
오늘은 Microsoft Foundry 위에서 파운데이션 모델을 실제 프로덕션 AI로 바꾸는 이야기를 해보겠습니다. 모델을 고르는 데서 끝나는 게 아니라, 어떻게 서비스로 돌리느냐가 핵심이죠.

더 빠른 추론, 더 많은 모델
더 빠른 추론, 더 많은 모델, 그리고 이제 막 시작한 학습 스토리까지 준비했습니다. 앞으로 보여드릴 게 훨씬 더 많다는 점을 먼저 말씀드리고 싶어요.

AI의 세 가지 진실
지금 AI에는 세 가지 분명한 흐름이 있습니다. 오픈 모델은 이미 프로덕션에 쓸 수 있는 수준이고, 차별화는 그 모델을 어떻게 커스터마이즈하고 개선하느냐에서 나옵니다. 그래서 스택도 단순히 모델을 서빙하는 단계에서, 계속 개선하는 단계로 넘어가고 있죠.
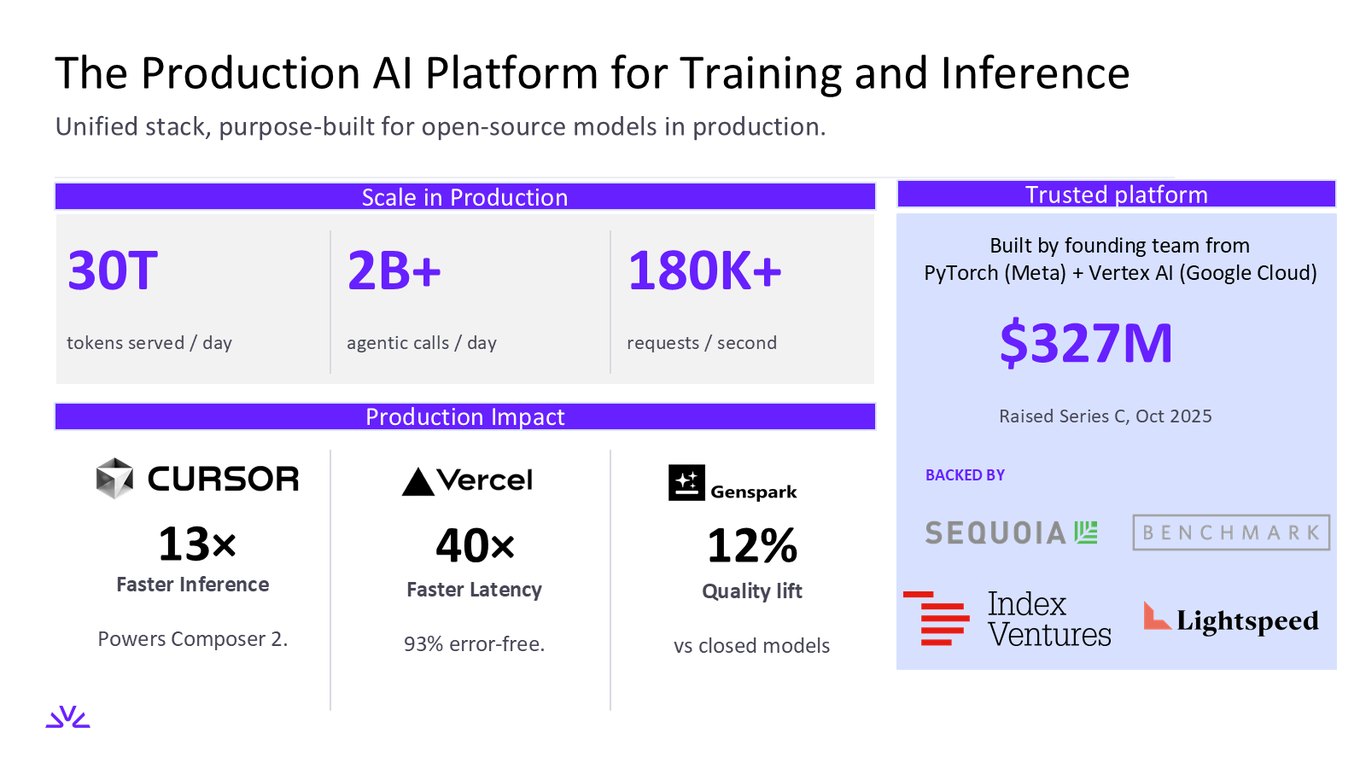
학습과 추론을 위한 통합 플랫폼
