
오늘은 AI 코딩 어시스턴트의 추론 비용 이야기를 해보겠습니다. 핵심은 간단합니다. 모든 요청을 무조건 70B 클라우드 모델로 보내는 대신, Snapdragon X2 Elite에서 계층형 라우팅을 하면 품질을 그대로 유지하면서 클라우드 비용을 67%까지 줄일 수 있습니다.

45분 동안 다룰 내용
먼저 왜 클라우드 전용 추론이 구조적으로 비효율인지 짚고, Snapdragon X2 Elite NPU의 스펙이 LLM 추론에 실제로 무엇을 의미하는지 살펴본 다음, 온디바이스에서 클라우드로 이어지는 3계층 라우팅과 분류기 설계로 넘어가겠습니다. 뒷부분에서는 라이브 데모와 토큰 절감 데이터, 그리고 직접 만들어 볼 수 있는 GitHub 저장소와 배포 체크리스트까지 안내드리겠습니다.

이제 첫 번째 파트, 지금의 계산이 왜 잘못됐는지부터 들여다보겠습니다.

모든 요청을 똑같이 처리하는 문제
지금 대부분의 AI 어시스턴트는 docstring 한 줄을 추가하든, lint 오류를 고치든, 대규모 보안 감사든 전부 똑같이 70B 클라우드 모델로 보냅니다. 개발자 50명 기준 하루 3만 6천 달러, 24억 토큰이 나가는데, 이 요청의 73%는 사실 70B 모델이 전혀 필요 없는 단순 작업입니다.

대부분은 단순하다 — 클라우드는 과잉
실제 엔터프라이즈 개발 워크로드를 분석해 보면, 요청 대부분이 복잡도 점수 1에서 4 사이의 단순한 작업에 몰려 있습니다. 정말 복잡한 8에서 10점짜리 작업은 소수인데, 그 소수를 위해 모든 요청을 클라우드로 보내고 있는 셈이죠.

그럼 온디바이스 추론이 정말 현실적인지, Snapdragon X2 Elite 하드웨어부터 자세히 살펴보겠습니다.

온디바이스 LLM 추론을 가능케 하는 NPU
Qualcomm Hexagon NPU가 INT8 기준 80 TOPS를 냅니다. 이전 세대 대비 78% 빠른 수치죠. 여기에 최대 128GB LPDDR5x 메모리를 얹어서, 13B INT8 모델도 약 14GB면 들어가니 여유가 충분합니다. 7B INT8 모델 기준 초당 40에서 60 토큰, 즉 IDE에서 대화형으로 쓸 만한 속도가 나옵니다.

코드 생성에 맞는 양자화 선택
여기서 핵심 선택이 INT8 가중치에 INT16 활성화입니다. 가중치를 INT8로 줄이면 VRAM이 절반가량 절약되고, 코드 출력은 표현 공간이 좁아서 가중치 양자화를 잘 견딥니다. 대신 활성화는 INT16으로 정밀도를 지켜서 문법 정확성을 보장하죠. HumanEval과 MBPP 기준으로 복잡도 7점까지는 FP16 대비 품질 차이가 5% 미만입니다.

