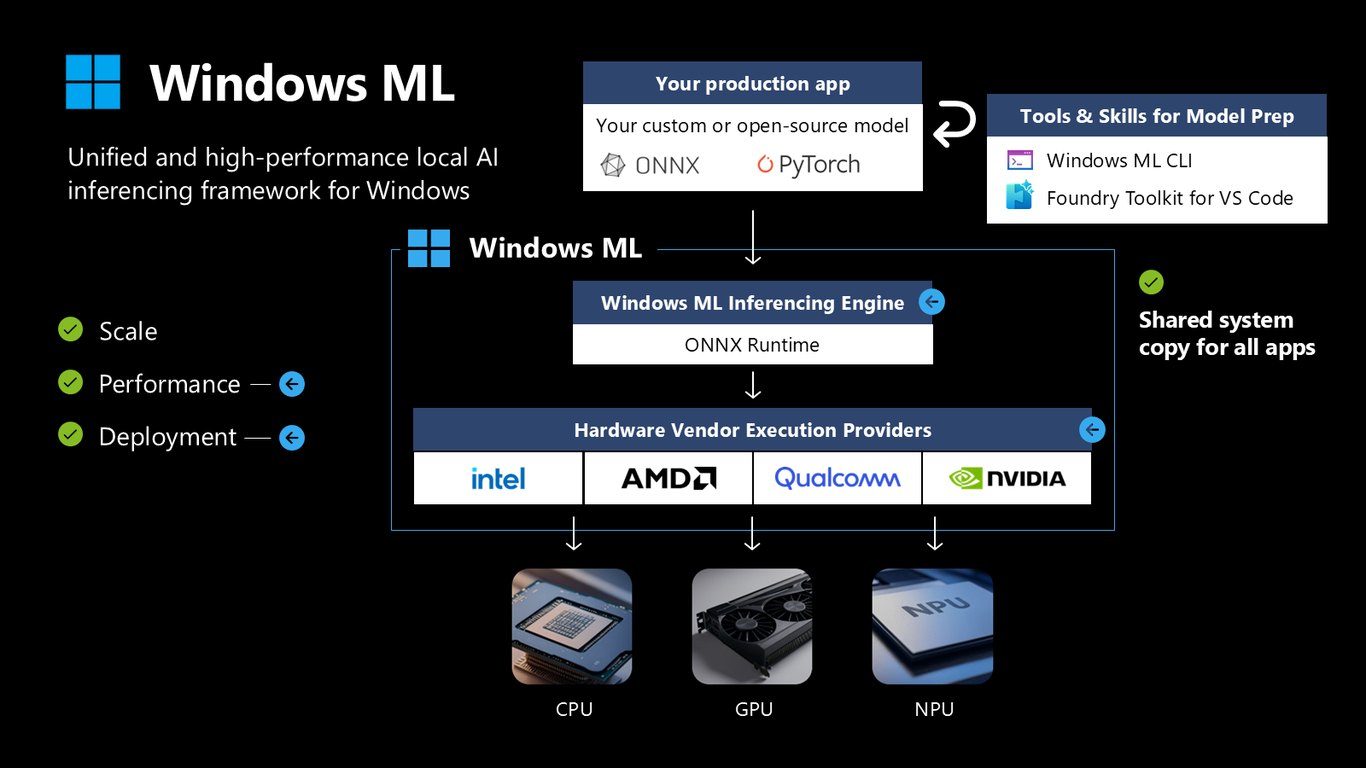
공유 엔진과 실행 공급자
내부적으로는 ONNX Runtime 기반의 추론 엔진을 시스템에 하나만 두고 모든 앱이 공유합니다. 하드웨어 벤더의 실행 공급자를 통해 각 기기에 딱 맞게 가속하는 구조죠.
