
오늘은 에이전트 AI를 디바이스 안에서 돌리는 것부터 클라우드에서 대규모로 오케스트레이션하는 것까지, 그 전체 스펙트럼을 함께 살펴보겠습니다. 세션 코드는 BRKSP92입니다.

오늘 다룰 내용
먼저 온디바이스 에이전트 워크플로를 소개하고, 실제 온클라이언트 AI 데모를 보여드린 뒤, 그래픽 VRAM을 활용한 Stackable AI로 넘어갑니다. 그다음 Azure에서 Intel Xeon으로 엔터프라이즈 에이전트 AI를 확장하는 방법과 핵심 요점, 그리고 Q&A 순으로 진행하겠습니다.

이제 PC 위에서 직접 도는 인터랙티브 AI 에이전트를 보여드리겠습니다. Microsoft의 Karthik Vijayan, 그리고 Intel의 Jayneel Vora가 함께 진행합니다.
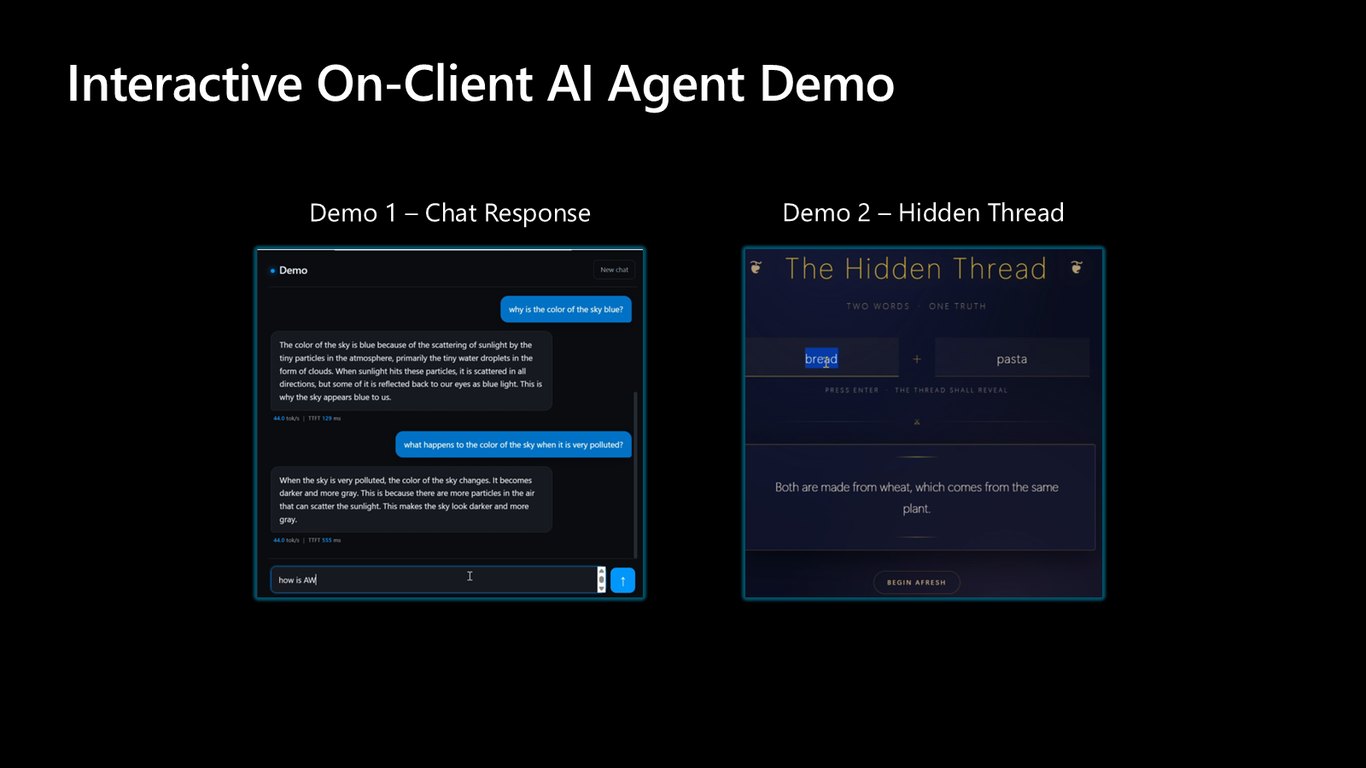
데모: 채팅 응답과 히든 스레드
첫 번째 데모에서는 에이전트가 실시간으로 채팅에 응답하는 모습을, 두 번째 데모에서는 백그라운드에서 돌아가는 Hidden Thread를 보여드립니다. 클라우드에 보내지 않고도 클라이언트에서 이만큼 처리된다는 점에 주목해 주세요.

이번에는 그래픽 VRAM을 활용해 판을 바꾸는 Stackable AI를 살펴보겠습니다. Intel Desktop Design의 Colin Helms가 이야기해 주시겠습니다.

VRAM 풀링으로 더 큰 LLM 돌리기
큰 LLM을 올리려면 결국 VRAM이 필요한데요, Intel 그래픽 드라이버는 시스템 RAM의 최대 93%까지 VRAM으로 잡을 수 있습니다. 여기에 Thunderbolt 4/5나 10GbE 같은 고속 인터커넥트로 여러 시스템의 VRAM을 하나로 풀링하면, Windows 11에서 Llama.cpp와 RPC를 통해 Qwen3-Next-Instruct 80B, GPT-OSS 120B 같은 대형 모델을 초당 8~16 토큰 수준으로 돌릴 수 있습니다.

이제 무대를 클라우드로 옮겨서, Azure 위에서 Intel Xeon 프로세서로 에이전트 AI를 돌리는 이야기를 하겠습니다. Intel AI Solutions Architect인 Sheik Mohamed Imran이 함께합니다.

컨텍스트에 굶주린 에이전트, Xeon과 AMX
에이전트 시스템은 컨텍스트를 많이 먹습니다. 128K에 달하는 컨텍스트는 기존 챗봇의 1~2K 한계를 훌쩍 넘죠. 여기서 컴팩트한 MoE 모델과 AMX를 갖춘 Intel Xeon이 자연스러운 짝이 됩니다. vLLM, SGLang, OpenVINO 같은 서빙 프레임워크가 Xeon에 최적화되어 있어서, GPT-OSS나 Qwen 시리즈 MoE를 클라우드에서 비용 효율적으로 배포할 수 있습니다.

여기까지 듣고 궁금하셨던 점들, 지금 편하게 질문해 주세요.

세션 리소스와 설문
세션 상세 페이지에서 튜토리얼과 코드, 리소스를 바로 받아보실 수 있고요, aka.ms/build/evals에 접속하거나 QR 코드를 스캔해서 설문에 참여해 주시면 큰 도움이 됩니다.

온디바이스부터 클라우드 오케스트레이션까지, 에이전트 AI를 확장하는 여정을 함께해 주셔서 감사합니다.