이제 오늘의 핵심인 3계층 아키텍처로 넘어가겠습니다.
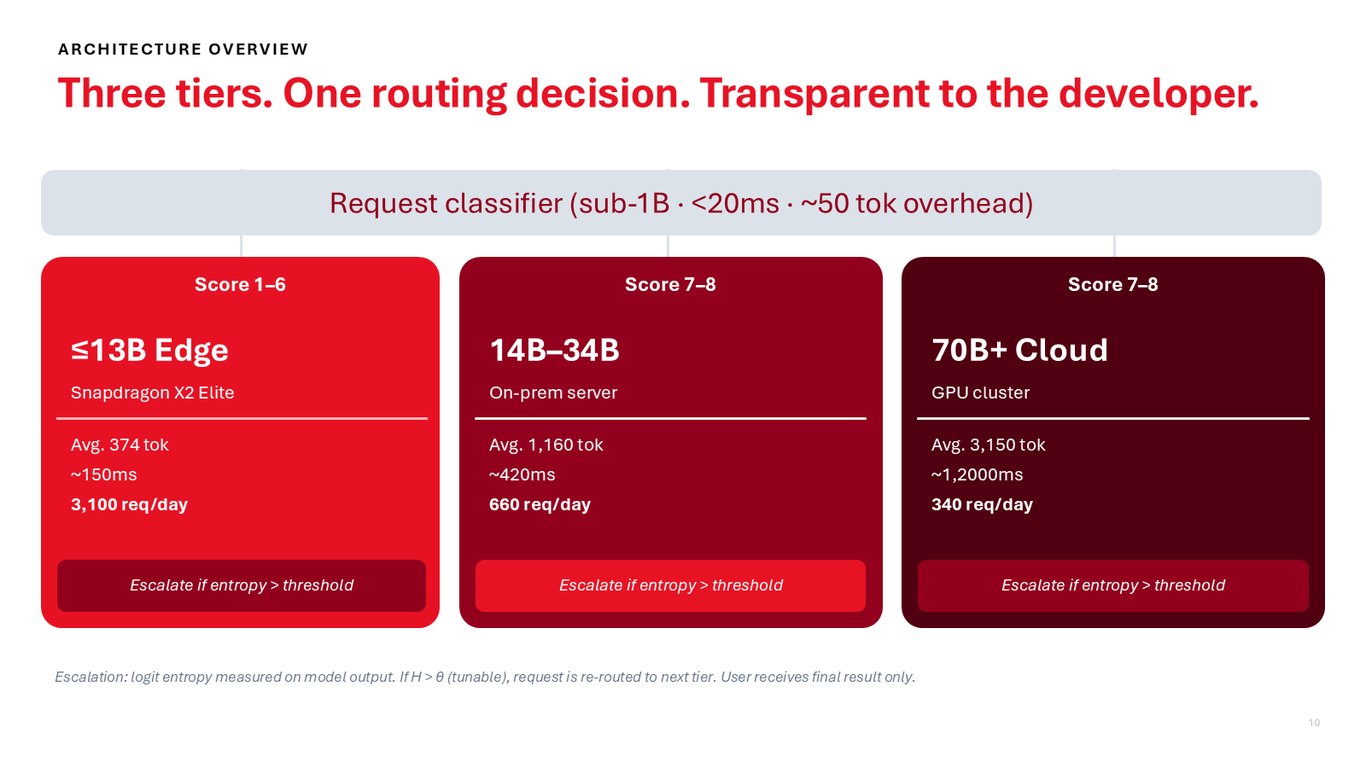
세 계층, 하나의 라우팅 결정
먼저 1B 미만의 경량 분류기가 20밀리초 안에 요청 복잡도를 채점합니다. 1에서 6점은 Snapdragon X2 Elite 엣지에서, 7에서 8점은 온프렘 서버에서, 그 이상은 클라우드 GPU 클러스터에서 처리하죠. 그리고 출력 엔트로피가 임계값을 넘으면 다음 계층으로 조용히 승격시켜서, 개발자는 최종 결과만 받아 봅니다.

라우팅 두뇌 — 네 가지 신호
분류기는 네 가지 신호를 봅니다. 토큰 수, AST 깊이, 파일 간 참조 수, 그리고 보안 키워드죠. 특히 CVE나 인증, 암호화 같은 보안 관련 단어가 하나라도 걸리면 다른 점수와 상관없이 곧바로 클라우드로 보냅니다. 여기에 다섯 번째 신호로 로짓 엔트로피를 두어서, 모델이 확신하지 못하면 사용자에게 돌려주기 전에 상위 계층으로 다시 라우팅합니다.