이건 오픈소스 모델을 프로덕션에서 돌리기 위해 처음부터 하나로 설계한 스택입니다. 하루 30조 토큰, 초당 18만 건 이상을 처리하고, 추론은 13배 빠르고 지연은 40배 개선되며 폐쇄형 모델 대비 품질은 12% 높아집니다. PyTorch와 Vertex AI를 만든 창립팀이 만든, 신뢰할 수 있는 플랫폼이라는 점도 강조하고 싶습니다.
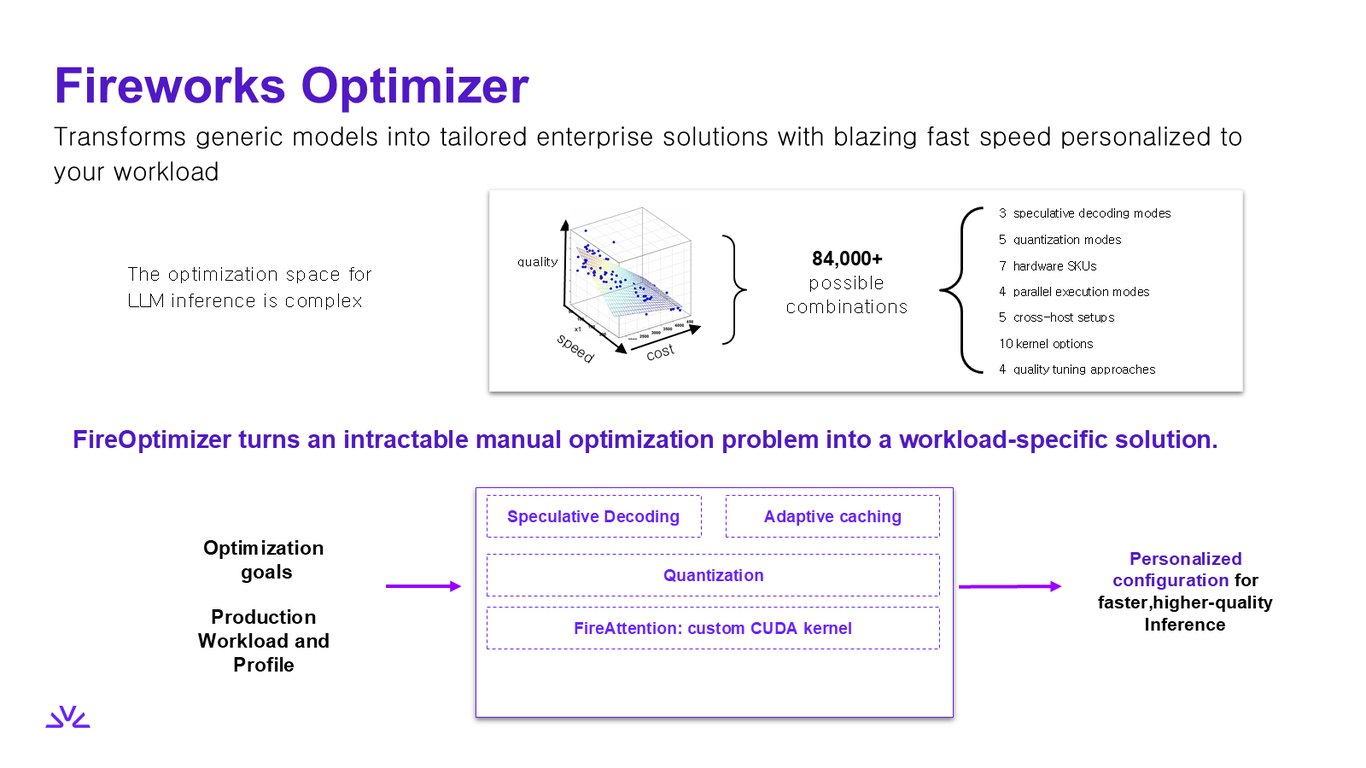
FireOptimizer, 워크로드 맞춤 최적화
LLM 추론 최적화는 8만 4천 가지가 넘는 조합이 얽힌 굉장히 복잡한 문제입니다. FireOptimizer는 이 손댈 수 없는 수동 튜닝을, speculative decoding·quantization·FireAttention 커스텀 CUDA 커널까지 묶어서 여러분 워크로드에 딱 맞는 설정으로 자동으로 풀어냅니다. 더 빠르고 더 높은 품질의 추론을 개인화해 주는 거죠.