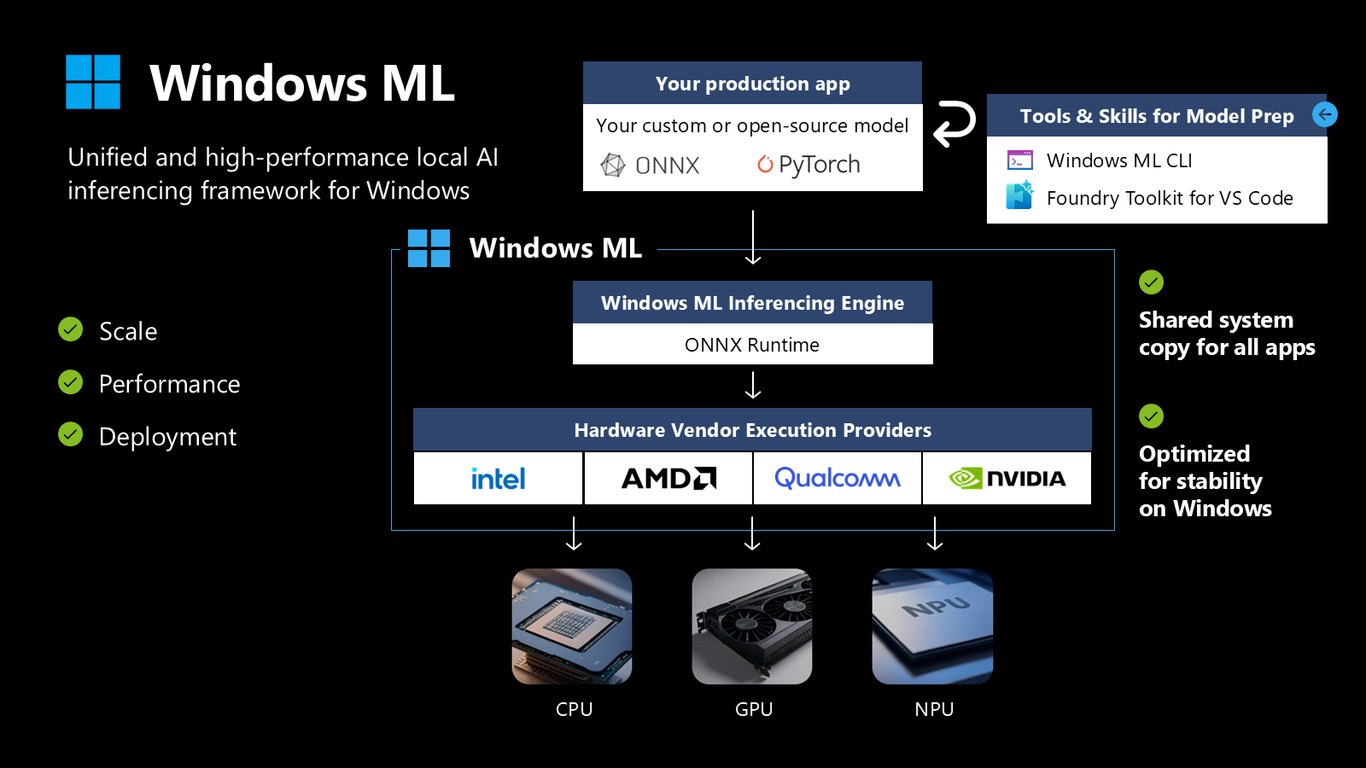
안정성 최적화
이 공유 방식은 Windows에서의 안정성에 특히 최적화돼 있습니다. 앱마다 런타임을 따로 안고 갈 필요 없이, 검증된 공통 엔진 위에서 안심하고 배포할 수 있습니다.