그럼 이 구조가 실제로 어떤 숫자를 만들어 내는지 데이터로 확인해 보겠습니다.
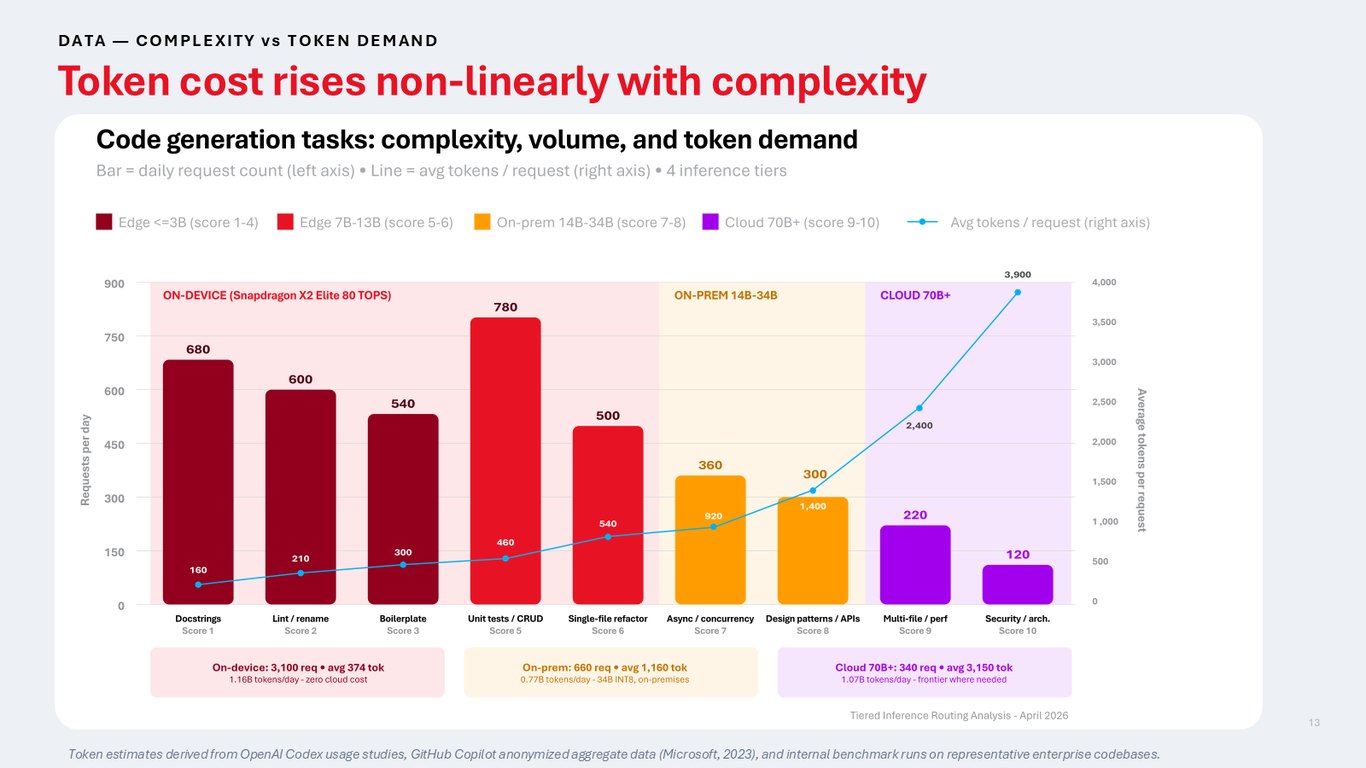
복잡도에 따라 비선형으로 오르는 토큰 비용
토큰 비용은 복잡도가 올라갈수록 선형이 아니라 훨씬 가파르게 증가합니다. 단순 작업은 몇백 토큰이면 끝나지만 복잡한 작업은 수천 토큰을 쓰죠. 그래서 단순 요청을 엣지로 걸러내는 것만으로도 비용에 큰 차이가 납니다.
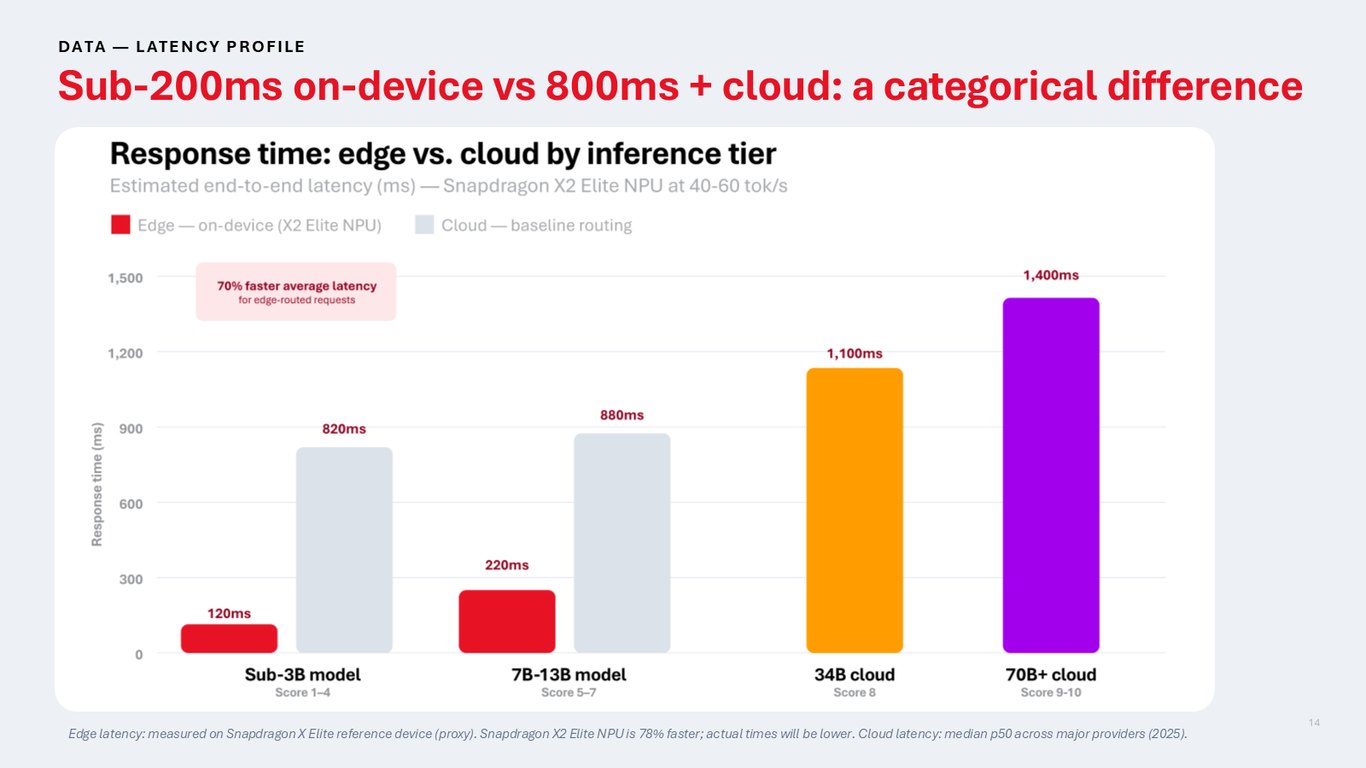