내 데이터로 소유하는 AI
서빙하던 바로 그 플랫폼 위에서 세 단계로 학습할 수 있습니다. 데이터와 설명만 주면 되는 Training Agent, ML 엔지니어를 위한 Managed Training, 그리고 학습 루프와 손실 함수까지 직접 제어하는 Training API까지요. 어디서 시작하든 필요에 맞게 확장하면 됩니다.
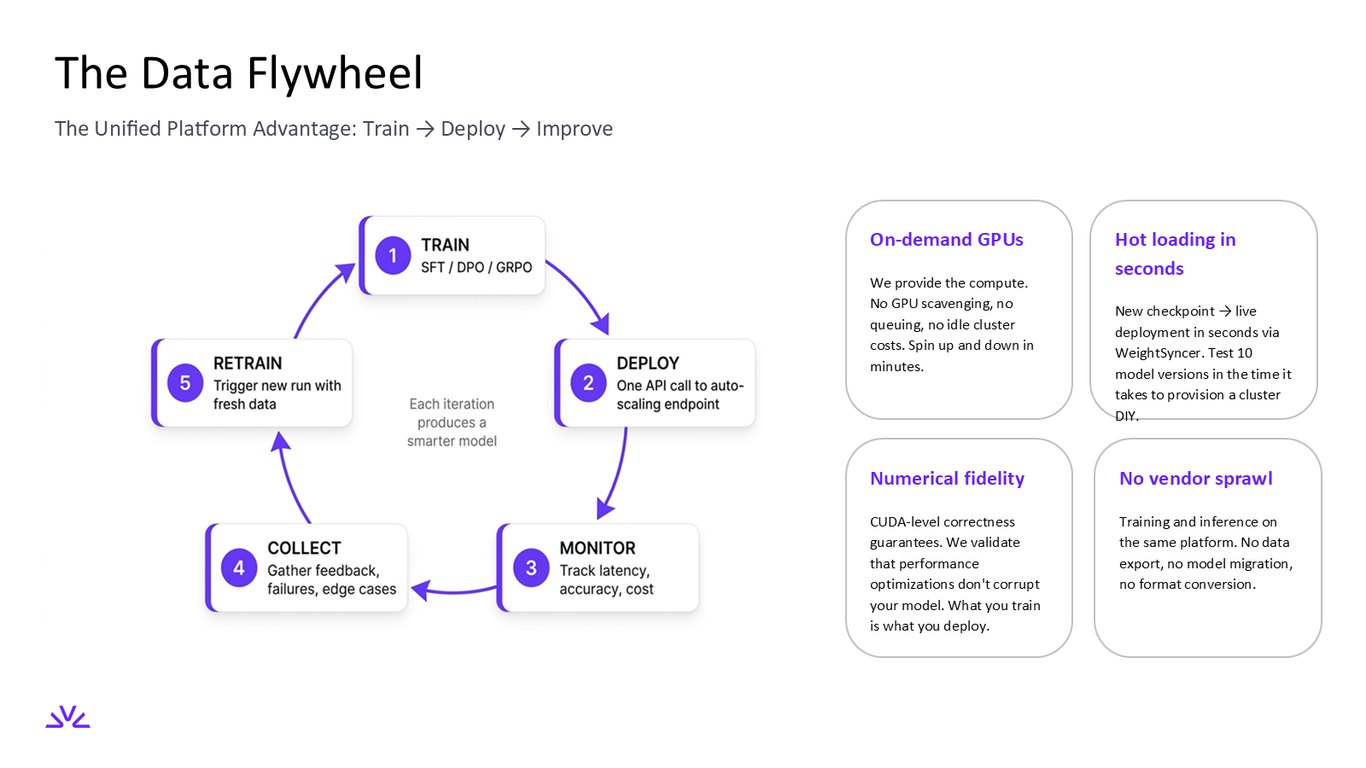
데이터 플라이휠
통합 플랫폼의 진짜 강점은 학습, 배포, 개선이 하나로 돈다는 데 있습니다. GPU는 필요할 때 몇 분 만에 띄우고, CUDA 레벨 정확성으로 학습한 그대로 배포되며, 새 체크포인트는 WeightSyncer로 몇 초 만에 라이브에 올라갑니다. 데이터 내보내기나 포맷 변환 없이 학습과 추론을 같은 곳에서 하니까 벤더가 흩어질 일도 없죠.
Lin과 Yina, 영상 인터루드
잠깐 Lin과 Yina의 짧은 영상으로 분위기를 바꿔보겠습니다. 지금까지의 이야기가 실제로 어떻게 이어지는지 편하게 보시죠.