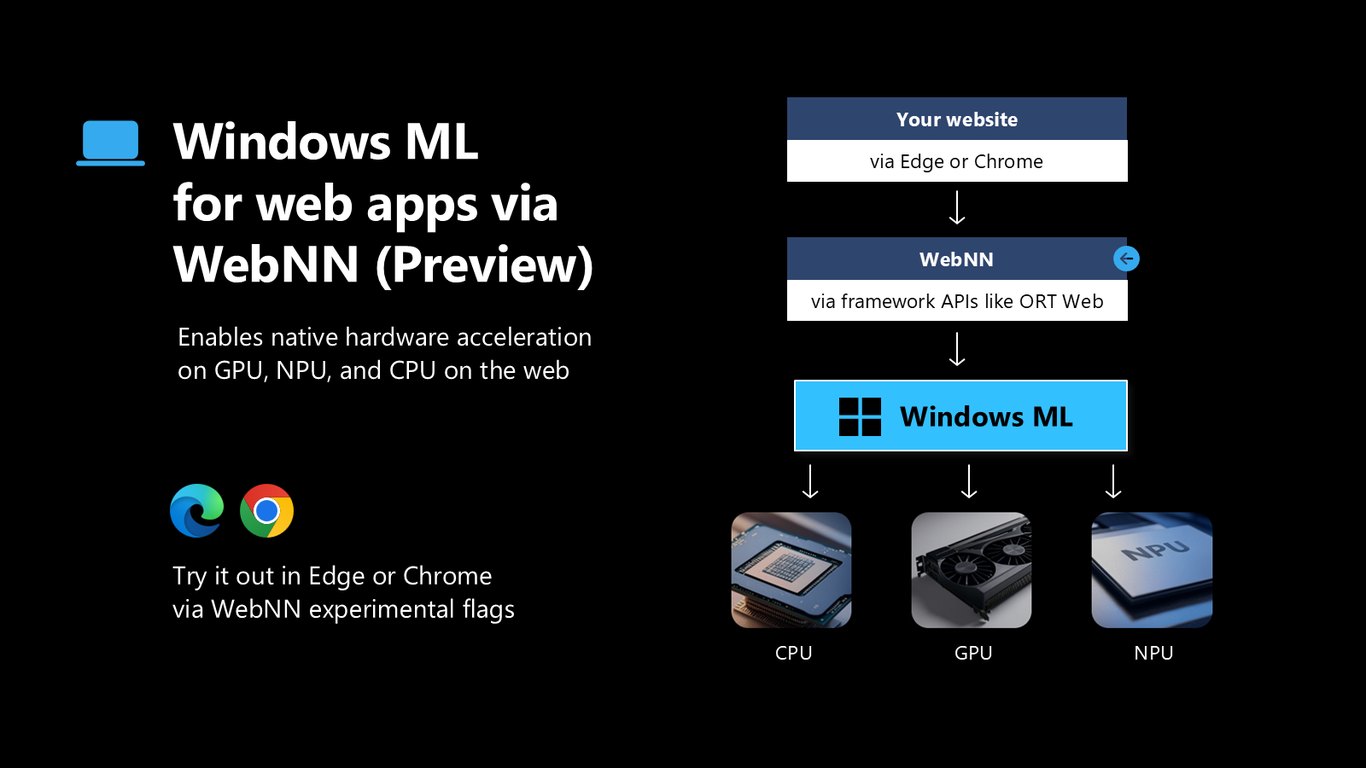
WebNN으로 웹 앱까지
미리보기지만 Windows ML은 WebNN을 통해 웹 앱에도 확장됩니다. Edge나 Chrome에서 실험 플래그를 켜면 웹사이트에서도 GPU·NPU·CPU 하드웨어 가속을 그대로 쓸 수 있습니다.

WebNN 데모
Intel이 들어간 Surface Laptop for Business에서 WebNN을 시연해 보겠습니다. 브라우저 안에서 로컬 하드웨어 가속이 동작하는 모습입니다.

데모: VoiceMod
Snapdragon NPU가 들어간 ASUS Zenbook A16에서, Windows ML 위에서 동작하는 VoiceMod를 보여드립니다. 실제 파트너 앱이 이 프레임워크를 어떻게 활용하는지 확인하실 수 있습니다.

2026년 Windows ML의 새 소식
2026년 Windows ML에는 새 소식이 많습니다. 에이전트 스킬이 추가된 WinML CLI, 최대 2.6배 향상된 CPU 처리량, Windows ML 2.0의 새 모델과 플러그인 EP, 그리고 Chromium 브라우저용 WebNN 미리보기까지 — AMD, Intel, NVIDIA, Qualcomm 전반에서 성능이 크게 좋아졌습니다.

이제 오늘 이야기를 정리해 보겠습니다.