온디바이스 200ms vs 클라우드 800ms+
지연 시간을 보면 차이가 확연합니다. 온디바이스는 200밀리초 미만인데 클라우드는 800밀리초를 넘어가죠. 이건 단순히 조금 빠른 정도가 아니라 체감이 완전히 다른, 범주 자체가 다른 응답성입니다. 게다가 이 수치는 이전 세대 기기 기준이라 X2 Elite에서는 더 빨라집니다.
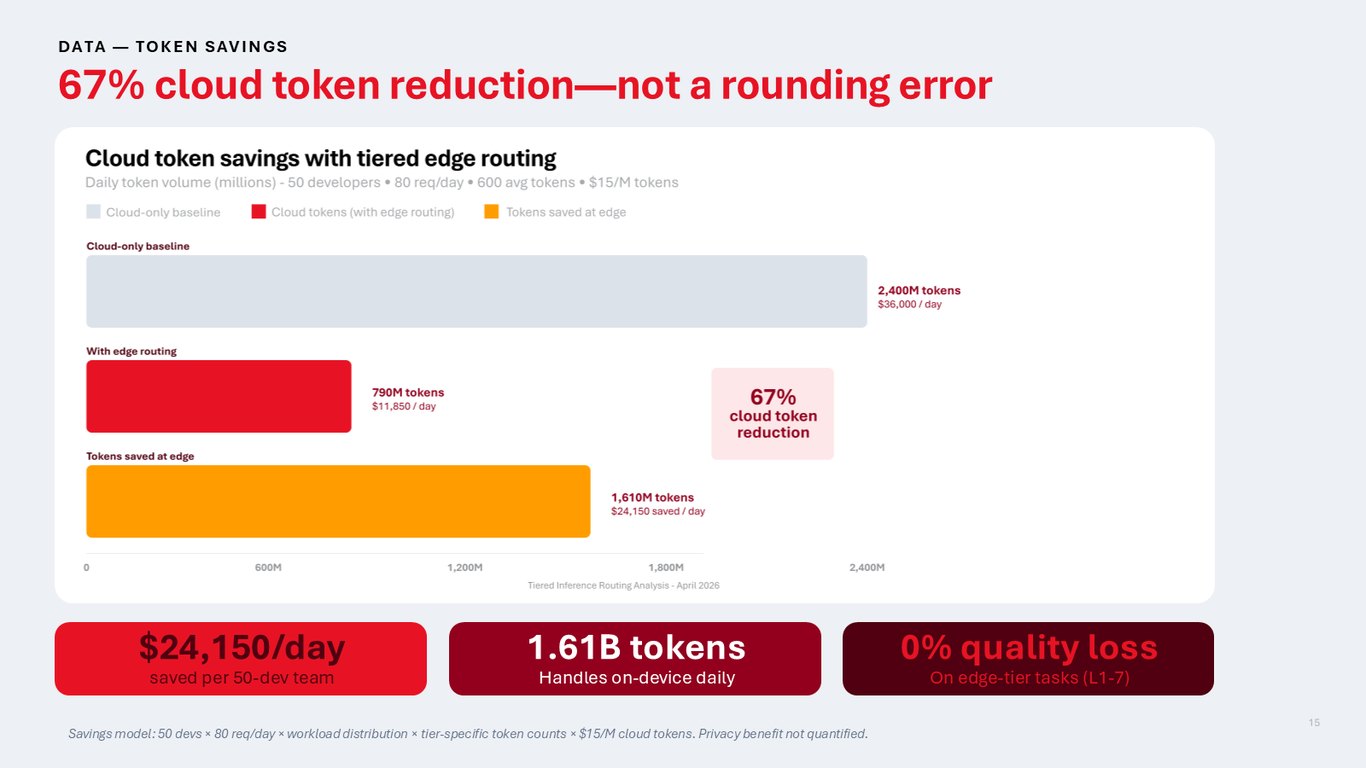
클라우드 토큰 67% 절감 — 반올림 오차가 아닙니다
결과적으로 개발자 50명 팀 기준 하루 2만 4,150달러를 아끼고, 16억 개 토큰을 온디바이스에서 처리합니다. 