자, 이제 실제로 지금 출시되는 것들을 살펴보겠습니다. 여기서부터는 데모로 직접 보여드릴게요.

카탈로그에서 프로덕션까지, 한 호흡에
Foundry와 Fireworks를 함께 쓰면 카탈로그에서 모델을 고르고 프로덕션까지 가는 걸 정말 한 호흡에 끝낼 수 있습니다. 지금 그 과정을 바로 보여드리겠습니다.
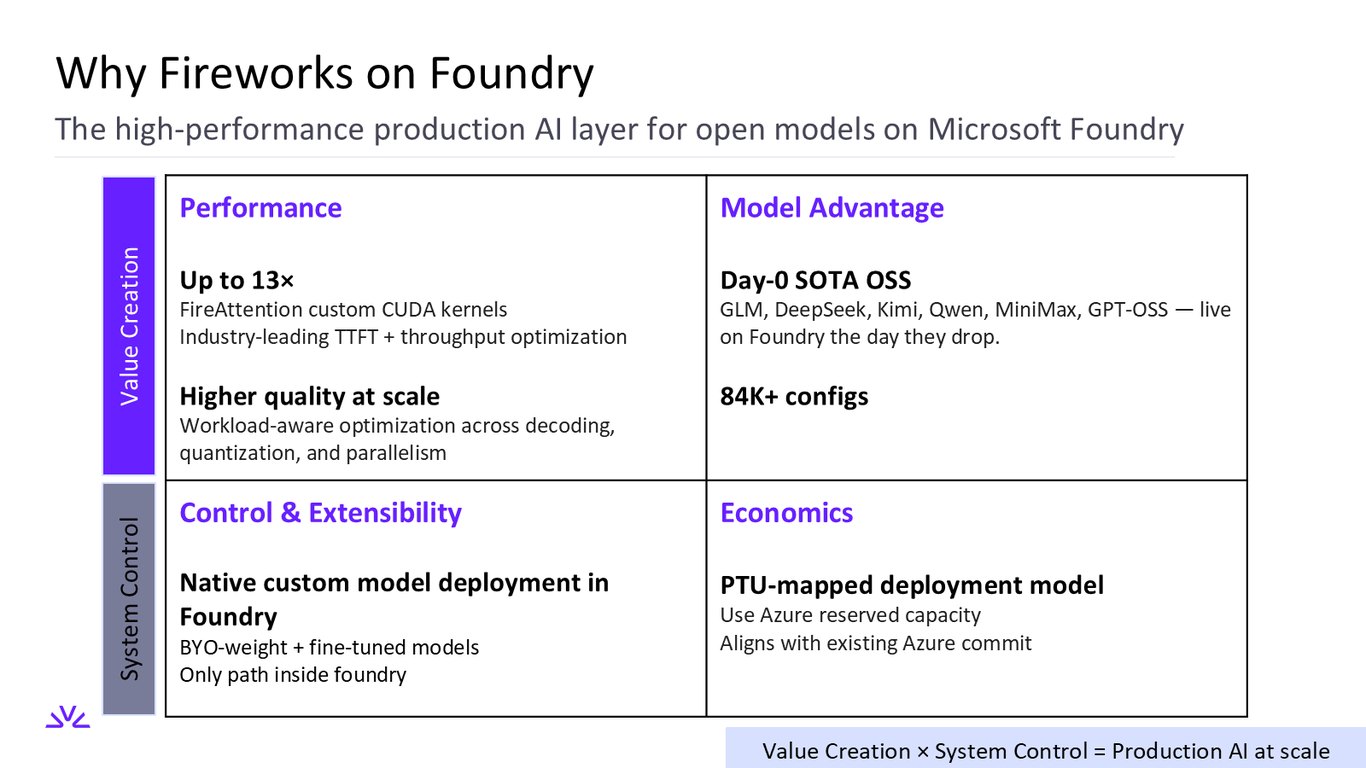
왜 Foundry 위의 Fireworks인가
Fireworks는 Microsoft Foundry 위에서 오픈 모델을 위한 고성능 프로덕션 AI 레이어 역할을 합니다. 최대 13배의 FireAttention 커널 성능, GLM·DeepSeek·Kimi·Qwen 같은 최신 오픈소스 모델의 Day-0 지원, Foundry 안에서만 가능한 커스텀 모델 배포, 그리고 PTU 매핑으로 기존 Azure 약정을 그대로 활용하는 경제성까지 갖췄습니다.