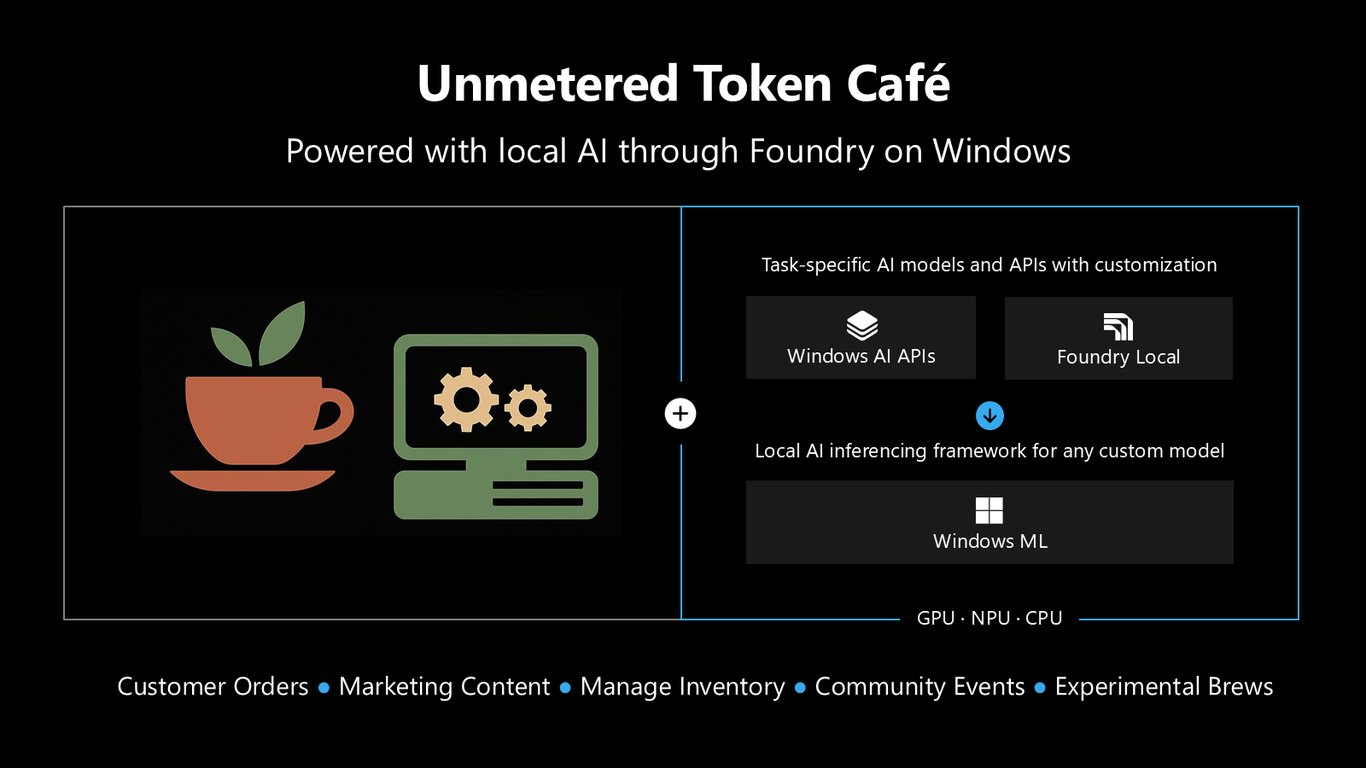
세 층으로 완성한 카페
결국 Unmetered Token Café의 모든 기능은 Foundry on Windows의 세 층 위에서 완성됐습니다. 턴키 API, Foundry Local, Windows ML — 필요에 맞는 층을 골라 쓰면 어떤 로컬 AI 앱이든 만들 수 있습니다.

시작하기와 자료
직접 시작해 보고 싶으시면 WinAppSDK, Aion, Foundry Local, Windows ML, Windows ML CLI, AI Dev Gallery, Foundry Toolkit 링크를 참고하세요. DEM345, TT635, BRK262 같은 다른 세션도 함께 보시길 권합니다.

감사합니다
세션 상세 페이지에서 튜토리얼과 코드로 바로 실습해 보실 수 있습니다. aka.ms/build/evals에서, 또는 QR 코드로 설문에 참여해 주세요. 감사합니다.