그러면서 엣지 계층 작업, 즉 복잡도 1에서 7까지의 작업에서는 품질 손실이 0%입니다. 67%라는 숫자는 반올림한 게 아니라 실제 절감폭입니다.
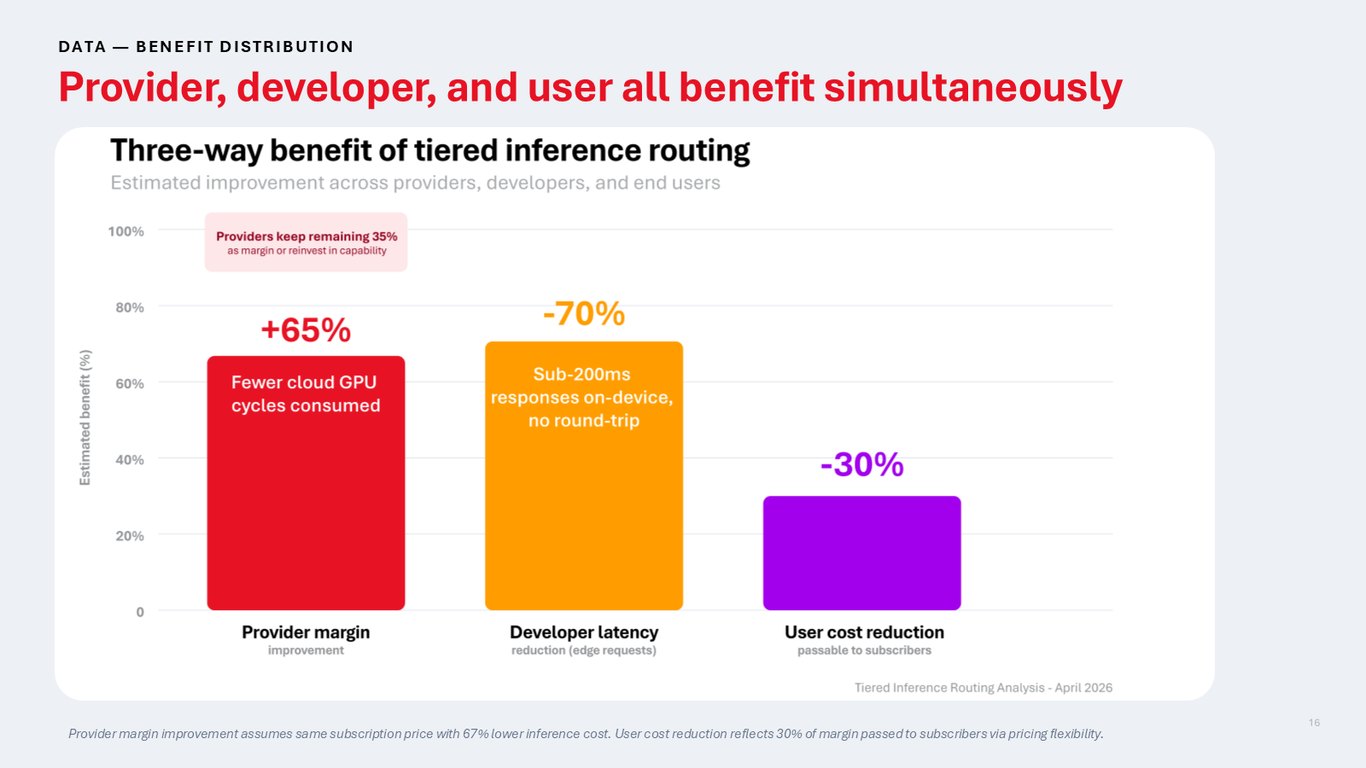
공급자·개발자·사용자 모두의 이득
이 절감은 어느 한쪽만의 이득이 아닙니다. 공급자는 같은 구독 가격에 추론 비용이 67% 낮아져 마진이 개선되고, 그 마진의 일부를 가격에 반영하면 사용자 비용도 내려갑니다. 세 주체가 동시에 이득을 보는 구조죠.