배포 모드와 통합 아키텍처
워크로드에 따라 유연하게 고르시면 됩니다. 서버리스 PayGo, 프로비저닝된 PTU와 Global PTU, 그리고 직접 가중치를 가져오는 BYOW·커스텀까지, 어떤 상황에도 맞는 추론 배포 방식을 제공합니다.
데모
먼저 첫 번째 데모를 보시죠. 방금 말씀드린 배포 방식이 실제로 어떻게 동작하는지 화면으로 확인해 보겠습니다.
두 번째 데모
이어서 두 번째 데모입니다. 여기서는 조금 더 실전에 가까운 시나리오를 보여드리겠습니다.

파인튜닝 모델과 Azure Agents
여러분이 파인튜닝한 모델을 Azure Agents와 붙이면 정말 잘 맞습니다. 직접 개선한 모델을 에이전트 워크플로에 자연스럽게 태워서 쓸 수 있다는 뜻이죠.

Perplexity의 현장 이야기
이번엔 Perplexity가 스케일링 최전선에서 겪은, 대본 없는 진짜 이야기를 들어보겠습니다. 실제 규모로 밀어붙일 때 무슨 일이 벌어지는지 생생하게 들으실 수 있을 거예요.
이제 오늘 이야기를 정리해 보겠습니다. 결국 핵심은 오픈 모델을 골라 쓰는 걸 넘어, 내 데이터로 계속 개선하며 프로덕션에서 소유하는 것이라는 점입니다.
이제 시작해 볼까요
Fireworks AI on Microsoft Foundry는 지금 바로 쓰실 수 있습니다. Kimi, DeepSeek, Qwen 같은 최고의 오픈소스 모델을 Azure Foundry에서 가장 빠른 추론으로 돌리고, 여러분의 데이터로 학습해 체크포인트를 몇 초 만에 올려 빠르게 반복하세요. 기존 Azure 구독만 있으면 별도 계정이나 추가 설정 없이 시작할 수 있습니다.

더 알아보기
세션 상세 페이지에서 튜토리얼과 리소스, 코드까지 바로 실행에 옮겨보세요. aka.ms/build/evals를 방문하거나 QR 코드를 스캔해서 세션 설문에도 참여해 주시면 감사하겠습니다.