이제 이 설계를 뒷받침하는 연구 근거들을 짚어 보겠습니다.

아키텍처를 뒷받침하는 핵심 연구
양자화 쪽으로는 Dettmers의 LLM.int8(), Frantar의 GPTQ, Xiao의 SmoothQuant가 기반이 되고요. 코드 벤치마크는 HumanEval과 MBPP, EvalPlus를 썼습니다. 엣지 추론과 라우팅은 FlexGen, LLM in a Flash, 그리고 Qualcomm의 Snapdragon X2 Elite 아키텍처 문서를 참고했습니다. 전부 공개된 논문과 자료라 직접 확인하실 수 있습니다.

73% 엣지 처리 주장의 근거
엣지에서 73%를 처리할 수 있다는 주장은 여러 데이터로 뒷받침됩니다. GitHub Copilot 분석에서는 단일 함수 완성 같은 요청이 58에서 79%를 차지했고, Stack Overflow 설문에서도 68%가 문서화나 보일러플레이트 같은 단순 작업이었습니다. 물론 그린필드나 연구성 워크로드는 50에서 60%로 낮아질 수 있고, 반대로 자동완성 위주면 80%를 넘기도 합니다.

마지막으로, 여러분이 이걸 직접 만들어 볼 수 있도록 실행 방법을 안내드리겠습니다.
이번 주에 해볼 세 가지
이번 주에 세 가지만 해보시죠. 첫째, 스타터 저장소를 클론하세요. 분류기와 라우팅 로직, 7B·13B INT8 양자화 설정이 MIT 라이선스로 들어 있습니다. 둘째, 아키텍처 블루프린트를 내려받아 하드웨어 사이징 가이드를 확인하시고요. 셋째, 워크로드 프로파일러에 팀 요청 로그를 물려서 5분 안에 예상 엣지 처리율과 절감액을 받아 보세요.

더 빠른 칩이 아니라 새로운 기본 단위
Snapdragon X2 Elite는 단순히 더 빠른 칩이 아니라, AI 기반 개발을 위한 새로운 아키텍처 기본 단위입니다. docstring은 3B 모델로 보내고, 70B는 보안 감사에 아껴 쓰고, 그렇게 아낀 비용은 사용자에게 돌려주세요. 저장소와 블루프린트, 프로파일러 링크 남겨 두겠습니다. 감사합니다.